2020国防科大综述:3D点云深度学习——综述(3D点云分割部分)
3D点云深度学习:综述(3D点云分割部分)
Deep Learning for 3D Point Clouds: A Survey
TPAMI 2019.12 作者:Yulan Guo 时间:2019-12
原文地址:https://arxiv.org/abs/1912.12033
文献更新地址:https://github.com/QingyongHu/SoTA-Point-Cloud
作者主页:http://yulanguo.me/
摘要
近年来,因点云学习在许多领域的广泛应用而越来越引起人们的关注,如计算机视觉、自动驾驶和机器人等领域。作为人工智能领域的主要技术,深度学习已经成功用于解决各种二维视觉问题。然而,由于通过深吧 度神经网络处理点云的过程中面临的独特挑战,点云上的深度学习仍处于起步阶段。近来,点云上的深度学习更加蓬勃发展,众多的方法正在提出解决这一领域的不同问题。为了激励未来的研究,本文对点云深度学习方法的最新进展进行了全面综述。它涵盖了三大任务,包括3D形状分类、3D物体检测和跟踪,以及3D点云分割。它还介绍了几个公开数据集的比较结果。以及深刻的观察和启发未来的研究方向。
索引术语: 深度学习,点云,3D数据,形状分类,形状检索,对象检测,对象跟踪,场景流。
(为什么兴起?一是硬件设备采集设备性能更好了;二是3D数据因为多了一个维度包含更多的信息;三是深度学习技术可以在无序的3D数据上施展手脚了)
1、引言:
随着3D采集技术的快速发展,3D传感器越来越多且价格实惠,包括各种类型的3D扫描仪、激光雷达和RGB-D摄像机(如Kinect、RealSense和RealSense、苹果深度相机)[1]。这些传感器获取的3D数据可以提供丰富的几何、形状和比例信息[2][3]。 与二维图像相辅相成,三维数据提供了一个以更好地了解机器周围的环境的机会。三维数据有很多应用在不同领域,包括自动驾驶、机器人、遥感、医疗等领域[4]。三维数据通常可以用不同的格式来表示。包括深度图像、点云、网格和体积网格。作为一种常用的格式,点云保留了原始的几何信息在三维空间中,不需要任何离散化。因此,它是许多场景理解相关的首选表示方法,例如自动驾驶和机器人等应用。最近,深度学习技术有许多主导的研究领域例如:计算机视觉、语音识别和自然语言处理等研究领域。然而,深度学习在3D点云上仍然面临着一些重大的挑战[5],如数据集规模小、维度高和3D点云的非结构化性质。在此的基础上,本文重点分析了深度学习中的的方法,这些方法已被用于处理3D点云。
点云上的深度学习一直吸引着更多的和更多的关注,特别是在过去五年。一些公开的数据集也被发布,如ModelNet [6], ScanObjectNN [7], ShapeNet [8], PartNet [9],S3DIS [10], ScanNet [11], Semantic3D [12], ApolloCar3D[13], and the KITTI Vision Benchmark Suite [14], [15]。这些数据集进一步推动了深度学习在三维点云上的研究。随着越来越多的方法拟解决与点云处理有关的各种问题,包括3D形状分类、3D物体检测和跟踪、3D点云分割、3D点云对准、6-DOF姿态估计和3D重建[16],[17],[18]。很少有关于三维数据的深度学习的调查研究可以得到,如[19]、[20]、[21]、[22]。然而,我们的论文是第一篇专门关注于点云理解的深度学习方法。现有的3D点云的深度学习方法的分类如图1所示:
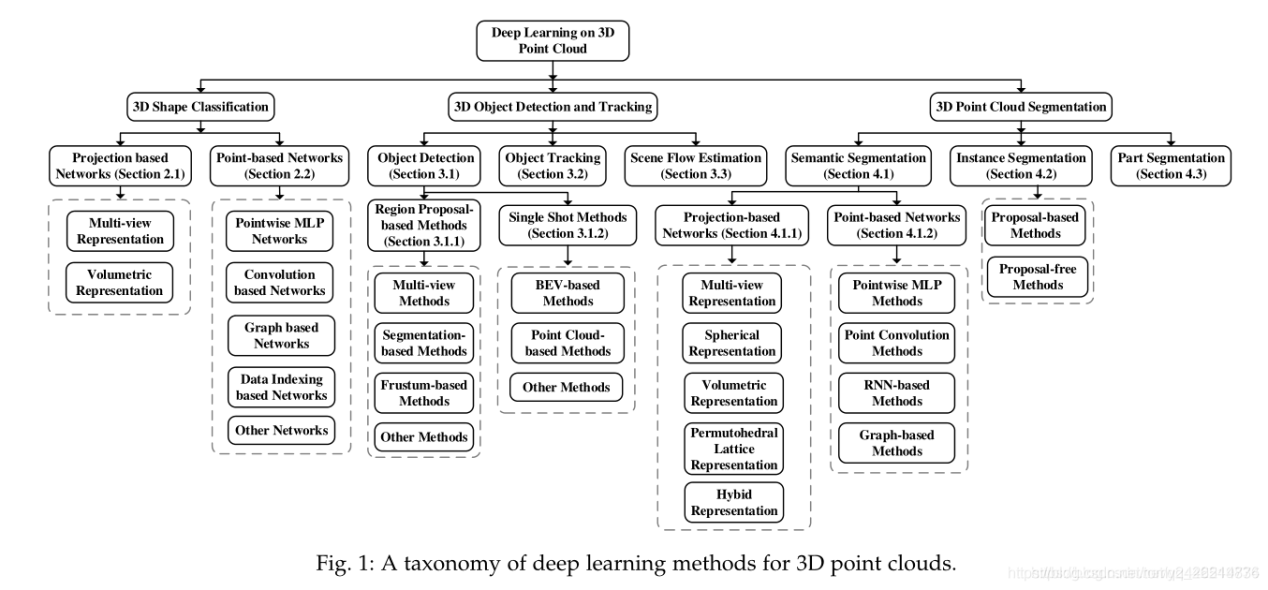
图1:三维点云深度学习方法的分类
与现有的文献相比,这项工作的主要贡献被总结如下:
1) 第一篇全面涵盖几个重要点云相关任务的深度学习方法的调查论文,包括三维形状分类、三维目标检测和跟踪以及三维点云分割。
2) 相对于现有的综述[19]、[20],我们特别专注于3D点云的深度学习方法而不是所有类型的3D数据。
3) 本文涵盖了点云上深度学习的最新的和最先进的进展。因此,它为读者提供了最先进的方法。
4) 现有方法在几个公开的数据集上的综合比较是被提供(如表2、3、4、5),并附有简短的摘要和有见地的讨论说明。
本文的结构如下。第二节介绍了对应任务的数据集和评估指标。第3节回顾了3D形状分类。第4节提供了对现有3D物体检测和跟踪的方法。第五节介绍了点云分割的方法综述。包括语义分割、实例分割和部件分割。最后,第6节总结了该文。我们还提供了一个定期更新的项目页面:https://github.com/QingyongHu/SoTA-Point-Cloud.
2、背景
2.1 数据集
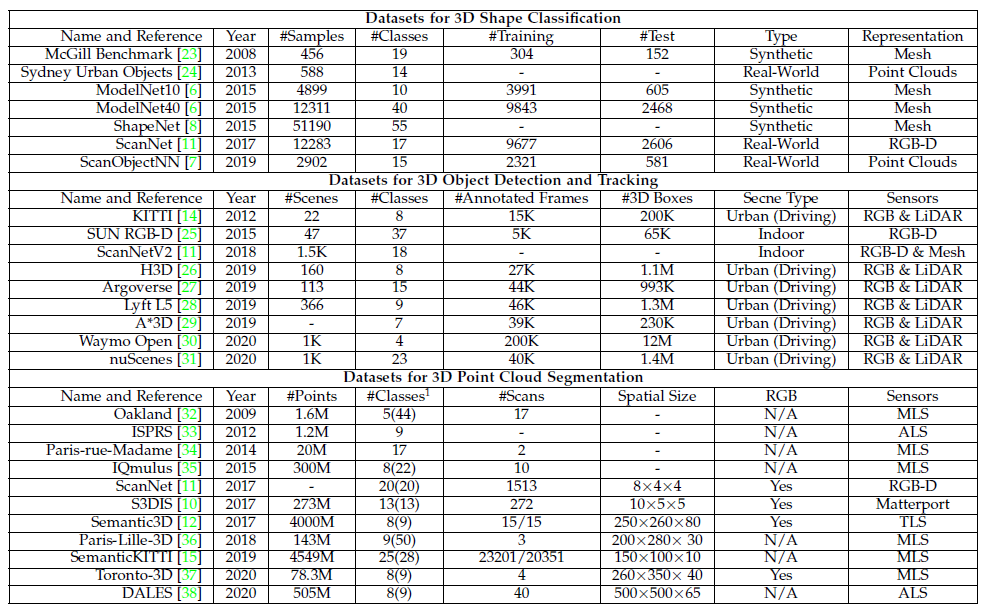
已经收集了大量的数据集,以便评估深度学习算法在不同的3D点云应用的性能。表1列出了一些典型的数据集用于三维形状分类、三维对象检测和跟踪,以及三维点云分割。尤其是,还总结了这些数据集的属性。
对于三维形状分类,有两种类型的数据集:合成数据集[6]、[8]和现实世界的数据集。[7], [11]. 合成数据集中的对象是完整的,没有任何遮挡和背景。相反,物体在现实世界的数据集中,在不同的层次上被遮挡住了和一些物体被背景噪音污染。
对于三维物体的检测和跟踪,有两种类型的数据集:室内场景[11]、[25]和户外城市场景[14]、[28]、[30]、[31]。室内的点云数据集是由密集的深度图转换而来,或者是从三维网格中采样而来。户外城市数据集是为自动驾驶而设计,其中物体在空间上是分离良好的,这些点云是稀疏的。
对于3D点云分割,这些数据集的获取方式是通过不同类型的传感器,包括移动激光扫描仪(MLS)[15], [34], [36], 航空激光扫描仪(ALS)[33]、[38]、静态地面激光扫描仪(TLS)[12]、RGBD摄像机[11]和其他3D扫描仪[10]。这些数据集可用于开发应对各种挑战的算法,包括类似的干扰因素、形状不完整和类别不平衡。
表1.三维形状分类、三维物体检测和跟踪以及三维点云的现有数据集汇总。用于评价的类数和注释类数(用括号表示)
2.2评价指标
有人提出了不同的评价指标来测试这些用于各种点云理解任务的方法。对于三维形状分类,总体准确度(OA)和平均类别准确率(mAcc)是最常用的性能。标准。'OA'代表所有测试实例的平均准确度。而'mAcc'代表的是所有形状类的平均准确率。对于三维物体检测,平均精度(AP)是最常用的标准。它的计算方法是精度-召回曲线下的面积。精度和成功率通常用于评估三维单物体跟踪器的整体性能。平均多物体跟踪准确率(AMOTA)和平均多目标跟踪精度(AMOTP)是3D多物体跟踪评估的最常用的标准。对于三维点云分分割、OA、平均交叉点单元(mIoU)和平均类别精度(mAcc)[10]、[12]、[15]、[36]、[37]为最常用的绩效评估标准。尤其是,平均准确率精度(mAP)[39]也被用于3D点云的实例分割。
3、3D点云分割
三维点云分割既需要了解全局几何结构,又需要了解每个点的细粒度细节。根据分割粒度,三维点云分割方法可以分为三类:语义分割(场景级)、实例分割(对象级)和部分分割(部件级)。
3.1 3D语义分割
对于给定的点云,语义分割的目标是根据点的语义意义将其划分为多个子集。与三维形状分类的分类方法类似(第3节),语义分割有四种范式:基于投影的方法、基于离散的方法、基于点的方法和混合方法。
基于投影和离散化方法的第一步都是将点云转换为中间规则表示,如多视图[181],[182],球形[183],[184],[185],体积 [166],[186],[187]、泛面体晶格[188]、[189]和混合表示法[190]、[191],如图11所示。然后中间分割结果被投影回原始点云。相反,基于点的方法直接工作在不规则的点云上。几种典型的方法如图10所示。
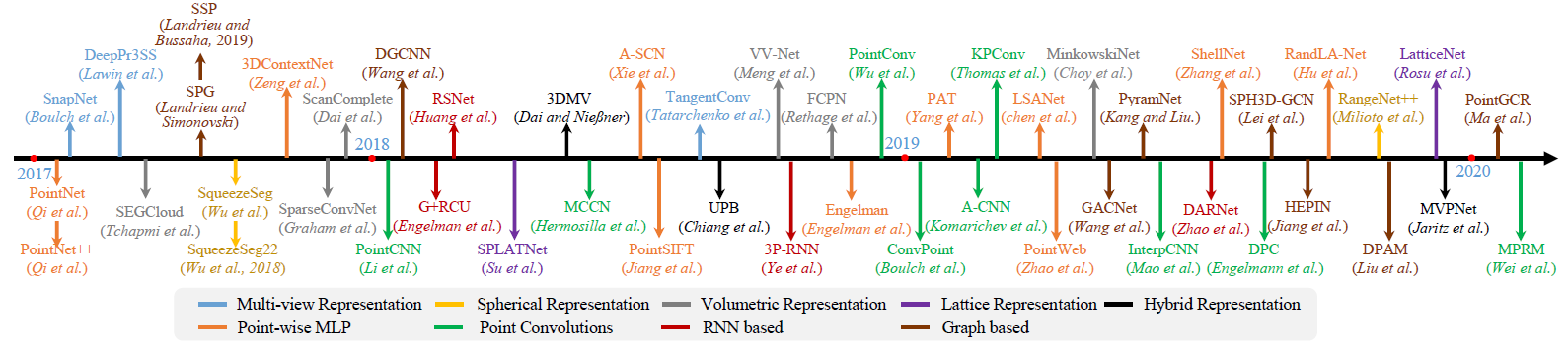
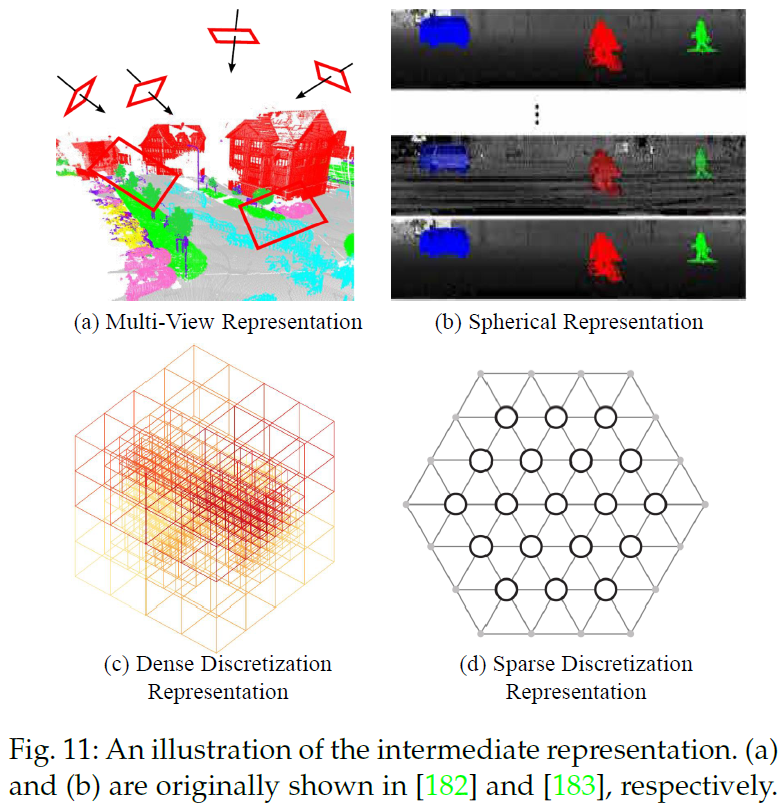
3.1.1 基于投影的方法
这些方法通常将三维点云投影到二维图像中,包括多视图和球形图像。
多视图表示
Lawin等人[181]首先从多个虚拟摄像机视图将3D点云投影到2D平面上。然后,使用多流FCN来预测合成图像的像素级评分。通过融合不同视图上的重投影得分,得到各点的最终语义标签。类似地,Boulch等人[182]首先使用多个摄像机位置生成了多个RGB和深度的点云快照。然后,他们使用二维分割网络对这些快照的像素进行标记。从RGB图像和深度图像预测的分数通过残差校正进一步融合[192]。基于点云是在局部欧几里得曲面采样的假设,Tatarchenko等[193]引入了切卷积来分割密集点云。该方法首先将每个点周围的局部曲面几何投影到一个虚拟切平面上。然后直接在曲面几何上操作切卷积。该方法具有良好的可扩展性,能够处理具有数百万点的大规模点云。总体而言,多视图分割方法的性能对视点选择和遮挡情况比较敏感。此外,这些方法没有充分利用隐含的几何和结构信息,投影步骤不可避免地会引入信息丢失。
球形表示
为了实现对三维点云的快速、准确分割,Wu等[183]提出了一种基于SqueezeNet[194]和条件随机场(CRF)的端到端网络。为了进一步提高分割精度,引入了SqueezeSegV2[184],利用无监督域适应管道来解决域偏移。Milioto等人[185]提出了RangeNet++用于激光雷达点云的实时语义分割。首先将二维范围图像的语义标签转移到三维点云中,然后采用基于gpu的高效的knn后处理步骤来缓解离散化误差和推理输出模糊的问题。与单视图投影相比,球面投影保留了更多的信息,适合于激光雷达点云的标记。但是,这种中间表示不可避免地带来离散化误差和遮挡等问题。
3.1.2 基于离散的方法
这些方法通常将点云转换为稠密/稀疏的离散表示,如体积格和稀疏透面体格。
稠密离散表示
早期的方法通常将点云体素化为密集的网格,然后利用标准的3D卷积。Huang等人[195]首先将一个点云划分为一组占用体素,然后将这些中间数据输入到一个全三维CNN进行体素分割。最后,一个体素内的所有点被赋予与该体素相同的语义标签。该方法的性能受到体素粒度和点云分区造成的边界伪影的严重限制。此外,Tchapmi等人[196]提出了SEGCloud来实现细粒度和全局一致的语义分割。该方法引入了确定性三线性插值,将3D-FCNN[197]生成的粗体素预测映射回点云,然后使用全连接CRF(FC-CRF)来强制这些被推断的perpoint的空间一致性。Meng等人[186]引入了一种基于核的插值变分自编码器体系结构来编码每个体素内的局部几何结构。对每个体素使用RBFs代替二进制占用表示,以获得连续表示并捕获每个体素中点的分布。VAE进一步用于将每个体素内的点分布映射到一个紧凑的潜在空间。然后利用对称组和等价CNN实现鲁棒性特征学习。
由于3D CNN具有良好的可扩展性,基于体积的网络可以在不同空间大小的点云上自由训练和测试。在Fully-Convolutional点网络(FCPN)[187]首先从点云中分层抽象出不同层次的几何关系,然后使用3D卷积和加权平均池来提取特征并纳入远程依赖关系。该方法可以处理大规模点云,具有良好的推理可扩展性。Dai[198]提出了ScanComplete来实现3D扫描补全和每个体素语义标记。该方法充分利用了全卷积神经网络的可扩展性,能够在训练和测试中适应不同的输入数据大小。采用由粗到细的分级策略,提高了预测结果的层次性。
总的来说,体积表示自然地保留了3D点云的邻域结构。其常规数据格式也允许直接应用标准3 d卷积。这些因素导致该领域的性能稳步提高。然而,体素化步骤本身就会引入离散化误差和信息丢失。通常,高分辨率导致高内存和计算成本,而低分辨率导致细节丢失。在实践中,选择合适的网格分辨率并非易事。
稀疏的离散表示
体积表示自然是稀疏的,因为非零值的数量只占很小的百分比。因此,在空间稀疏数据上应用密集卷积神经网络是低效的。为此,Graham等人[166]提出了基于索引结构的子流形稀疏卷积网络。该方法将卷积的输出限制为只与被占用的体素相关,从而大大降低了内存和计算成本。同时,其稀疏卷积也可以控制提取特征的稀疏性。这种submanifold sparse convolution适用于高维和空间稀疏数据的高效处理。此外,Choy等人[199]提出了一种名为MinkowskiNet的用于3D视频感知的4D时空卷积神经网络。为了有效地处理高维数据,提出了一种广义稀疏卷积算法。进一步应用三边平稳条件随机场加强一致性。
另一方面,Su等[188]基于双边卷积层提出了稀疏晶格网络(SPLATNet)。该方法首先将一个原始点云插值到一个泛面体稀疏点阵中,然后应用BCL对稀疏点阵中被占用的部分进行卷积。然后,过滤后的输出被插值回原始点云。此外,该方法可以灵活地对多视图图像和点云进行联合处理。此外,Rosu等人[189]提出了LatticeNet来实现对大点云的高效处理。此外,还引入了一个名为DeformsSlice的数据相关插值模块,将点阵特征反向投影到点云上。
3.1.3 混合方法
为了进一步利用所有可用的信息,提出了几种方法来学习来自3 d扫描的多模态特征。Dai和Niener[190]提出了一种结合RGB特征和几何特征的联合3d多视图网络。利用一个3D CNN流和多个二维流来提取特征,提出了可微的反向投影层来共同的融合学习到的二维嵌入和三维几何特征。此外,Chiang等人[200]提出了一种统一的基于点的框架来学习二维纹理外观、点云的三维结构和全局上下文特征。该方法直接应用基于点的网络从稀疏采样的点集中提取局部几何特征和全局上下文,不进行任何体素化。Jaritz等人[191]提出了多视图pointnet (MVPNet),将二维多视图图像的外观特征和标准点云空间中的空间几何特征进行聚合。
3.1.4 基于点的方法
基于点的网络直接工作在不规则的点云上。然而,点云是无序的、非结构化的。使得直接应用标准CNNs不可行。为此,PointNet[5]提出了开创性的工作,利用共享MLPs学习每个点的特征,利用对称池化函数学习全局特征。在PointNet的基础上,最近提出了一系列基于点的网络。总的来说,这些方法大致可以分为基于点的MLP方法、点卷积方法、基于RNN的方法,以及基于图的方法。
逐点MLP方法
这些方法通常使用共享MLP作为其网络的基本单元,其效率高。然而,逐点特征提取通过共享MLP无法捕获点云的局部几何形状以及点[5]之间的相互作用。为了获取每个点更广泛的上下文并学习更丰富的局部结构,我们引入了一些专用网络,包括基于邻域特征池化、基于注意力的聚集和局部-全局特征连接的方法。

邻域特征池化:为了获取局部几何模式,这些方法通过对局部邻近点的信息进行聚合来获得每个点的特征。具体来说,pointnet++[54]将点分层分组,并逐步从更大的局部区域学习,如图12(a)所示。针对点云的不均匀性和密度变化等问题,提出了多尺度和多分辨率的分组方法。随后,Jiang等人[141]提出了一个PointSIFT模块来实现方向编码和尺度感知。该模块通过三级有序卷积将八个空间方向的信息堆叠并编码。多尺度特征被连接在一起以实现对不同尺度的自适应。与pointnet++中使用的分组技术(即球查询)不同,Engelmann等[204]利用K-means聚类和KNN分别定义了世界空间和特征空间中的两个邻域。基于期望来自同一类的点在特征空间中更接近的假设,引入两两距离损失和质心损失来进一步规范特征学习。为了对不同点之间的相互作用进行建模,Zhao等[57]提出了PointWeb,通过密集地构建一个局部全链接的web来探索一个局部区域内所有点对之间的关系。提出了一个自适应特征调整(AFA)模块,实现了信息交换和特征细化。这种聚合操作有助于网络学习一种有判别性的特征表示。Zhang等人[205]提出了一种基于同心球壳统计量的置换不变卷积,称为Shellconv。该方法首先查询一组多尺度的同心球面,然后在不同的shell中使用max-pooling操作来总结统计,使用MLPs和1D卷积得到最终的卷积输出。Hu等人 [206]提出了一种高效的轻量级网络,称为用于大规模点云分割的RandLA-Net。该网络利用随机点采样,在内存和计算方面取得了非常高的效率。进一步提出了一种局部特征聚合模块来捕获和保存几何特征。
基于注意力的池化:为了进一步提高分割精度,在点云分割中引入了注意机制[120]。Yang等人[56]提出了一种group shuffle attention来建模点之间的关系,并提出了一种置换不变量、任务不可知且可微的Gumbel子集抽样(GSS)来替代广泛使用的FPS方法。该模块对异常值不太敏感,可以选择一个有代表性的点子集。为了更好地捕捉点云的空间分布,Chen等人[207]提出了一种基于空间布局和点云局部结构的局部空间感知(LSA)层来学习空间感知权值。类似于CRF, Zhao等[208]提出了一种基于注意力的评分细分(ASR)模块对网络产生的分割结果进行后处理。通过将相邻点的分数与学习到的注意权值相结合,对初始分割结果进行细化。这个模块可以很容易地集成到现有的深度网络,以提高分割性能。
局部-全局串联:Zhao等人[112]提出了一种置换不变的PS2-Net来结合点云的局部结构和全局上下文。Edgeconv[87]和NetVLAD[209]被反复堆叠,以捕捉局部信息和场景级的全局特征。
点卷积方法
这些方法往往提出了针对点云的有效卷积算子。Hua等人[76]提出了一种逐点卷积算子。其中相邻的点被分到了核单元中,然后用核权重进行卷积。如图所示 图12(b)中,Wang等人[201]提出了一种基于参数化连续卷积层的PCCN。该层的核函数参数为 MLPs并跨越连续向量空间。Thomas等人 [65] 基于核点卷积(KPConv)提出了一种核点全卷积网络(KP-FCNN)。具体来说,KPConv的卷积权重由核点的欧氏距离决定,核点的数量不固定。核点的位置被表述为一个在球体空间的最佳覆盖范围的优化问题。注意,半径邻域是用来保持一致的感受野。而在每层中采用网格子采样,以实现不同密度的点云下的高鲁棒性。在[211]中,Engelmann等人提供了丰富的消融实验和可视化结果,以显示感受野对基于聚合方法性能的影响。他们还提出了一种膨胀点卷积(DPC)操作,以聚合膨胀的相邻特征,而不是K个最近的邻居。这种操作被证明在增加感受野方面非常有效,并且可以很容易地集成到现有的基于聚合的网络中。
基于RNN方法
为了从点云捕捉固有的上下文特征,循环神经网络(RNN) 也被用于点云的语义分割。基于PointNet[5],Engelmann等人[213]首次提出了 将一个点块转化为多尺度的块和网格块来获取输入级上下文。然后,由PointNet逐块提取的特征依次输入到综合单位(CU)或循环综合单位(RCU)来获取输出级上下文。实验结果表明,结合空间上下文对提高分割性能很重要。Huang等人[212]提出了一种轻量级的局部依赖性建模模块,并利用分片池化层将无序的点特征集变成一个有序的特征向量序列。如图12(c)所示,Ye等人[202]先是 提出了一个逐点金字塔池(3P)模块,以捕获由粗到细的局部结构,然后利用双向的分层RNNs,以进一步获得长距离的空间依赖性,然后应用RNN来实现端到端的学习。
然而,当聚合局部邻域特征与全局结构特征[220]时,这些方法失去了丰富的几何特征和点云的密度分布。为了缓解这些由刚性和静态池化操作引起的问题,赵等 [220] 考虑到全局的场景复杂性和局部的几何特征,提出了一种动态聚合网络(DARNet)。中间的特征是使用自适应的感受野和节点权重动态被聚合的。Liu等[221]提出了3DCNN-DQN-RNN用于大规模点云的高效语义解析。该网络首先使用3D CNN网络学习了空间分布和颜色。DQN被进一步用于定位属于特定类的目标。最后将拼接后的特征向量送入残差RNN,得到最终的分割结果。
基于图方法
为了捕捉三维点云的底层形状和几何结构,有几种方法借助于图网络。如图12(d)所示,Landrieu等[203]将点云表示为一组相互连接的简单形状和超点,并采用归属定向图(即超点图)来捕捉结构和上下文信息。然后,将大规模的点云分割问题拆分为三个子问题,即几何均匀分区、超点嵌入和上下文分割。为了进一步改进分割步骤,Landrieu和Boussaha[214]提出了一种监督框架来对点进行超点分割。这个问题被表述为一个深度度量学习问题,其结构是由一个相邻的图构成。此外,还提出了一种图结构对比损失,以帮助识别目标与目标之间的边界。
为了在高维空间更好地把握局部几何关系, Kang等人[222] 基于图嵌入模块(GEM)和金字塔注意力网络(PAN)提出了一个PyramNet。GEM模块将点云构建为有向无环图,并使用协方差矩阵代替欧氏距离构建相邻相似度矩阵。PAN模块中使用了四种不同大小的卷积核,以提取具有不同语义强度的特征。在 [215]中,提出了图注意力卷积(GAC),用于 有选择地从局部邻域学习相关特征。该操作是通过根据相邻点和特征通道的空间位置和特征差异动态分配注意权值来实现的。GAC可以学习捕获有区分性的特征用于分割,并且与常用的CRF模型具有相似的特征。Ma等人[223]提出了一种Point Global Context Reasoning(PointGCR)模块,沿着通道维度使用非定向图表示以获取全局上下文信息。PointGCR是一个即插即用、端到端可训练的模块。它可以轻松地纳入现有的分割网络,以实现性能提升。
此外,最近的几项工作试图在弱监督下实现点云的语义分割。Wei等人[224]提出了一种两阶段的方法来训练具有子云级标签的分割网络。Xu等人[225]研究了几种用于点云语义分割的不精确监督方案。他们还提出了一个能够只用部分标签点(如10%)进行训练的网络。
3.2 实例分割
与语义分割相比,实例分割需要更精确、更精细的点推理,具有更大的挑战性。具体来说,既要区分语义意义不同的点,又要区分语义意义相同的实例。总的来说,现有的方法可以分为两类:基于候选框(based-proposal)的方法和不需要候选框(proposal-free)的方法。图13说明了几种里程碑方法。
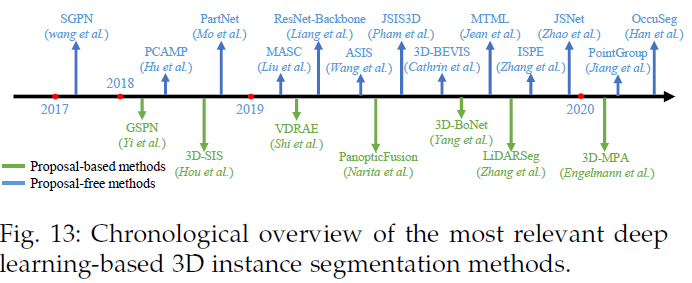
3.2.1 基于候选框的方法
这些方法将实例分割问题转化为两个子任务:三维对象检测和实例掩码预测。
Hou等人[226]提出了一种3D全卷积语义实例分割(3D-SIS)网络实现对RGB-D扫描的语义实例分割。这个网络可以从颜色和几何特征中学习。类似于3D对象检测,3D Region Proposal Network (3DRPN)和3D ROI layer (3D-RoI)层被用来预测边界框位置、物体类别标签和实例掩码。按照分析综合的策略,Yi等人[227]提出了Generative Shape Proposal Network(GSPN)来产生3D候选框。这些候选框由一个Region-based PointNet(R-PointNet)进一步修正。最终的标签通过预测各个点的二进制mask来得到。与直接从点云数据回归三维边界框不同,该方法通过加强几何理解,去除了大量无用的候选框。
通过将2D全景分割( 2D panoptic segmentation)扩展到3D映射,[228]为实现大规模三维重建(3D reconstruction)、语义标注(semantic labeling)和实例分割(instance segmentation),提出了一种在线体素三维映射系统(oneline volumetirc 3D mapping system)。该方法首先利用2D语义和实例分割网络来获得像素级的全景标签(panoptic labels ),然后将这些标签整合到volumtric map上。进一步使用全连接的CRF来实现准确的分割,该语义映射系统能够实现高质量的语义映射和具有判别性的目标检测。Yang等人[229]提出了一种称为3D-BoNet的单阶段、无anchor、端到端可训练的网络来实现点云上的实例分割。该方法对所有潜在实例直接回归粗糙的三维边界盒,然后利用点级别的二值分类器获得实例标签。特别地,将边界盒生成问题表述为最优分配问题。此外,还提出了一个多准则损失函数来规范生成的边界盒。该方法不需要任何后处理,在计算上非常有效。Zhang等人[230]提出了一种用于大规模户外激光雷达点云的实例分割网络。该方法利用自注意块学习点云鸟瞰图的特征表示。基于预测的水平中心和高度限制,得到最终的实例标签。Shi等人[231]提出了一种分层感知的变分去噪递归自动编码器(VDRAE)去预测室内三维空间布局。目标候选框是通过递归上下文聚合和传播来迭代生成和细化的。
总体而言,基于候选框的方法[226]、[227]、[229]、[232]直观和简单的,实例分割结果通常具有较好的客观性。然而,这些方法需要多阶段的训练和修剪冗余的候选框。因此,它们通常是耗时和计算昂贵的。
3.2.2 不需要候选框的方法
不需要候选框的方法[233],[234],[235],[236],[237],[238],[239],[240]没有目标检测模块。相反,他们通常认为实例分割是语义分割之后的后续聚类步骤。特别是,大多数现有的方法都基于这样的假设:属于同一实例的点应该具有非常相似的特性。因此,这些方法主要集中在区分特征学习和点分组上。
在一项开创性的工作中,Wang等人[233]首次引入了相似组候选框网络(SGPN)。该方法首先学习每个点的特征和语义映射,然后引入相似度矩阵来表示每对特征之间的相似度。为了学习更具判别性的特征,他们使用double-hinge loss来相互调整相似度矩阵和语义分割结果。最后,采样一种启发式和非最大抑制法将相似点合并成实例。由于构建相似度矩阵需要消耗大量的内存,这种方法的可扩展性是有限的。同样,Liu等人[237]首次利用leveraged submanifold sparse convolution [166]来预测每一个体素的语义得分,以及邻近体素之间的亲和力。然后,他们引入了一个聚类算法,基于预测的亲和力和mesh拓扑结构将点分为实例。Mo等人[241]在PartNet中引入了一个逐段检测网络来实现实例分割。PointNet++被用作的骨干来预测每个点的语义标签和不相干的实例掩码。此外,Liang等人[238]提出了一种用于学习判别性嵌入的结构感知损失。这种损失既考虑了特征的相似性,又考虑了点之间的几何关系。基于注意力的图CNN通过聚合来自不同的邻居信息,被进一步用于自适应地完善学到的特征。
由于点的语义类别和实例标签通常是相互依赖的,因此提出了几种方法将这两个任务耦合为一个任务。Wang等[234]通过引入一个端到端的、可学习的联合分割实例和语义(Associatively Segmenting Instances and Semantics,ASIS)模块,将这两个任务进行了整合。实验表明,语义特征和实例特征可以相互支持,通过这个ASIS模块实现性能的提升。类似地,Zhao等人[242]提出了JSNet来实现语义和实例分割。此外,Pham等[235]首次引入了多任务逐点网络(MT-PNet),将标签分配给每个点,通过引入了一个判别性损失在特征空间中正则化嵌入 [243]。然后他们把预测的语义标签和嵌入融合到一个多值条件随机场(MV-CRF)模型,用于联合优化。最后,均值场变分推理(mean-field variational inference)是用来产生语义标签和实例标签。Hu等人[244]首次提出了动态区域生长的 (DRG)方法,将点云动态地分离为一组不相交的补丁(patch),然后使用无监督的Kmeans++算法对所有这些补丁进行分组。然后在补丁之间的上下文信息的引导下进行多尺度补丁分割。最后,这些标记的补丁被合并到目标层,以获得最终的语义和实例标签。
为了在完整的3D场景上实现实例分割,Elich等人 [236]提出了一种混合的2D-3D网络,可以从BEV表示和点云的局部几何特征共同学习全局一致的实例特征。然后将学习到的特征进行组合以实现语义和实例分割。注意,不是启发式GroupMerging算法[233],而是更灵活的Meanshift [245]算法用于将这些点分组为实例。可替代地,还引入了多任务学习以进行实例分割。Lahoud等人[246]学习了每个实例的独特嵌入特征和估计目标中心的方向信息。提出了利用特征嵌入损失和方向损失来调整隐含特征空间中学习到的特征嵌入。采用Mean-shift聚类和非极大抑制将体素分组为实例。该方法可以达到ScanNet [11]基准的最新性能。此外,预测的方向信息对于确定实例的边界特别有用。zhang等 [247]将概率嵌入引入到点云的实例分割中。该方法还结合了不确定性估计,并为聚类步骤提出了新的损失函数。Jiang等[240]提出了一种PointGroup网络,它由一个语义分割分支和一个偏移量预测分支组成。进一步利用dual-set clustering算法和ScoreNet实现更好的分组结果。
总之,不需要候选框的方法不需要计算昂贵的区域候选框组件。然而,由于这些方法没有显式地检测对象边界,因此用这些方法分组的实例分割的客观性通常很低。
3.3 部件分割
三维形状的部件分割的困难有两方面。第一,具有相同语义标签的形状部件具有较大的几何变化和模糊性。其次,具有相同语义的对象中的部件数量可能是不同的。
VoxSegNet[248]是为了在有限的解决方案下实现对三维体素化数据的细粒度部件分割。提出了一个空间密集提取(SDE)模块(由stacked atrous residual blocks组成),用于从稀疏的体素数据中提取多尺度的判别特征。通过逐步应用注意力特征聚合(AFA)模块,进一步对学到的特征加权和融合。Kalogerakis等[249]将FCNs和基于表面的CRFs结合起来,实现了端到端的三维部件分割。他们首先从多个视图中生成图像,以达到最佳的表面覆盖率,并将这些图像输入到一个二维网络中以产生置信度图。然后,这些置信度图由基于表面的CRF聚合,CRF负责对整个场景进行一致的标记。Yi等[250]引入了一种同步频谱CNN(SyncSpecCNN)来对不规则和非同构形状图进行卷积。引入了膨胀卷积核和频谱变换网络的频谱参数化,解决了部件的多尺度分析和形状间的信息共享问题。
Wang等人[251]首先通过引入形状完全卷积网络(SFCN),并将三个低级几何特征作为其输入,对3D mesh进行形状分割。然后他们利用基于投票的多标签图切割来进一步完善分割结果。Zhu等人[252]提出了一种用于三维形状协同分割的弱监督CoSegNet。该网络将未分割的三维点云形状集合作为输入,通过迭代最小化群体一致性损失来产生形状部件标签。与CRF类似,提出了一个预训练的部件细化网络来进一步细化和去噪部件候选框。Chen等[253]提出了一种用于无监督、单样本和弱监督三维形状协同分割的分支自动编码器网络(BAE-NET)。该方法将形状共分割任务表述为一个表示学习问题,旨在通过最小化形状重建损失来寻找最简单的部件表示。基于编码器-解码器架构,该网络的每个分支都可以为特定的部件形状学习一个紧凑的表示。然后将从各支路学习到的特征和点坐标输入解码器,生成一个二进制值(表示该点是否属于该部分)。该方法具有良好的泛化能力,可处理大型三维形状集合(最多5000+形状)。但该方法对初始参数敏感,且没有将形状语义纳入网络中,使得该方法在每次迭代中都不能得到稳健稳定的估计。Yu等[254]提出了一种自上而下的递归部件分解网络(PartNet),用于层次化的形状分割。与现有方法将形状分割为固定的标签集不同,该网络将部件分割表述为级联二进制标签问题,并根据几何结构将输入点云分解为任意数量的部件。Luo等[255]针对零样本三维部件分割的任务,引入了一个基于学习的分组框架。为了提高跨类泛化能力,该方法倾向于学习分组策略,以限制网络在部件局部上下文中学习部件级特征。
3.4 总结
表5给出了现有方法在公共基准测试上的结果,包括S3DIS [10], Semantic3D [12],ScanNet [39], and SemanticKITTI [15]。需要进一步研究的问题有:
- 基于投影的方法和基于离散化的方法都可以利用二维图像的成熟网络结构,这得益于规律的数据表示。然而,基于投影的方法的主要局限性在于3D-2D投影所造成的信息损失,而基于离散的方法的主要瓶颈则在于增加解的计算和内存成本。为此,基于索引结构的稀疏卷积是一种可行的解决方案,值得进一步探索。
- 基于点的网络是最常研究的方法。然而,点表示法自然没有明确的邻域信息,现有的大多数基于点的方法都采用了昂贵的邻域搜索机制(如KNN[79]或球查询[54])。这在本质上限制了这些方法的效率,最近提出的点-体素联合表示法[256]将是一个有趣的进一步研究方向。
- 从不平衡的数据中学习仍然是点云分割中的一个具有挑战性的问题。虽然有一些方法[65]、[203]、[205]已经取得了可观的总体性能,但它们在少数类上的性能仍然有限。例如,RandLA-Net[206]在Semantic3D的reduced-8子集上实现了76.0%的总体IoU,但在人造景观类别上却只有41.1%的IoU。
- 现有的大多数方法[5]、[54]、[79]、[205]、[207]都是在小点云(如1m x 1m,4096个点)上工作。在实践中,深度传感器获取的点云通常是巨大的,而且是大规模的。因此,对大规模点云的有效分割问题进行深入研究是很有必要的。
- 少数文献[178]、[179]、[199]已经开始从动态点云中学习时空信息。期望时空信息能够帮助提高后续任务的性能,如三维物体的识别、分割和补全。

4、 结论
本文介绍了当前最先进的三维理解方法,包括三维形状分类,三维物体检测和跟踪,以及三维场景和目标分割。对这些方法进行了分类和性能比较。同时也介绍了各种方法的优缺点,并列出了可能的研究方向。
参考:
https://blog.csdn.net/tomy2426214836/article/details/106975196
https://blog.csdn.net/john_bh/article/details/103804177
2020国防科大综述:3D点云深度学习——综述(3D点云分割部分)的更多相关文章
- 2020国防科大综述:3D点云深度学习—综述(点云形状识别部分)
目录 摘要 1.引言: 2.背景 2.1 数据集 2.2评价指标 3.3D形状分类 3.1基于多视图的方法 3.2基于体素的方法 3.3基于点的方法 3.3.1 点对多层感知机方法 3.3.2基于卷积 ...
- 点云深度学习的3D场景理解
转载请注明本文链接: https://www.cnblogs.com/Libo-Master/p/9759130.html PointNet: Deep Learning on Point Sets ...
- 2020厦门大学综述翻译:3D点云深度学习(Remote Sensiong期刊)
目录 摘要 1.引言: 2.点云深度学习的挑战 3.基于结构化网格的学习 3.1 基于体素 3.2 基于多视图 3.3 高维晶格 4.直接在点云上进行的深度学习 4.1 PointNet 4.2 局部 ...
- 深度学习综述(LeCun、Bengio和Hinton)
原文摘要:深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示.这些方法在很多方面都带来了显著的改善,包含最先进的语音识别.视觉对象识别.对象检測和很多其他领域,比如药物发现和基 ...
- 腾讯优图&港科大提出一种基于深度学习的非光流 HDR 成像方法
目前最好的高动态范围(HDR)成像方法通常是先利用光流将输入图像对齐,随后再合成 HDR 图像.然而由于输入图像存在遮挡和较大运动,这种方法生成的图像仍然有很多缺陷.最近,腾讯优图和香港科技大学的研究 ...
- 【深度学习】:一门入门3D计算机视觉
一.导论 目前深度学习已经在2D计算机视觉领域取得了非凡的成果,比如使用一张图像进行目标检测,语义分割,对视频当中的物体进行目标跟踪等任务都有非常不错的效果.传统的3D计算机视觉则是基于纯立体几何来实 ...
- ApacheCN 深度学习译文集 2020.9
协议:CC BY-NC-SA 4.0 自豪地采用谷歌翻译 不要担心自己的形象,只关心如何实现目标.--<原则>,生活原则 2.3.c 在线阅读 ApacheCN 面试求职交流群 72418 ...
- 走近深度学习,认识MoXing:初识华为云ModelArts的王牌利器 — MoXing
[摘要] 本文为MoXing系列文章第一篇,主要介绍什么是MoXing,MoXing API的优势以及MoXing程序的基本结构. MoXing的概念 MoXing是华为云深度学习服务提供的网络模型开 ...
- 人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手] 1. 分享个人对于人工智能领域的算法综述:如果你想开始学习算法,不妨先了解人工 ...
随机推荐
- NOIP模拟测试14「旋转子段·走格子·柱状图」
旋转子段 连60分都没想,考试一直肝t3,t2,没想到t1最简单 我一直以为t1很难,看了题解发现也就那样 题解 性质1 一个包含a[i]旋转区间值域范围最多为min(a[i],i)----max(a ...
- Mysql优化(出自官方文档) - 第十二篇(优化锁操作篇)
Mysql优化(出自官方文档) - 第十二篇(优化锁操作篇) 目录 Mysql优化(出自官方文档) - 第十二篇(优化锁操作篇) 1 Internal Locking Methods Row-Leve ...
- 4.6 Python3 进阶 - 递归函数
>>返回主目录 源码 # 定义及特性 # 简单递归思维练习,求和:1+2+3+-+100 # 思路:sum(100) = sum(99) + 100 # sum(99) = sum(98) ...
- centos7 system自定义服务
1.介绍 centos中service命令与/etc/init.d的关系 service httpd start 其实是启动了存放在/etc/init.d目录下的脚本. 但是centos7的服务管 ...
- 温故知新,DotNet Core SDK和.Net CLI十八般武艺
简介 .NET命令行接口 (CLI) 工具是用于开发.生成.运行和发布.NET应用程序的跨平台工具链. https://docs.microsoft.com/zh-cn/dotnet/core/too ...
- .obj : error LNK2019: 无法解析的外部符号
记录一个报错 .obj : error LNK2019: 无法解析的外部符号 "public: void __thiscall 习惯上先去看看 | "#include"语 ...
- 4、saltstack的使用
官方文档地址:http://repo.saltstack.com/#rhel 4.1.saltstatck介绍: 用户要一致,这里使用的是root用户: 用于批量管理成百上千的服务器: 并行的分发,使 ...
- 39、mysql数据库(视图)
39.1.视图: 0.创建表及插入数据: 1.创建teacher表及插入数据: (1)创建表: CREATE TABLE teacher( tid int PRIMARY KEY auto_incre ...
- [小技巧] Windows7 半角全角快捷键 修改方法
From : http://blog.sina.com.cn/s/blog_87ab67b10100x3ww.html 转载说明:在浏览器下我们可以使用空格下翻一页,Shift + 空格上翻一页. 但 ...
- buu 刮开有奖
一.查壳, 二.拖入ida,分析 直接搜字符串完全没头绪,在看了大佬的wp才找到了,关键函数. 明显那个String就是我们要求的flag,要开始分析程序. 字符串长度为8,同时这个函数对字符串进行了 ...