Quick BI的复杂系统为例:那些年,我们一起做过的性能优化
背景
一直以来,性能都是技术层面不可避开的话题,尤其在中大型复杂项目中。犹如汽车整车性能,追求极速的同时,还要保障舒适性和实用性,而在汽车制造的每个环节、零件整合情况、发动机调校等等,都会最终影响用户体感以及商业达成,如下图性能对收益的影响。

性能优化是一个体系化、整体性的事情,印刻在项目开发环节的各个细节中,也是体现技术深度的大的战场。下面我将以Quick BI的复杂系统为背景,深扒整个性能优化的思路和手段,以及体系化的思考。
如何定位性能问题?
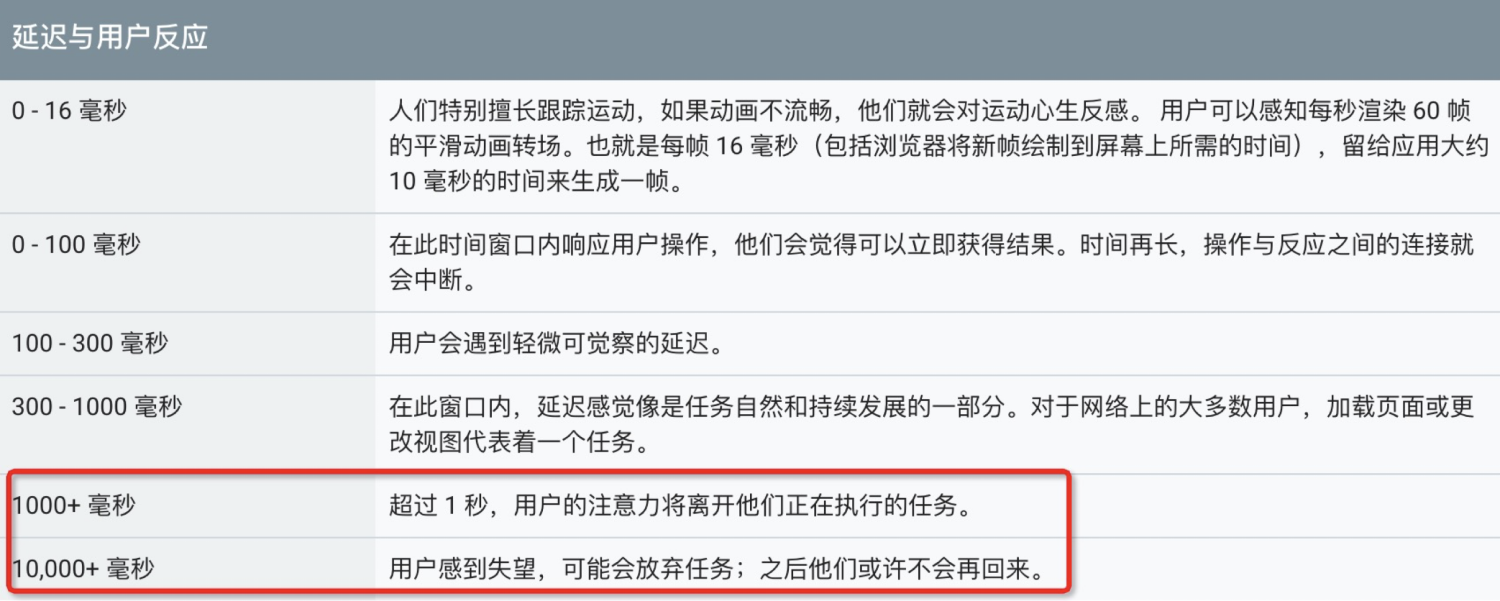
通常来讲,我们对动画的帧率是比较敏感的(16ms内),但如果出现性能问题,我们的实际体感可能就一个字:“慢”,但这并不能为我们解决问题提供任何帮助,由此我们需要剖析这个字背后的整条链路。
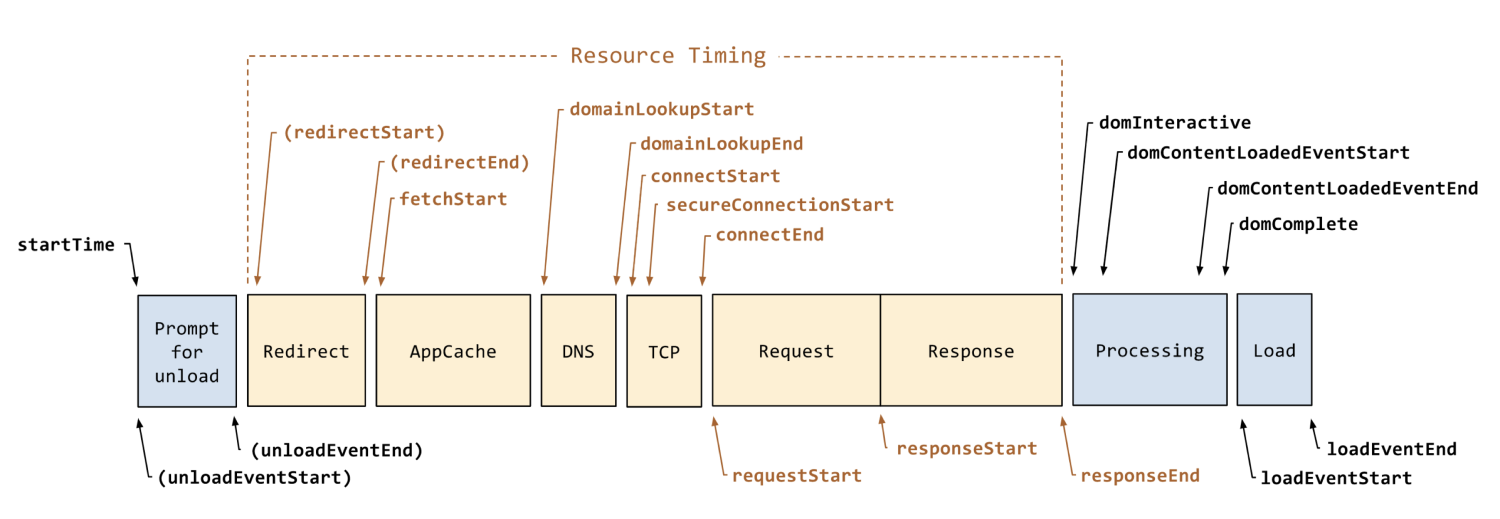
上图是浏览器通用的处理流程,结合我们的场景,我这里抽象成以下几个步骤:
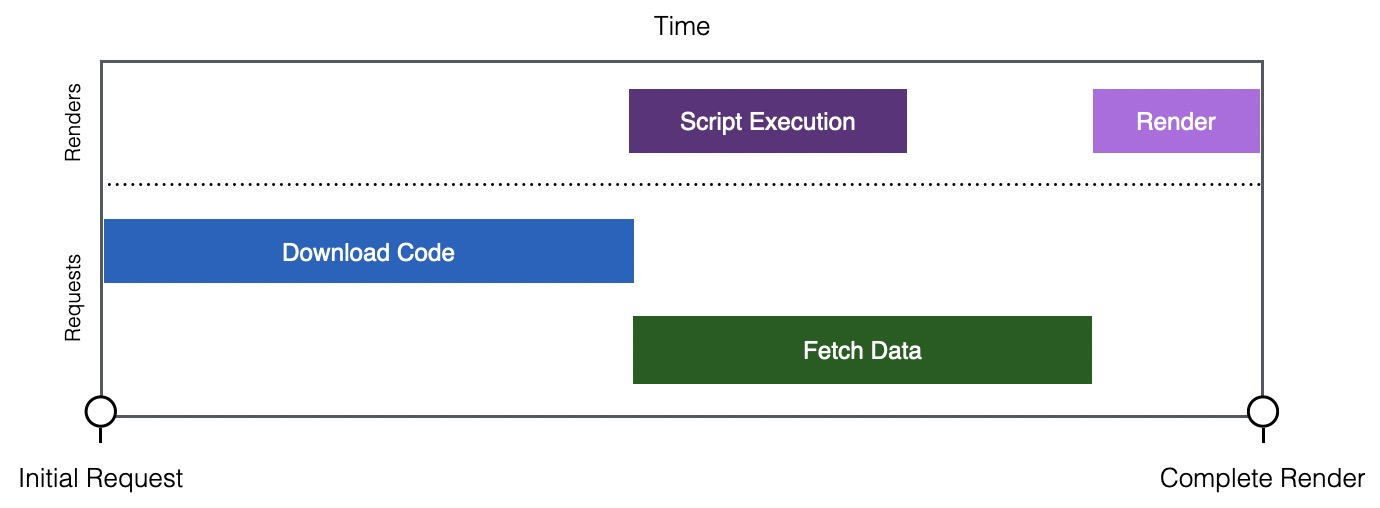
可以看出,主要的耗时阶段分为两个:
阶段一:资源包下载(Download Code)
阶段二:执行 & 取数(Script Execution & Fetch Data)
如何深入这两个阶段,我们一般会用以下几个主要的工具来分析:
Network
首先我们要使用的一个工具是Chrome的Network,它能帮助我们初步定位瓶颈所在的环节:
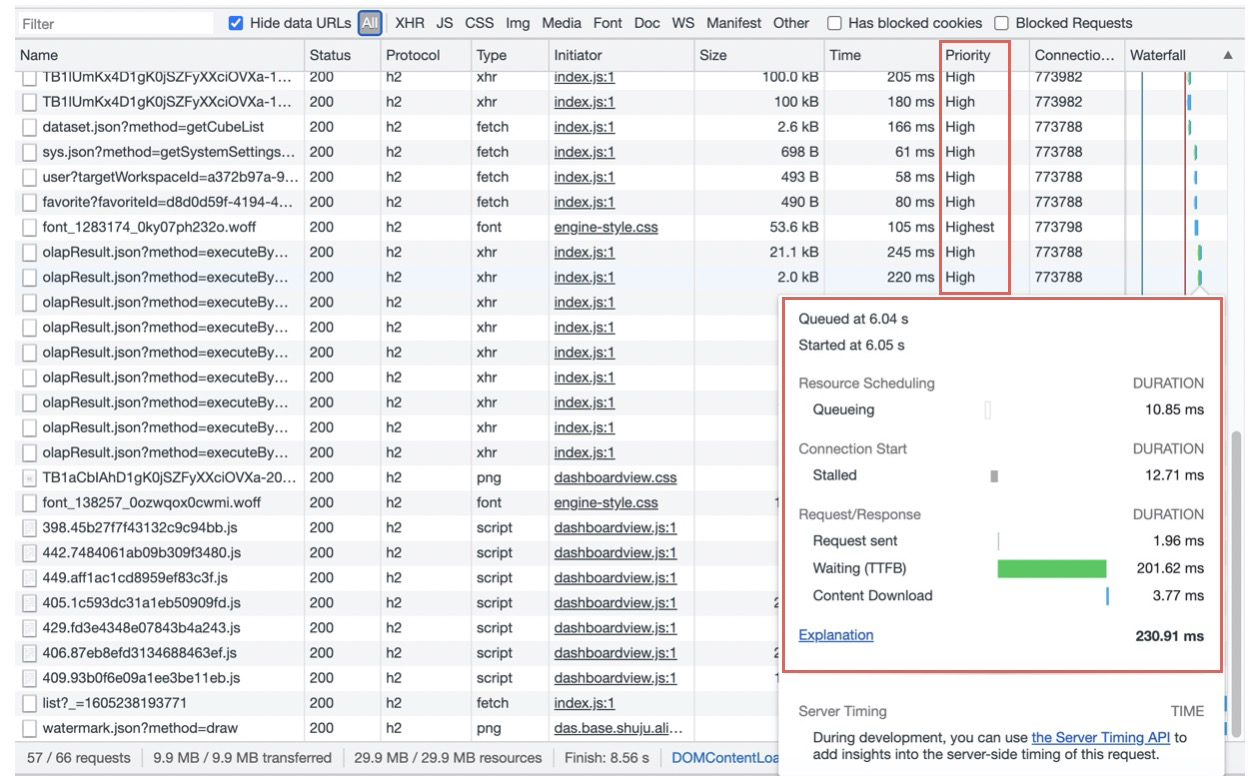
如图示例,在Network中可以一目了然看到整个页面的:加载时间(Finish)、加载资源大小、请求数量、每个请求耗时及耗时点、资源优先级等等。上面示例可以很明显看出:整个页面加载的资源很大,接近了30MB。
Coverage(代码覆盖率)
对于复杂的前端工程,其工程构建的产物一般会存在冗余甚至未被使用的情况,这些无效加载的代码可以通过Coverage工具来实时分析:
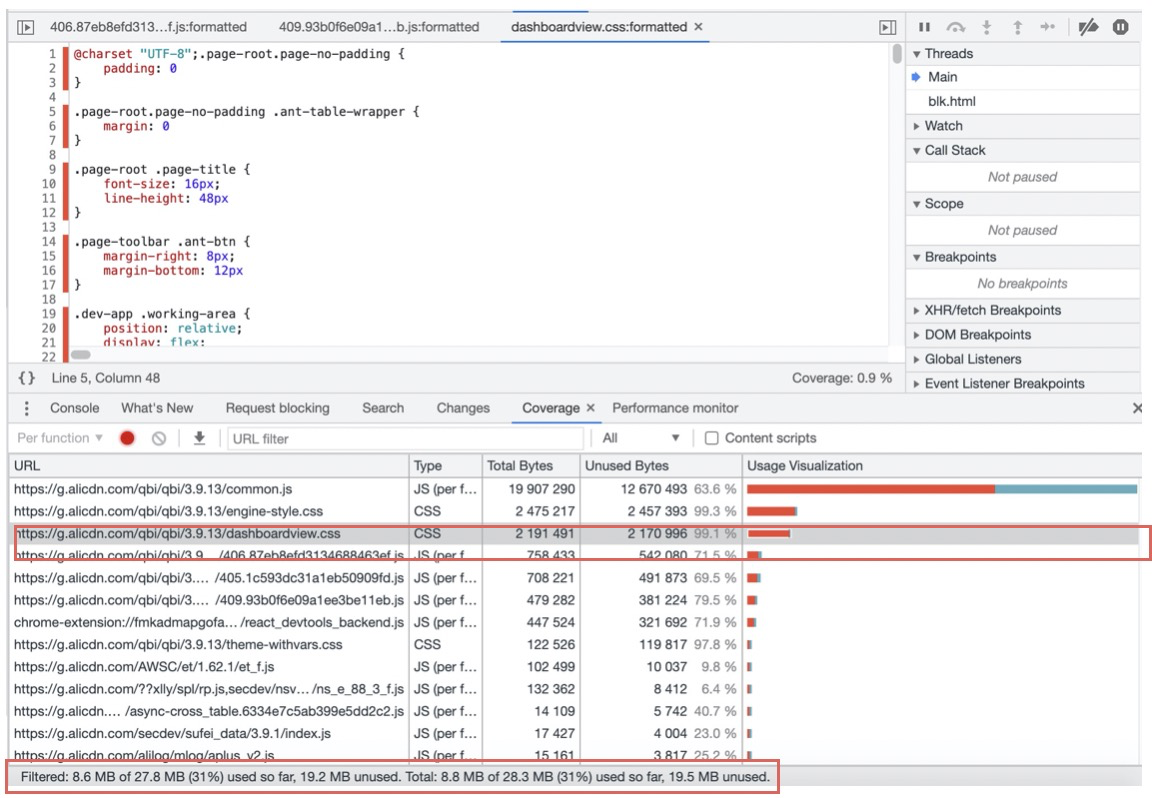
如上图示例可以看到:整个页面28.3MB,其中19.5MB都未被使用(执行),其中engine-style.css文件的使用率只有不到0.7%
资源大图
刚才我们已经知道前端资源的利用率非常低,那么具体是哪些无效代码被引入进来了?这时候我们要借助webpack-bundle-analyzer来分析整个的构建产物(产物stats可以通过webpack --profile --json=stats.json输出):
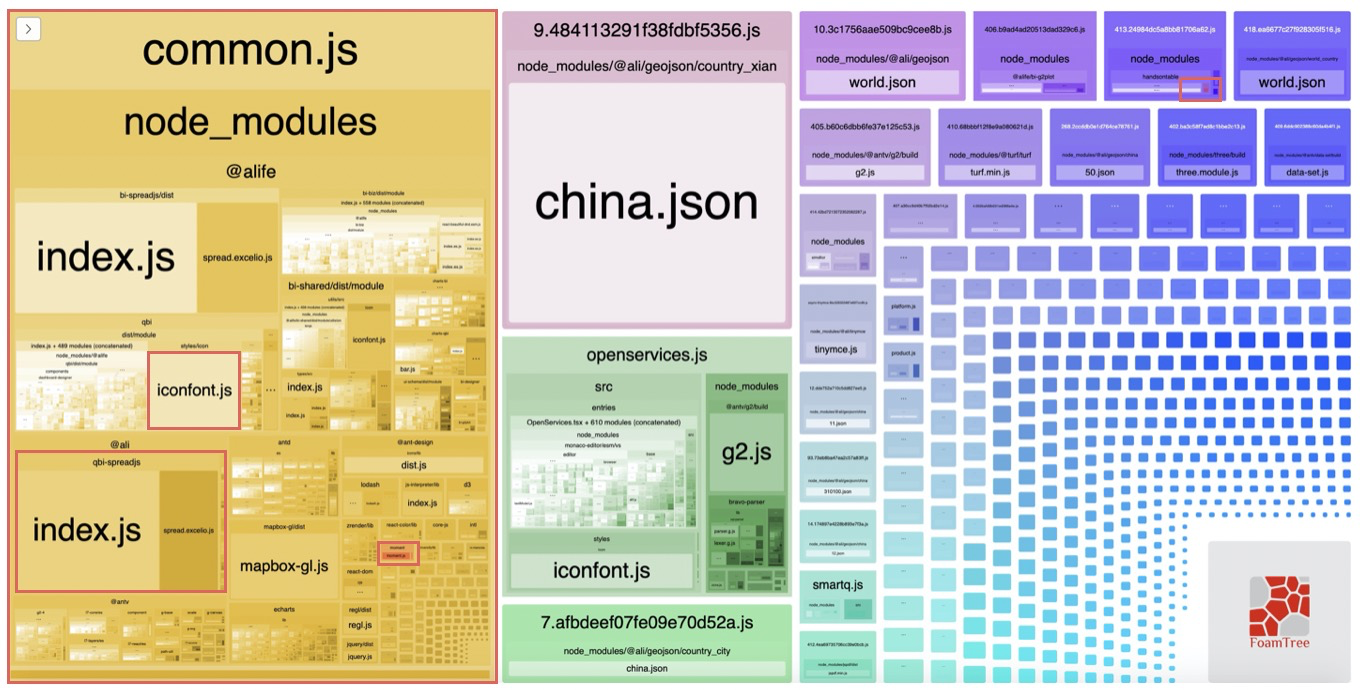
如上例,结合我们当前业务可以看到构建产物的问题:
第一,初始包过大(common.js)
第二,存在多个重复包(momentjs等)
第三,依赖的第三方包体积过大
模块依赖关系
有了资源构建大图,我们也大概知道了可优化的点,但在一个系统中,成百上千的模块一般都是通过互相引用的方式组织在一起,打包工具再通过依赖关系将其构建在一起(比如打成common.js单个文件),想要直接移除掉某个模块代码或依赖可能并非易事,由此我们可能需要一定程度抽丝剥茧,借助工具理清系统中模块的依赖关系,再通过调整依赖或加载方式来作优化:
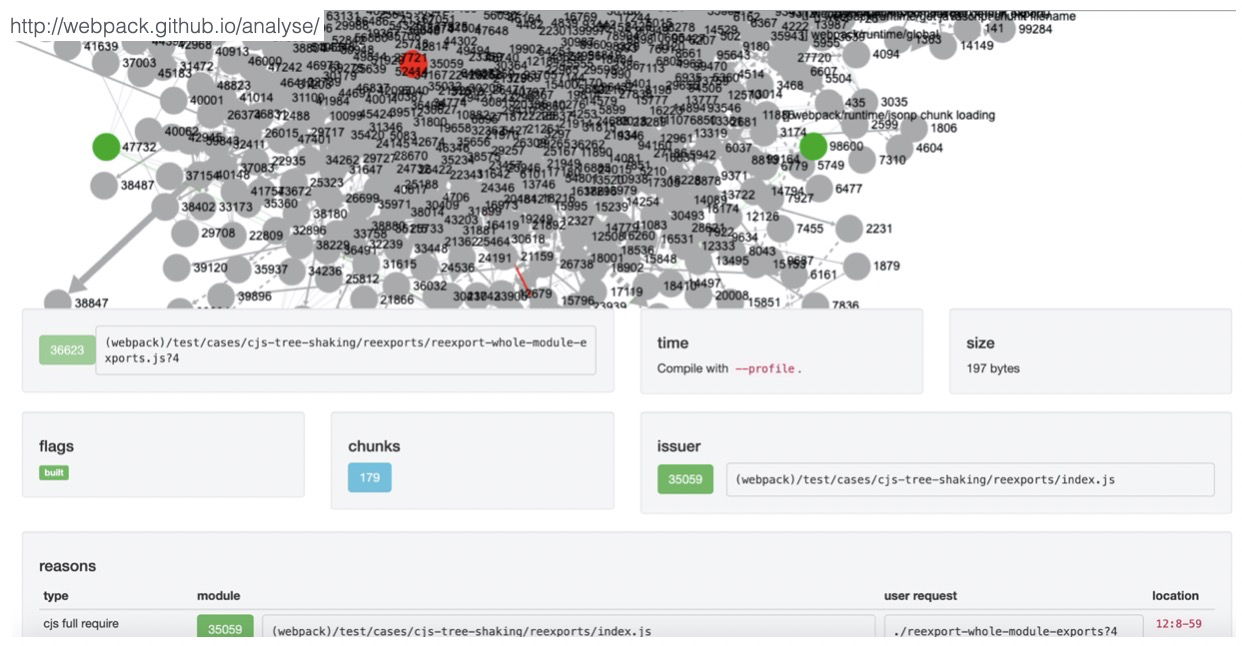
上图我们使用到的是webpack官方的analyse工具(其他工具还有:webpack-xray,Madge),只需要将资源大图stats.json上传即可得到整个依赖关系大图
Performance
前面讲到的都是和资源加载相关的工具,那么在分析 “执行 & 取数” 环节我们使用什么,Chrome提供了非常强大的工具:Performance:
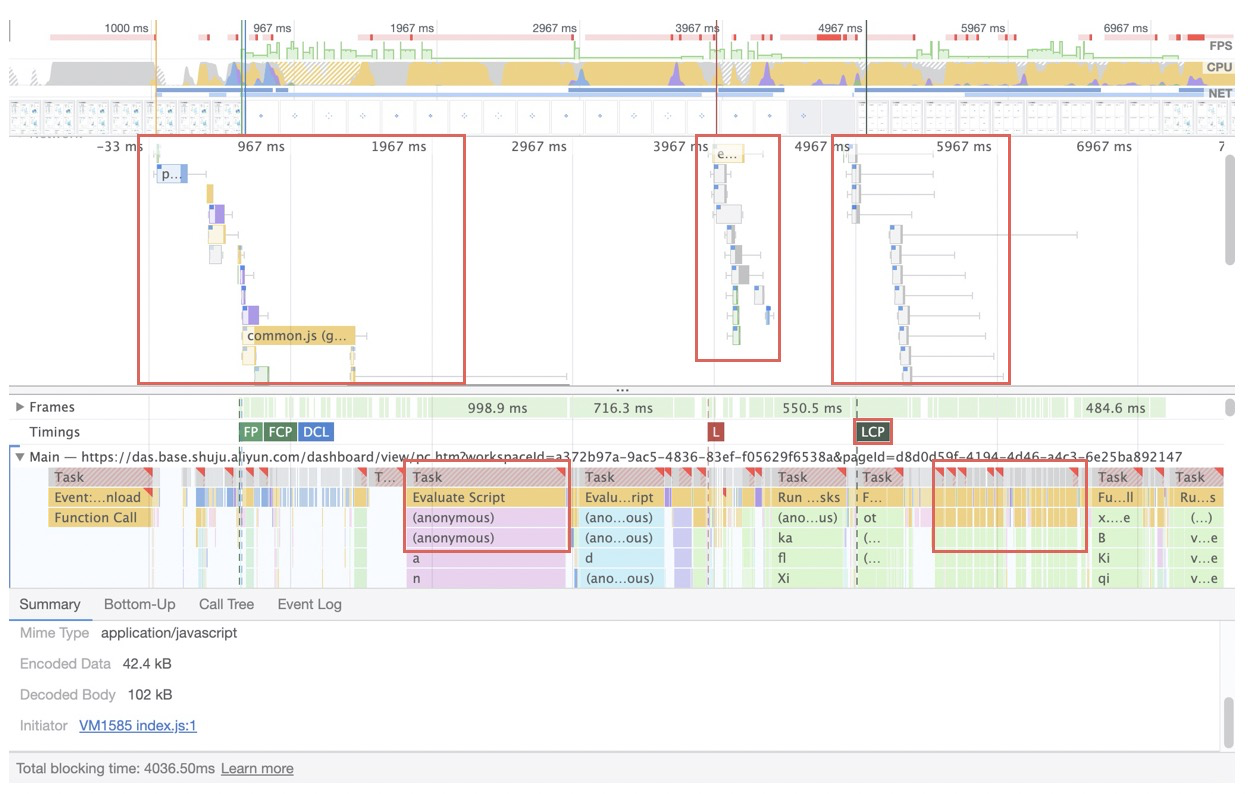
如上图示例,我们可以至少发现几个点:主流程串化、长任务、高频任务。
如何优化性能?
结合刚才提到的分析工具,刚才提到的 “资源包下载”、“执行 & 取数” 两个大的阶段我们基本上已经覆盖到,其根本问题和解法也在不断的分析中逐步有了思路,这里我将结合我们这里的场景,给出一些不错的优化思路和效果
大包按需加载
要知道,前端工程构建打包(如webpack)一般是从entry出发,去寻找整棵依赖树(直接依赖),从而根据这棵树产出多个js和css文件bundle或trunk,而一个模块一旦出现在依赖树中,那么当页面加载entry的时候,同时也会加载该模块。
所以我们的思路是打破这种直接依赖,针对末端的模块改用异步依赖方式,如下:

将同步的import { Marker } from '@antv/l7'改为异步,这样在构建时,被依赖的Marker会形成一个chunk,仅在此段代码执行时(按需),该thunk才被加载,从而减少了首屏包的体积。
然而上面方案会存在一个问题,构建会将整个@antv/l7作为一个chunk,而非Marker部分代码,导致该chunk的TreeShaking失效,体积很大。我们可以使用构建分片方式解决:

如上,先创建Marker的分片文件,使之具备TreeShaking的能力,再在此基础上作异步引入。
下方是我们优化后的流程对比结果:
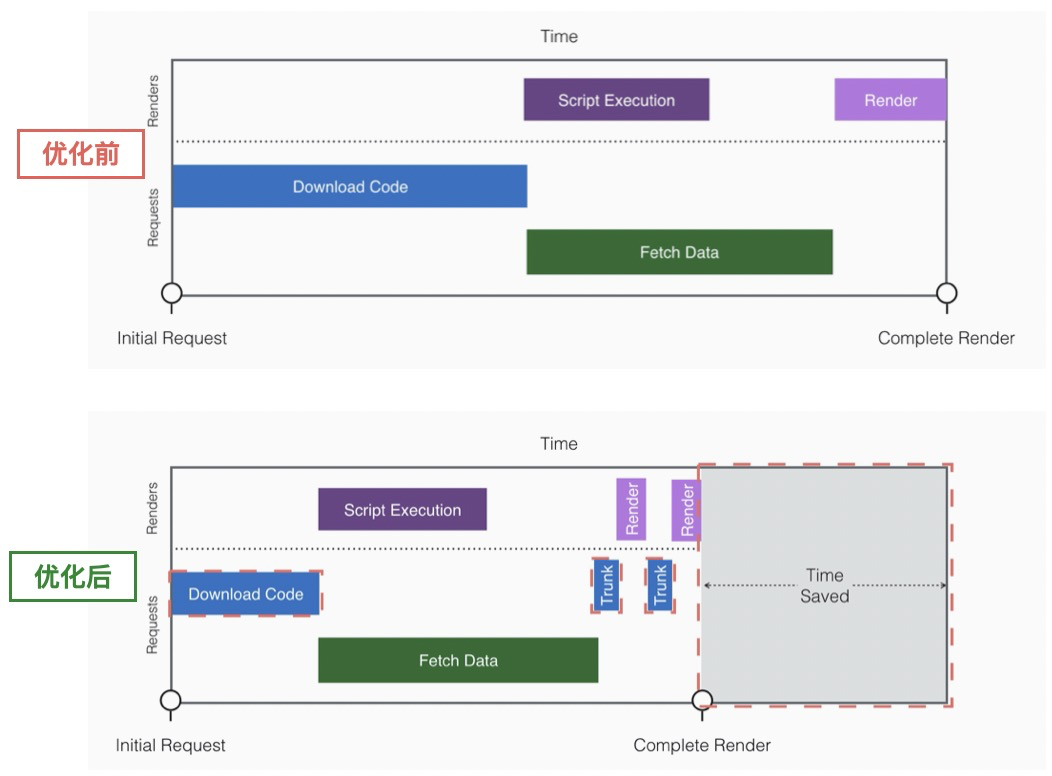
这一步,我们通过按需拆包,异步加载,节省了资源下载时间和部分执行时间
资源预加载
其实我们在分析阶段已经发现一个“主流程串化”的问题,js的执行是单线程,但浏览器实际上是多线程运行的,这里面就包括异步请求(fetch等),所以我们进一步的思路是把取数(Fetch Data)与资源下载通过多线程并行。
按照当前现状,接口取数的逻辑一般是耦合在业务逻辑或数据处理逻辑中的,所以解耦(与UI、业务模块等解耦)的步骤必不可少,将纯粹的fetch请求(及少量处理逻辑)剥离出来,放到优先级更高的阶段来发起请求。那么放到什么地方呢?我们知道,浏览器对资源的处理是有优先级的,正常按如下顺序:
- HTML/CSS/FONT
- Preload/SCRIPT/XHR
- Image/Audio/Video
- Prefetch
要做到资源拉取 和 发起取数并行,就有必要把取数提前到第1优先级(HTML解析完毕后立即执行,而非等待SCRIPT标签资源加载执行过程中发起请求),我们的流程会变成如下:
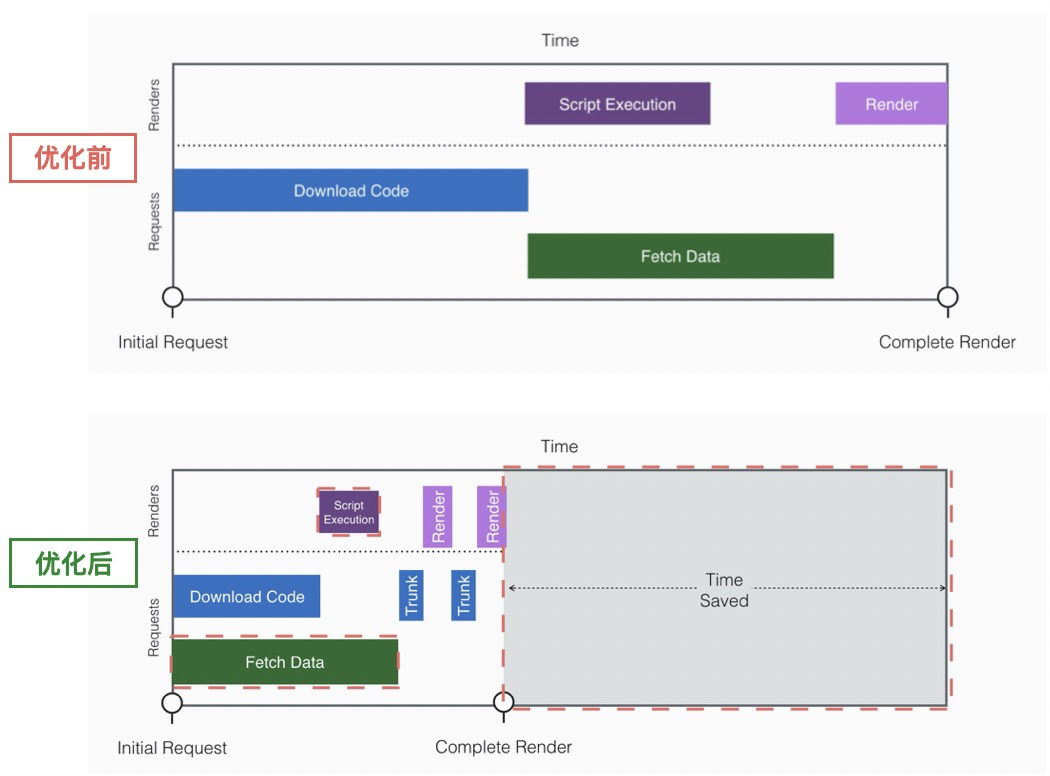
需要特别注意一点:由于JS的执行是串行,发起取数的那段逻辑必须要先于主流程逻辑执行,并且不能放到nextTick(如使用setTimeout(() => doFetch())),否则主流程会一直占用CPU时间使得请求无法发出
主动任务调度
浏览器对资源也有优先级策略,但它并不知道业务层面的我们,到底想要哪些资源先加载/执行,哪些资源后加载/执行,所以我们跳出来看,若把整个业务层面的资源加载+执行/取数流程拆成一个一个小的任务,这些任务全权由我们自己来控制其:打包粒度、加载时机、执行时机,是不是意味着能最大化利用CPU时间和网络资源了?
答案是肯定的,不过一般对于简单的项目,浏览器本身的调度优先级策略已经足够满足需要,但如果针对大型复杂项目,要做的相对极致的优化,就有必要引入“自定义任务调度”方案了。
以Quick BI为例,我们的前期目标是:让首屏主要内容展现更加快速。那么从资源加载、代码执行、取数层面是应该根据我们业务优先级作CPU/网络分配的,比如:我希望“卡片的下拉菜单”,在首屏主要内容展示完毕后或CPU空闲时,才开始加载(即降低优先级,更甚至在用户鼠标移入卡片中时,又希望它提高优先级立即开始加载并展示)。如下:

这里我们封装了一个任务调度器,其目的是可以声明一段逻辑,在其某个依赖(Promise)完成后开始执行。我们的流程图变化如下:
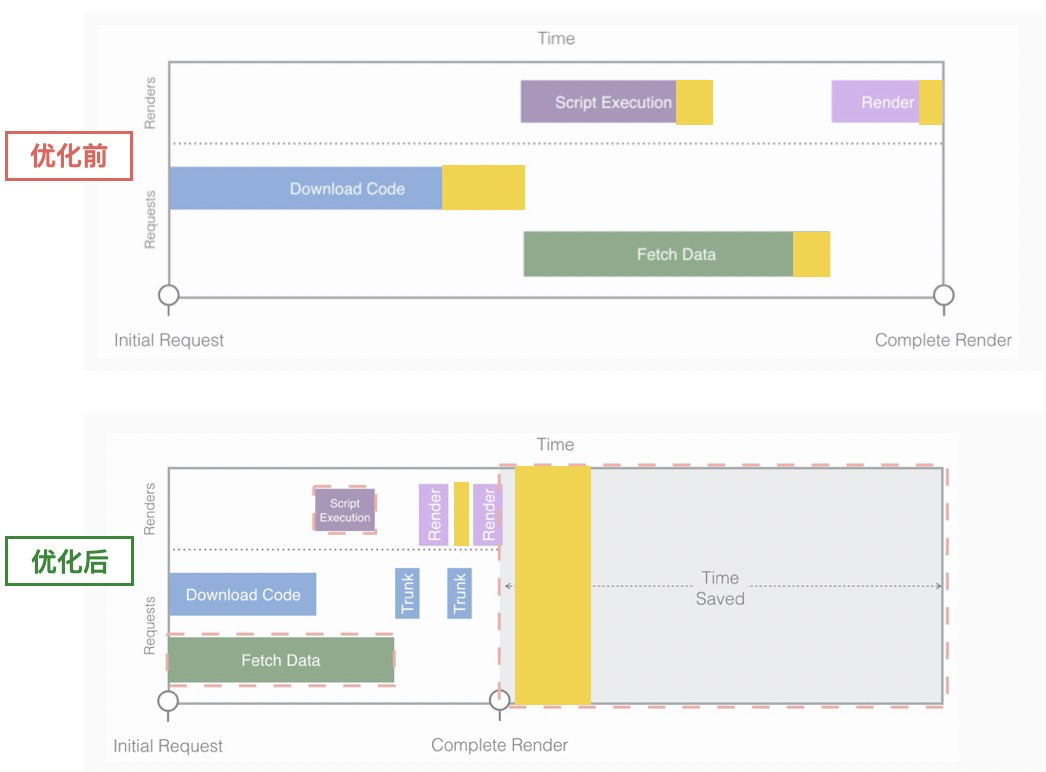
黄色区块代表 作优先级降级处理的部分模块,其帮助减少了整个首屏时间
TreeShaking
上面讲方法大多从优先级出发,其实在前端工程化日益复杂的时代(中大型项目已超几十万行代码),诞生了一个较为智能的优化方案用于减少包大小,其思想很简单:工具化分析依赖关系,将没有被引用到的代码从最终产物中剔除掉。
听起来很酷,实际用起来也非常不错,但这里想讲一些很多其官网也不会提到的点 --- TreeShaking经常失效的情况:
副作用
副作用(Side Effects)通常表达的是对全局(如window对象等)或环境会产生影响的代码。

如图示例,b代码看似未被使用,但其文件中存在console.log(b(1))这样的代码,webpack等打包工具不敢轻易移除它,所以它会被照常打入。
解决方法
在package.json 或 webpack配置中明确指定哪些代码具备副作用(例如sideEffects: [“**/*.css”]),无副作用的代码将被移除
IIFE类代码
IIFE即会被立即执行的函数表达式(Immediately invoked function expression)

如图,这类型的代码,会导致TreeShaking失效
解决方法
三个原则:
- [避免]立即执行的函数调用
- [避免]立即执行的new操作
- [避免]立即影响全局的代码
懒加载
我们在“按需加载”处提到过异步import来做拆包会导致TreeShaking失效,这里再进一步说明一下另外一个case:

如图,由于index.ts同步import了bar.ts中的sharedStr,然后在某个地方,又同时异步import('./bar'),这种情况下,会同时导致两个问题:
- TreeShaking失效(
unusedStr会被打入) - 异步懒加载失效(
bar.ts会和index.ts打入到一起)
当代码量达到一定量级,N个人协同开发就很容易出现这个问题
解决方法
- [避免]同步和异步import同个文件
按需策略(Lazy)
其实前面有讲到一些按需加载的方案,这里我们适当延伸一下:既然资源包的加载可以做到按需,是否某个组件的渲染可以按需?某个对象实例的使用可以按需?某个数据缓存的生成也可以按需?
懒组件(LazyComponent)
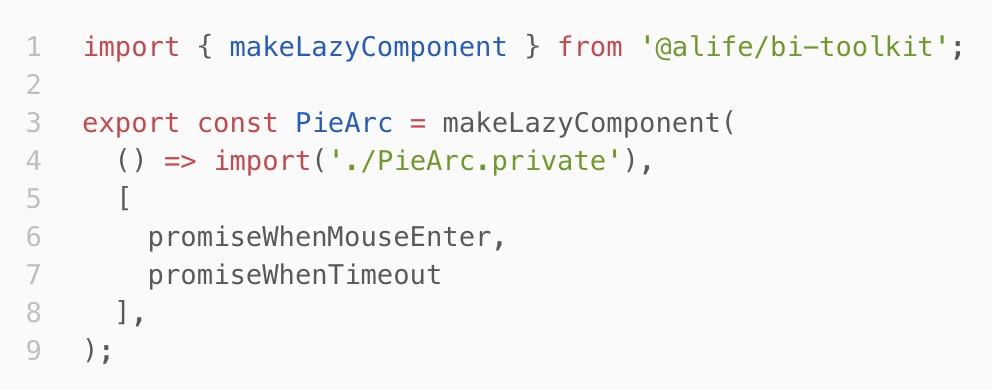
如图,PieArc.private.ts对应一个复杂的React组件,PieArc通过makeLazyComponent封装成默认懒加载的组件,只有在代码执行到此处时,组件才会加载并执行。甚至,还可以通过第二个参数(deps)申明依赖,待依赖(promise)完毕时,才加载和执行。
懒缓存(LazyCache)
懒缓存用于这种场景:需要在任何地方使用到数据流(或其他可订阅数据)中的某个数据经过转换后的结果,且仅在使用的那一刻才进行转换

懒对象(LazyObject)
懒对象意即该对象只有在被使用的时候(属性/方法被访问、修改、删除等等),才会被实例化

如图,globalRecorder被引入时,其并未实例化,仅当调用globalRecorder.record()时进行实例化
数据流:节流渲染
中大型项目中为了方便状态管理,通常会使用到数据流的方案,如下流程:
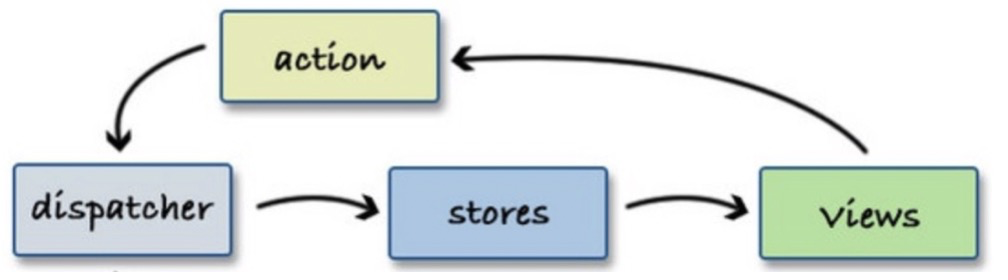
store中存储的数据通常偏原子化,粒度非常小,比如state中有:a、b、c ...等N个原子属性,某个组件依赖这N个属性来作UI渲染,假设N个属性会在不同的ACTION下被改变,且这些改变均在16ms内发生,那么若N=20,则16ms内(1帧)会有20次View更新:

这显然会引发非常大的性能问题,由此,我们需要对短时间的ACTION量作一个缓冲节流,待20次ACTION状态改变完毕后,仅进行1次View更新,如下:

此方案在Quick BI以redux中间件的形式发挥作用,在复杂+频繁数据更新场景起到了不错的效果
思考
“君子以思患而豫防之”,当我们回过头去看看,出现的这些性能问题,在架构设计、编码阶段是可以避免掉80%以上的,20%的则可以“空间<=>时间置换策略”等方式去平衡。所以,最佳的性能优化方案,是在于我们对每一段代码质量的执着:是否考虑到了这样的模块依赖关系,可能带来的构建产物体积问题?是否考虑到了这段逻辑可能的执行频次?是否考虑到了随着数据增长,空间或CPU占用的可控性?等等。性能优化没有银弹,作为技术人,需要内修于心(熟知底层原理),把对性能的执念植入本能思考当中,方为银弹。
Quick BI的复杂系统为例:那些年,我们一起做过的性能优化的更多相关文章
- Quick BI的SQL传参建模可以用在什么场景
Quick B的SQL传参建模功能提供基于SQL的数据加工处理能力,减轻了IT支撑人员的工作量.在即席查询SQL中,我们用物理字段显示别名来表示参数的占位符,配置完占位符后,就可以在查询控件中进行参数 ...
- Quick BI支持哪些数据源(配置操作篇)
Quick BI 潜心打造了核心技术底座(OLAP分析引擎),实现了SQL解析.SQL调度.SQL优化.查询加速等基础能力,支撑Quick BI的数据分析和查询加速.OLAP分析引擎包括数据源连接.数 ...
- Quick BI功能篇之(一):20分钟入门
前言: 最近小编帮助隔壁团队一个小姐姐解决了个大难题:给老板汇报业绩分析,频次提高.效率提升,还得保证团队中的小伙伴们都得有点大数据时代的基本数据能力.小编觉得这么好的经验可以分享给更多志同道合的朋友 ...
- Quick BI取数模型深度剖析
开发图表最关键的点在于选择准确的图表类型展示准确的数据,而准确的数据往往依赖于一个强大的取数模型,因此设计一个好的取数模型不仅可以解决数据安全的问题,更可以帮助每个访问者高效触达自己想要的数据,开发者 ...
- 使用 UML 进行业务建模:理解业务用例与系统用例的相似和不同之处
使用 UML 进行业务建模:理解业务用例与系统用例的相似和不同之处 作者:Arthur V. English 出处:IBM 本文内容包括: 背景 业务用例模型与系统用例模型有什么相似之处? 业 ...
- 应对WannaCry勒索危机之关闭445端口等危险端口——以本人Windows7系统为例
应对WannaCry勒索危机之关闭445端口等危险端口--以本人Windows7系统为例 近日,全球范围内爆发WannaCry勒索病毒危机 我国很多大学纷纷中招.受灾严重,甚至连刘老师的电脑也-- 拿 ...
- 【C语言】字节对齐问题(以32位系统为例)
1. 什么是对齐? 现代计算机中内存空间都是按照字节(byte)划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型 ...
- 关于IP核中中断信号的使用---以zynq系统为例
关于IP核中中断信号的使用---以zynq系统为例 1.使能设备的中断输出信号 2.使能处理器的中断接收信号 3.连接IP核到处理器之间的中断 此处只是硬件的搭建,软件系统的编写需要进一步研究. 搭建 ...
- 阿里云Quick BI——让人人都成为分析师
在3月29日深圳云栖大会的数据分析与可视化专场中,阿里云产品专家潘炎峰(陌停)对大数据智能分析产品 Quick BI 进行了深入的剖析.大会现场的精彩分享也赢得观众们的一直认可和热烈的反响. Quic ...
随机推荐
- NVIDIA深度架构
NVIDIA深度架构 本文介绍A100 GPU,NVIDIA Ampere架构GPU的重要新功能. 现代云数据中心中运行的计算密集型应用程序的多样性推动了NVIDIA GPU加速的云计算的爆炸式增长. ...
- 硬件delay评估表
硬件delay评估表 硬件延时评估表用于快速评估一个模型在特定硬件环境和推理引擎上的推理速度. Bw 主要用于定义PaddleSlim支持的硬件延时评估表的格式. 概述 硬件延时评估表中存放着所有可能 ...
- ARM系统架构
ARM系统架构 一.ARM概要 ARM架构,曾称进阶精简指令集机器(Advanced RISC Machine)更早称作Acorn RISC Machine,是一个32位精简指令集(RISC)处理器架 ...
- CodeGen结构循环回路
CodeGen结构循环回路 structure循环是一个模板文件构造,它允许您迭代CodeGen拥有的有关结构的集合.为了使用结构循环,必须同时基于多个存储库结构生成代码. CodeGen可以通过以下 ...
- 我想挑战下我的软肋,动手实现个Spring应用上下文!
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 目录 [x] 第 1 章:开篇介绍,我要带你撸 Spring 啦! [x] 第 2 章:小试牛 ...
- UF_EVAL 曲线或边分析
Open C UF_EVAL_ask_arc 圆形曲线或边分析,得到曲线或边的信息UF_EVAL_ask_ellipse 椭圆曲线或边分析,得到曲线或边的信息UF_EVAL_ask_hyperbo ...
- 01:HTTP协议
软件开发架构 cs 客户端 服务端bs 浏览器 服务端ps:bs本质也是cs 浏览器窗口输入网址回车发生了几件事 """ 1 浏览器朝服务端发送请求 2 服务端接受请 ...
- DFS————从普及到IOI(暴力骗分小能手)
DFS 啦啦啦,再来水一波 先说思想吧! 背景: 深度优先搜索算法(英语:Depth-First-Search,简称DFS)是一种用于遍历或搜索树或图的算法. ----来自度娘 一.思想 DFS算法思 ...
- 解决两个相邻的span,或者input和button中间有间隙,在css中还看不到
<span id="time"></span><span id="second"></span> <inp ...
- js笔记21
1.解决函数内的this指向 (1)可以在函数外提前声明变量 _this/=this (2)通过apply和call来修改函数内的this指向 二者的区别: 二者的用法不一样,就是参数形式不一样 ...