MySQL架构原理之存储引擎InnoDB_Redo Log和BinLog
Redo Log和Binlog是MySQL日志系统中非常重要的两种机制,有很多相似之处同时也有差别,本文探究两者细节和区别。
一、Redo Log
1、Redo Log介绍
Redo:顾名思义就是重做。以恢复操作为目的,在数据库发生意外时重现操作。
Redo Log:指事务中修改的任何数据,将最新的数据备份存储的位置(Redo Log),被称为重做日志。
Redo Log 的生成和释放:随着事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer,并不是随着事务的提交就立刻写入磁盘文件。等事务操作的脏页写入到磁盘之后,Redo Log 的使命也就完成了,Redo Log占用的空间就可以重用(被覆盖写入)。
2、Redo Log工作原理
Redo Log 是为了实现事务的持久性而出现的产物。防止在发生故障的时间点,尚有脏页未写入表的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。
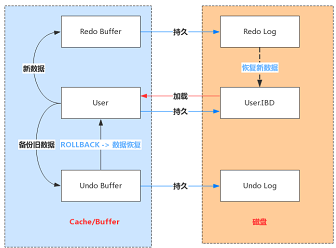
3、Redo Log写入机制
Redo Log 文件内容是以顺序循环的方式写入文件,写满时则回溯到第一个文件,进行覆盖写。

如图所示:1)write pos 是当前记录的位置,一边写一边后移,写到最后一个文件末尾后就回到 0 号文件开头;
2)checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件;
write pos 和 checkpoint 之间还空着的部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示写满,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint推进一下。
4、Redo Log相关配置参数
每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,默认为ib_logfile0和ib_logfile1。可以通过下面一组参数控制Redo Log存储:
show variables like '%innodb_log%';
Redo Buffer 持久化到 Redo Log 的策略,可通过 Innodb_flush_log_at_trx_commit 设置:
0:每秒提交 Redo buffer ->OS cache -> flush cache to disk,可能丢失一秒内的事务数据。由后台Master线程每隔 1秒执行一次操作。
1(默认值):每次事务提交执行 Redo Buffer -> OS cache -> flush cache to disk,最安全,性能最差的方式。
2:每次事务提交执行 Redo Buffer -> OS cache,然后由后台Master线程再每隔1秒执行OScache -> flush cache to disk 的操作。
一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数据。

二、BinLog
1、Binlog记录模式
Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。开启Binlog日志有以下两个最重要的使用场景。
主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
数据恢复:通过mysqlbinlog工具来恢复数据。
Binlog文件名默认为“主机名_binlog-序列号”格式,例如oak_binlog-000001,也可以在配置文件中指定名称。文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。
STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
优点:日志量小,减少磁盘IO,提升存储和恢复速度
缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。
MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
2、Binlog文件结构
MySQL的binlog文件中记录的是对数据库的各种修改操作,用来表示修改操作的数据结构是Logevent。不同的修改操作对应的不同的log event。比较常用的log event有:Query event、Rowevent、Xid event等。binlog文件的内容就是各种Log event的集合。
Binlog文件中Log event结构如下图所示:

3、Binlog写入机制
1)根据记录模式和操作触发event事件生成log event(事件触发执行机制)
2)将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区
Log Event保存在一个binlog_cache_mngr数据结构中,在该结构中有两个缓冲区,一个是stmt_cache,用于存放不支持事务的信息;另一个是trx_cache,用于存放支持事务的信息。
3)事务在提交阶段会将产生的log event写入到外部binlog文件中。
不同事务以串行方式将log event写入binlog文件中,所以一个事务包含的log event信息在binlog文件中是连续的,中间不会插入其他事务的log event。
4、Binlog文件操作
1)Binlog状态查看

2)开启Binlog功能

需要修改my.cnf或my.ini配置文件,在[mysqld]下面增加log_bin=mysql_bin_log,重启MySQL服务。
3)使用show binlog events命令

4)使用mysqlbinlog 命令

5)使用 binlog 恢复数据

mysqldump:定期全部备份数据库数据。mysqlbinlog可以做增量备份和恢复操作。
6)删除Binlog文件

可以通过设置expire_logs_days参数来启动自动清理功能。默认值为0表示没启用。设置为1表示超出1天binlog文件会自动删除掉。
5、Redo Log和Binlog区别
Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用。
Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash-safe能力。
MySQL架构原理之存储引擎InnoDB_Redo Log和BinLog的更多相关文章
- MySQL架构原理之存储引擎InnoDB_Undo Log
Undo:意为撤销或取消,以撤销操作为目的,返回某个指定状态的操作. Undo Log:数据库事务开始之前会将要修改的记录存放到Undo日志里,当事务回滚时或者数据库崩溃时可以利用Undo日志撤销为提 ...
- MySQL架构原理之存储引擎InnoDB数据文件
MySQL架构原理之体系架构 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)中简单介绍了MySQL的系统文件层,其中包含了数据文件.那么InnoDB的数据文件是如何分类并存储的呢? 一. ...
- MySQL架构原理之存储引擎InnoDB线程模型
如下图示,为InnoDB线程模型示意图: 1.IO Thread 在InnoDB中使用了大量的AIO(Async IO)来做读写处理,这样可以极大提高数据库的性能.其提供了write/read/ins ...
- MySQL内核:InnoDB存储引擎 卷1
MySQL内核:InnoDB存储引擎卷1(MySQL领域Oracle ACE专家力作,众多MySQL Oracle ACE力捧,深入MySQL数据库内核源码分析,InnoDB内核开发与优化必备宝典) ...
- Mysql技术内幕——InnoDB存储引擎
Mysql技术内幕——InnoDB存储引擎 http://jingyan.baidu.com/article/fedf07377c493f35ac89770c.html 一.mysql体系结构和存储引 ...
- mysql 数据表操作 存储引擎介绍
一 什么是存储引擎? 存储引擎就是表的类型. mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制 ...
- MySQL数据库篇之存储引擎
主要内容: 一.数据引擎 二.MySQL支持的存储引擎 三.使用存储引擎 1️⃣ 什么是存储引擎? MySQL中建立的库----> 文件夹,库中建立的表----->文件. 现实生活中我们用 ...
- mysql 库操作、存储引擎、表操作
阅读目录 库操作 存储引擎 什么是存储引擎 mysql支持的存储引擎 如何使用存储引擎 表操作 创建表 查看表结构 修改表ALTER TABLE 复制表 删除表 数据类型 表完整性约束 回到顶部 一. ...
- mysql三-1:理解存储引擎
一.什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处 ...
随机推荐
- Mybatis实现分包定义数据库
Mybatis实现分包定义数据库 背景 业务需求中需要连接两个数据库处理数据,需要用动态数据源.通过了解mybatis的框架,计划 使用分包的方式进行数据源的区分. 原理 前提: 我们使用mybati ...
- BeanUtils.copyProperties 选择性赋值字段
BeanUtils.copyProperties 在字段赋值上有强大的功能,如果有两个的类,如果需要将相同的字段赋值,就可以直接赋制.而不需要每个字段都需要一个一个赋制. BeanUtils.copy ...
- spring源码之refresh第二篇
大家好,我是程序员田同学 上篇文章对spring核心启动方法refresh做了整体的解读,但是只是泛泛而谈,接下来会出一系统文章对每个方法的源码进行深刻解读. 第一篇文章见 spring源码之方法概览 ...
- 钓鱼攻击之远程加载恶意Word模版文件上线CS
0x00 前言 利用Word文档加载附加模板时的缺陷所发起的恶意请求而达到的攻击目的,所以当目标用户点开攻击者发给他的恶意word文档就可以通过向远程服务器请求恶意模板并执行恶意模板上的恶意代码.这里 ...
- 关于jar包和war读取静态文件
在war包中static中的静态文件,打成jar包后却读取不到,这是为什么呢,让我门看下两种读取的区别 一.war包中都取静态模板文件 public static void download(Stri ...
- HDC2021技术分论坛:组件通信、硬件池化,这些创新技术你get了吗?
作者:ligang 华为分布式硬件技术专家,sunbinxin 华为应用框架技术专家 HarmonyOS是一款全新的分布式操作系统,为开发者提供了元能力框架.事件通知.分布式硬件等分布式技术,使能开发 ...
- Cesium中级教程9 - Advanced Particle System Effects 高级粒子系统效应
Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ 要了解粒子系统的基础知识,请参见粒子系统入门教程. Weathe ...
- synergy最佳解决方案——barrier
synergy最佳解决方案--barrier 不知道大家有没有一套键盘鼠标控制多台电脑的需求,主流的硬件或说软件有大神整理如下: 软件方案: Windows 之间:Mouse Without Bo ...
- java内部类概述和修饰符
1 package face_09; 2 /* 3 * 内部类访问特点: 4 * 1,内部类可以直接访问外部类的成员. 5 * 2,外部类要访问内部类,必须建立内部类的对象. 6 * 7 * 一把用于 ...
- MySQL数据库索引介绍
一.什么是索引 索引是mysql数据库中的一种数据结构,就是一种数据的组织方式,这种数据结构又称为key 表中的一行行数据按照索引规定的结构组织成了一种树型结构,该树叫B+树 二.为何要用索引 优化查 ...