开源一周岁,MindSpore新特性巨量来袭
摘要:MindSpore很多新特性与大家见面了,无论是在效率提升、易用性,还是创新方面,都是干货满满。
最近,AI计算框架是业界的热点,各大厂商纷纷投身AI框架的自研发,究其原因:AI框架在整个人工智能方案里,就像计算机的OS一样,得AI框架者得天下,得什么呢? 生态!
下面我们来介绍下MindSpore开源一周年后,有哪些牛B的特性发布。(MindSpore已集成到华为云全流程AI开发平台ModelArts里,开发者可以非常方便的在华为云ModelArts里体验MindSpore新特性)。
1、大幅提升动态图下分布式训练的效率:
在深度学习中,当数据集和参数量的规模越来越大,训练所需的时间和硬件资源会随之增加,最后会变成制约训练的瓶颈。分布式并行训练,可以降低对内存、计算性能等硬件的需求,是进行训练的重要优化手段。当前 MindSpore 动态图模式已经支持数据并行,通过对数据按 batch 维度进行切分,将数据分配到各个计算单元中进行模型训练,从而缩短训练时间。
基于 ResNet50 v1.5+ImageNet 数据集测试,昇腾算力,MindSpore 动态图模式分布式的表现,可以达到 PyTorch 典型分布式场景的 1.6 倍, 静态图模式分布式的表现也可以达到 TensorFlow 典型分布式场景的 2 倍。
PyNative 快速入门:https://www.mindspore.cn/tutorial/training/zh-CN/r1.2/advanced_use/debug_in_pynative_mode.html
2、数据预处理加速 Dvpp:
数据是机器学习的基础。在网络推理场景中,我们需要针对不同的数据进行数据的预处理,从中过滤出核心信息放入我们训练好的模型中进行推理预测。在实际应用场景中,我们往往需要对大量的原始数据进行推理,比如实时的视频流等。因此,我们在昇腾推理平台引入了 Dvpp 模块,来针对网络推理数据预处理流程进行加速。
Dvpp 数据预处理模块提供 C++ 接口,提供图片的解码、缩放,中心抠图、标准化等功能。在 Dvpp 模块的设计中,考虑到整体的易用性,其功能与 MindData 现有 CPU 算子有重叠,我们将其 API 统一,通过推理执行接口设置运行设备来进行区分。用户可以根据自身硬件设备环境来选择最佳的执行算子。
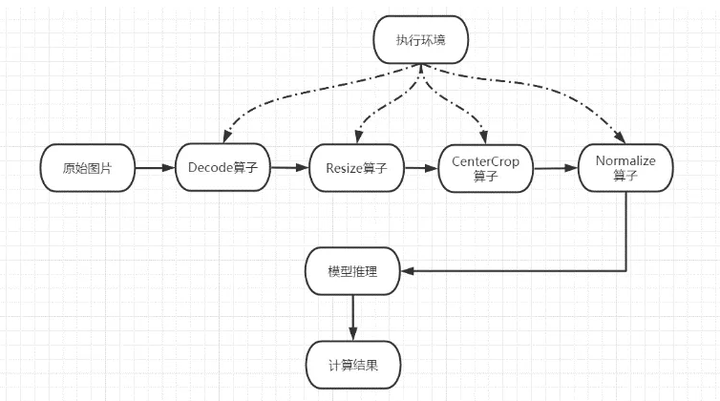
我们在一台昇腾推理服务器上测试了 Dvpp 系列算子的性能收益。该服务器拥有 128 个主频为 2.6GHz 的 CPU 核心,以及 128Gb 的内存空间。在实验中,我们选取 yoloV3 网络,同时选取 coco2017 推理数据集 40504 张图片进行推理,最终得到模型输入尺寸为 [416, 416] 的图片。
我们分别使用 Dvpp 算子和 CPU 算子进行数据预处理,得到如下性能对比:

可以看到 Dvpp 系列算子相较于 CPU 算子在处理大量数据时性能优势明显,在本实验中处理 40504 张图片性能 FPS 提升 129%。
3、分子模拟库(SPONGE),来自社区分子动力学工作组:
MindSpore 版的 SPONGE 是在社区中的分子动力学工作组 (MM WG) 中,由北大、深圳湾实验室高毅勤课题组与华为 MindSpore 团队联合开发的分子模拟库,具有高性能、模块化等特性。
为何需要开发 SPONGE?
分子动力学模拟是用牛顿定律近似来描述微观原子和分子尺度演化的计算机模拟方法。其既可用于基础科学研究也可用于工业实际应用。在基础科学领域,分子动力学方法有助于科研学者从微观研究体系的物理化学性质。
在工业生产中,其可以利用大规模计算的能力辅助药物分子的设计和蛋白靶点的搜寻 [1,2]。由于模拟的时间和空间尺度限制,传统分子动力学软件的应用范围受到较大限制。科研工作者也在不断的开发新的力场模型[3,4]、抽样方法[5,6] 以及尝试结合新兴的人工智能 [7,8] 来进一步拓展分子动力学模拟的适用领域。
由此,新一代的分子动力学软件就需要被提上日程。其应该具有模块化的特性,能够支持科学家高效的创造和搭建出能够验证其理论模型的结构。同时,它还需要兼顾传统模拟方法的高效性,能够兼容其在传统领域上的使用。此外,为实现分子模拟 + 机器学习的自然融合,其还应该拥有嵌入人工智能框架的形态。SPONGE 就是基于这些理念而被创造出的全新的,完全自主的分子模拟软件。
相比于之前在传统分子模拟软件上结合 SITS 方法进行生物分子增强抽样[9],SPONGE 原生支持 SITS 并对计算流程进行优化使得其使用 SITS 方法模拟生物体系更加高效。针对极化体系,传统分子模拟采用结合量化计算等方式来解决电荷浮动等问题[10]。即使采用机器学习降低计算量也会浪费大量时间在程序数据传送的问题上。而 SPONGE 利用模块化的特点可支持内存上直接与机器学习程序通信大大降低了整体计算时间。
图 1:结合 SITS 等方法可进行 Na[CpG], Lys 生物分子模拟

图 2:机器学习 + 分子模拟方法可更快更准确地模拟极化体系,图为[C1MIm]Cl 离子液体模拟
MindSpore + SPONGE
基于 MindSpore 自动并行、图算融合等特性,SPONGE 可高效地完成传统分子模拟过程。SPONGE 利用 MindSpore 自动微分的特性,可以将神经网络等 AI 方法与传统分子模拟进行结合。
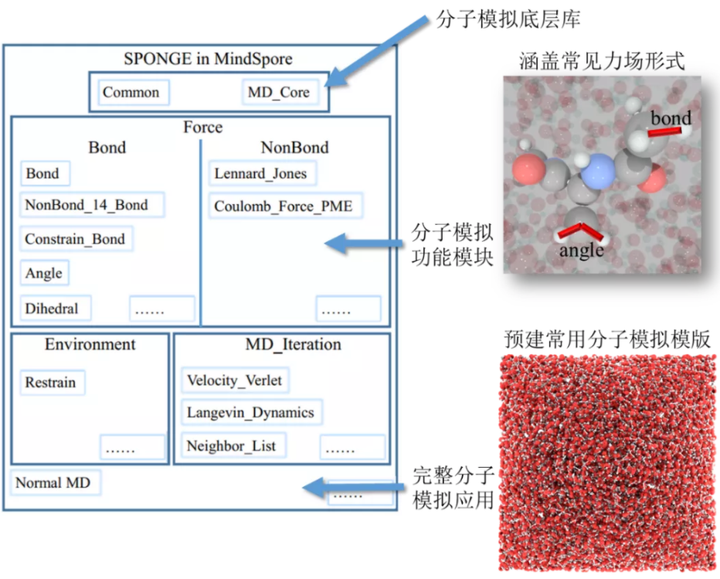
SPONGE 模块化设计结构图
随 MindSpore1.2 版本开源的 SPONGE 具备以下优势:
1、全模块化分子模拟。模块化构建分子模拟算法,易于领域研发人员进行理论和算法的快速实现,并为外部开发人员贡献子模块提供友好的开源社区环境。
2、传统分子模拟与 MindSpore 结合的人工智能算法的全流程实现。在 MindSpore 中,研发人员能便利的将 AI 方法作用于分子模拟中。全算子化的 SPONGE 将与 MindSpore 进一步结合成为新一代端到端可微的分子模拟软件,实现人工智能与分子模拟的自然融合。
教程文档:https://www.mindspore.cn/tutorial/training/zh-CN/r1.2/advanced_use/hpc_sponge.html
MindSpore+SPONGE 展望
近期展望:在后续的版本更新中会陆续加入已经理论验证好的 MetaITS 模块、有限元计算模块等功能。这些模块将帮助 SPONGE 能更好的从事相变和金属表面相关的模拟。同时,MindSpore 版 SPONGE 各模块逐步支持自动微分和自动并行,对于衔接机器学习方案提供更友好的支持。
远期展望:拓展 SPONGE 的各种特色模块,使其能够描述大部分微观体系并同时具有较高的计算和采样效率。对特定工业需求,如药物筛选或晶型预测,将基于 SPONGE 衍生出完整的流程化计算方案,能够满足大规模并行计算的需求。在 MindSpore 框架下,SPONGE 具有元优化功能,从而实现更准确和更快的力场拟合。
4、量子机器学习(MindQuantum),来自社区量子力学工作组:
MindQuantum 是结合 MindSpore 和 HiQ 开发的量子机器学习框架,支持多种量子神经网络的训练和推理。得益于华为 HiQ 团队的量子计算模拟器和 MindSpore 高性能自动微分能力,MindQuantum 能够高效处理量子机器学习、量子化学模拟和量子优化等问题,性能达到业界 TOP1(Benchmark),为广大的科研人员、老师和学生提供了快速设计和验证量子机器学习算法的高效平台。

MindQuantum vs TF Quantum/Paddle Quantum 性能对比


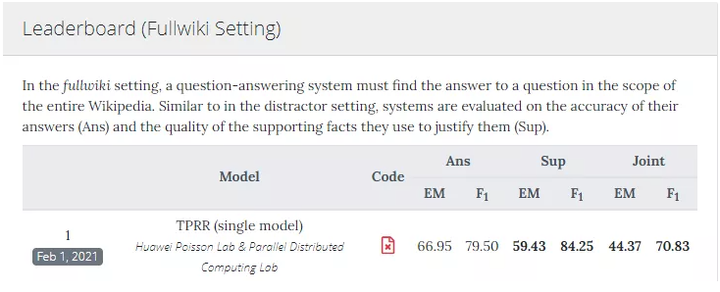
5、多跳知识推理问答(TPRR):
TPRR 是解决开放域多跳问题的通用模型。相比于传统问答仅需从单个文档中检索答案,多跳知识推理问答需要从多个佐证文档得到最终答案,并返回问题到答案的推理链。TPRR 基于 MindSpore 混合精度特性,可以高效地完成多跳问答推理过程。
全路径建模:
TPRR 模型在多跳问题推理链的每一个环节中基于全部推理路径的条件概率建模,模型以 「全局视角」 进行知识推理。
动态样本选取:
TPRR 模型采用动态样本的建模方式,通过更强的对比学习提升模型多跳问答的能力。
算法流程图如下:
TPRR 模型在国际权威的多跳问答榜单 HotpotQA 评测中荣登榜首,榜单图如下:
查看教程:https://www.mindspore.cn/tutorial/inference/zh-CN/r1.2/nlp_tprr.html
6、一键模型迁移(MindConverter):
脚本迁移工具(MindConverter)旨在帮助算法工程师将存量的基于三方框架开发的模型快速迁移至 MindSpore 生态。根据用户提供的 TensorFlow PB 或 ONNX 模型文件,工具通过对模型的计算图(Computational Graph)解析,生成一份具备可读性的 MindSpore Python 模型定义脚本(.py)以及相应的模型权重(.ckpt)。

一键迁移:
通过 MindConverter CLI 命令即可一键将模型迁移为 MindSpore 下模型定义脚本以及相应权重文件,省去模型重训以及模型定义脚本开发时间;
100% 迁移率:
在 MindConverter 具备跨框架间算子映射的情况下,迁移后脚本可直接用于推理,实现 100% 迁移率;
支持模型列表:
目前工具已支持计算机视觉领域典型模型、自然语言处理 BERT 预训练模型脚本及权重的迁移,详细模型列表见 README。
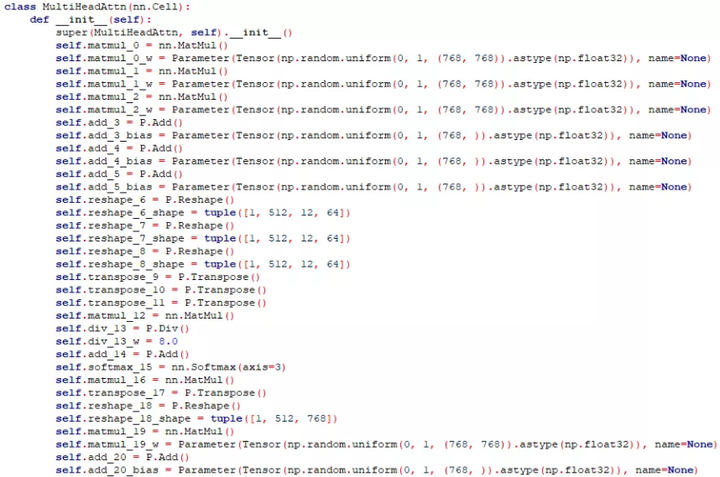
BERT 模型定义迁移结果展示(部分代码):
7、鲁棒性评测工具助力 OCR 服务达成首个 AI C4 鲁棒性标准要求:
MindSpore 鲁棒性测试工具 MindArmour,基于黑白盒对抗样本(20 + 方法)、自然扰动(10 + 方法)等技术提供高效的鲁棒性评测方案,帮助客户评估模型的鲁棒性性,识别模型脆弱点。
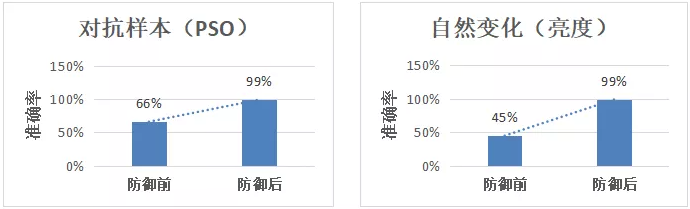
OCR 是指利用光学设备去捕获图像并识别文字,减少人工成本,快速提升工作效率;如果攻击者通过对待识别的文字做出人眼不易察觉的修改,而模型无法对其正确识别或处理,就会导致 OCR 服务对文字识别的准确率下降,且使用人员不清楚问题背后的原因。测评团队使用 MindArmour 对 OCR 服务的鲁棒性进行测评,发现 OCR 服务中部分模型对自然扰动和对抗样本的防御能力较差,如文本框检测模型在校验噪声、PGD、PSO(粒子群)等攻击算法下准确率小于 66%;并以此指导模型开发团队通过对抗样本检测、数据增强训练等技术,使得模型对恶意样本的识别准确率达到 95+%,提高了模型及 OCR 服务的鲁棒性。
AI C4 标准链接:https://www.bsi.bund.de/SharedDocs/Downloads/EN/BSI/CloudComputing/AIC4/AI-Cloud-Service-Compliance-Criteria-Catalogue_AIC4.html
本文分享自华为云社区《MindSpore开源一年的新特性介绍》,原文作者:简单坚持。
开源一周岁,MindSpore新特性巨量来袭的更多相关文章
- [翻译] C# 8.0 新特性 Redis基本使用及百亿数据量中的使用技巧分享(附视频地址及观看指南) 【由浅至深】redis 实现发布订阅的几种方式 .NET Core开发者的福音之玩转Redis的又一傻瓜式神器推荐
[翻译] C# 8.0 新特性 2018-11-13 17:04 by Rwing, 1179 阅读, 24 评论, 收藏, 编辑 原文: Building C# 8.0[译注:原文主标题如此,但内容 ...
- 【开源】OSharp3.3框架解说系列:重新开源及3.3版本新特性
OSharp是什么? OSharp是个快速开发框架,但不是一个大而全的包罗万象的框架,严格的说,OSharp中什么都没有实现.与其他大而全的框架最大的不同点,就是OSharp只做抽象封装,不做实现.依 ...
- 如何使用开源库,吐在VS2013发布之前,顺便介绍下VS2013的新特性"Bootstrap"
刚看到Visual Studio 2013 Preview - ASP.NET, MVC 5, Web API 2新功能搶先看 看了下VS2013带来的"新特性",直觉上看,除了引 ...
- 如何使用开源库,吐在VS2013发布之前,顺便介绍下V2013的新特性"Bootstrap"
如何使用开源库,吐在VS2013发布之前,顺便介绍下VS2013的新特性"Bootstrap" 刚看到Visual Studio 2013 Preview - ASP.NET, M ...
- JDK1.5/1.6/1.7之新特性总结(转载)
原文地址:http://www.cnblogs.com/yezhenhan/archive/2011/08/16/2141510.html 如果原作者看到不想让我转载请私信我! 开发过程中接触到了从j ...
- SQL Server 2014新特性探秘(2)-SSD Buffer Pool Extension
简介 SQL Server 2014中另一个非常好的功能是,可以将SSD虚拟成内存的一部分,来供SQL Server数据页缓冲区使用.通过使用SSD来扩展Buffer-Pool,可以使得大量随 ...
- java5、java6、java7、java8的新特性
Java5: 1.泛型 Generics: 引用泛型之后,允许指定集合里元素的类型,免去了强制类型转换,并且能在编译时刻进行类型检查的好处. Parameterized Type作为参数 ...
- JAVA JDK1.5-1.9新特性
1.51.自动装箱与拆箱:2.枚举(常用来设计单例模式)3.静态导入4.可变参数5.内省 1.61.Web服务元数据2.脚本语言支持3.JTable的排序和过滤4.更简单,更强大的JAX-WS5.轻量 ...
- jdk1.6新特性
1.Web服务元数据 Java 里的Web服务元数据跟微软的方案基本没有语义上的区别,自从JDK5添加了元数据功能(Annotation)之后,SUN几乎重构了整个J2EE体 系, 由于变化很大,干脆 ...
随机推荐
- vux使用
Vue中使用vux的配置,分为两种情况: 一.根据vux文档直接安装,无需手动配置 npm install vue-cli -g // 如果还没安装 vue init airyland/vux2 my ...
- Python数据结构与算法_最长公共前缀(05)
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- @RestController和@Controller
1.使用@Controller 注解,在对应的方法上,视图解析器可以解析return 的jsp,html页面,并且跳转到相应页面 若返回json等内容到页面,则需要加@ResponseBody注解 2 ...
- 微信小程序(四)-样式 WXSS
样式 WXSS https://developers.weixin.qq.com/miniprogram/dev/framework/view/wxss.html 1.尺寸单位 rpx(respons ...
- Qt+opencv亲自配置教程
了别人的配置,总是无法配置成功,自己慢慢摸索配置成功.我失败的原因是在于自己本机的环境变量和他们不同,特此记下,分享给有相同问题的朋友. 一.需要软件 1.cmake 3.11.3(版本无所谓) 2. ...
- #progma pack(x)说明
1.字节对齐(内存相关) 现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型数 ...
- Hi3559AV100板载开发系列-pthread_create()下V4L2接口MJPEG像素格式的VIDIOC_DQBUF error问题解决-采用阻塞方式下select监听
最近一直加班加点进行基于Hi3559AV100平台的BOXER-8410AI板载开发,在开发的过程中,遇到了相当多的问题,其一是板载的开发资料没有且功能不完整,厂家不提供太多售后技术支持,厂家对部分 ...
- MySql学习---数据库基本类型,事务,多表查询
数据库分类 关系型数据库 行列, 列如Mysql,oracle 通过表和表之间,行和列之间的关系进行数据的存储 非关系型数据库: Redis,MongDb 以对象存储,同过对象的自身属性来决定 表与表 ...
- day1_安装及建立数据库和表
#第一份数据库及表create database library; use library; create table book( id int primary key, book_name char ...
- pytest+jenkins+allure 生成测试报告发送邮件
前言第一部分:Pycharm for Gitee1. pycharm安装gitee插件2. gitee关联本地Git快速设置- 如果你知道该怎么操作,直接使用下面的地址简易的命令行入门教程:3. Gi ...