大数据学习(20)—— Zookeeper介绍
ZooKeeper是什么
就像相声大师冯巩每次出场都说:“亲爱的观众朋友们,我想死你们啦”一样,我再强调一次,学习大数据官网很重要。Zookeeper官网看这里ZooKeeper
ZooKeeper 是一个开源的分布式协调服务,它本身也是分布式设计。它提供了一组简单的原语,基于这些指令,分布式应用能够实现同步、配置更新和分组等高级服务。它的设计宗旨是简单易用,它使用了树形结构的文件目录作为数据模型。
协调服务要做到准确无误是很难的,它容易引发条件竞争和死锁。ZooKeeper的目的,就是让分布式应用不在协调服务上耗费精力,只需要关注业务逻辑实现。通俗地讲,ZooKeeper就是一场交响乐的总指挥,你钢琴师、鼓乐手不用考虑乐队其他成员在干嘛,只看总指挥的指示就好了。
为啥叫ZooKeeper
ZooKeeper顾名思义,动物园管理员,它长这样

这个小伙子管了哪些东西呢?看下面




有啥发现没?是不是全是动物?
ZooKeeper架构

这是一个主从复制集群,每个Server里的数据一样,多个ZooKeeper实例之间通过选举确定一个leader,写操作都是leader来执行(follower节点把写请求转发给leader),读操作可以是客户端连接的follower节点处理。
Client通过TCP连到一个ZooKeeper上,向ZooKeeper集群进行发送请求、接收响应、监听事件、发送心跳等操作。如果Client连接的ZooKeeper宕机,它会自动连接到其他节点。
数据模型
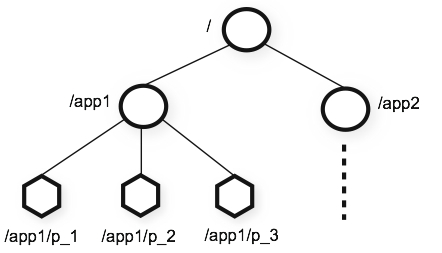
ZooKeeper的命名空间就像一个标准的文件系统,每个节点都是一个路径,叫Znode,可以存放数据。每个节点是一个键值对,它只能存放KB级的数据,比如状态信息、配置、位置信息等等。Znode会记录一些状态信息,比如数据版本号、访问控制列表变更、时间戳等等,用来做协调控制。每当数据更新的时候,版本号会+1。
还有一类节点叫临时节点,当创建这些节点的客户端还活着的时候它就一直存在,但连接断开之后就消失了。
监听
这个概念类似于Java中的actionListener。客户端可以在节点上设置监听,当节点数据发生变化的时候,客户端会收到通知。zk3.6版本之后,监听是永久的。在这个版本之前,监听被触发之后就自动失效。
特性
ZooKeeper基于内存处理数据,速度非常快,而且它提供了一系列机制来保证提供可靠的服务。
- 顺序执行:按照客户端发送指令的先后顺序来执行操作
- 原子性:更新操作不存在中间状态,只有成功或失败两种选择
- 统一视图:集群里的所有服务器都提供统一的视图。写请求通过一致性协议,保证所有Server一致。
- 可靠
- 快速
性能
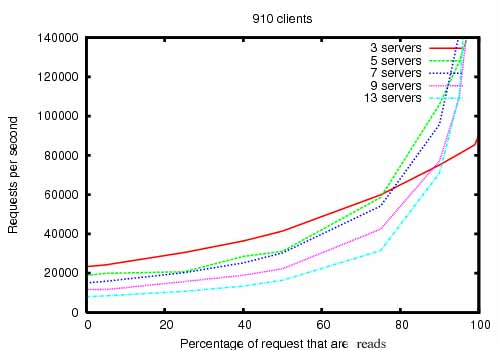
如上图所示,使用910个客户端来发起读写请求,当读请求的比例越来越高时,每秒能够处理的请求呈抛物线上升。因为写请求要保证所有节点数据一致,会消耗性能。
当读写比例大于10:1的时候,3个server每秒能支撑8万多的读请求,5个以上的server每秒能支撑14万以上的读请求。
上图还能看到一个很有意思的现象,当读请求比例是0的时候,server数越少,并发越高。server太多了,写的时候保存一致会花费更长的时间。
大数据学习(20)—— Zookeeper介绍的更多相关文章
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据篇:Zookeeper
Zookeeper 1 Zookeeper概念 Zookeeper是什么 是一个基于观察者设计模式的分布式服务管理框架,它负责和管理需要关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Z ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习:storm流式计算
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: 1.Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 2.由于Storm的处理组件都是分布式的, ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
随机推荐
- some requirement checks failed
1.执行安装数据库软件时报错(./runInstaller): 解决:(1)su - root 执行: x host+ 然后 su - oracle 执行:./runIstal ...
- 『无为则无心』Python基础 — 6、Python的注释
目录 1.注释的作用 2.注释的分类 单行注释 多行注释 3.注释的注意事项 4.什么时候需要使用注释 5.总结 提示:完成了前面的准备工作,之后的文章开始介绍Python的基本语法了. Python ...
- 3-Partition 问题
这是算法考试的最后一题,当时匆匆写了个基于 Subset Sum 的解法,也没有考虑是否可行. 问题描述如下: 给定 \(n\) 个正整数 \(a_1 \dots a_n\) ,设下标的整数集合 \( ...
- 海康威视摄像头入侵+fofa(CVE-2017-7921)
海康威视摄像头入侵+fofa(CVE-2017-7921) By:Jesse 重保期间实在是太无聊,于是就找了个海康威视的摄像头日日玩,结果一玩就是一天呢哈哈哈. 1.漏洞编号 CVE-2017-79 ...
- 最强阿里巴巴历年经典面试题汇总:C++研发岗
(1).B树.存储模型 (2).字典树构造及其优化与应用 (3).持久化数据结构,序列化与反序列化时机(4).在无序数组中找最大的K个数? (4).大规模文本文件,全是单词,求前10词频的单词 (5) ...
- 24、mysql数据库优化
24.1.如何判断网站慢的排查顺序: 客户端->web->nfs->数据库: 24.2.uptime命令详解: [root@backup ~]#uptime 13:03:23 up ...
- consul 多节点/单节点集群搭建
三节点配置 下载安装包 mkdir /data/consul mkdir /data/consul/data curl -SLO https://github.com/consul/1.9.5/con ...
- python 正则表达式 初级
举例: 1.匹配hello world key = r"<h1>hello world<h1>" #源文本 p1 = r"<h1>.+ ...
- CG-CTF Our 16bit wars
一题纯看汇编的题 INT 21H, ah为0A时,是输入字符串到缓冲区DS:DX,DX+1地址存放着字符串长度 说明了长度为35 这里加密是右移3位异或左移5位, 告诉了我们加密后的字符串是什么,写个 ...
- [Vue入门及介绍,基础使用、MVVM架构、插值表达式、文本指令、事件指令]
[Vue入门及介绍,基础使用.MVVM架构.插值表达式.文本指令.事件指令] 1)定义:javascript渐进式框架 渐进式:可以控制一个页面的一个标签,也可以控制一系列标签,也可以控制整个页面 ...