大数据开发-Flink-窗口全解析
Flink窗口背景
Flink认为Batch是Streaming的一个特例,因此Flink底层引擎是一个流式引擎,在上面实现了流处理和批处理。而Window就是从Streaming到Batch的桥梁。通俗讲,Window是用来对一个无限的流设置一个有限的集合,从而在有界的数据集上进行操作的一种机制。流上的集合由Window来划定范围,比如“计算过去10分钟”或者“最后50个元素的和”。Window可以由时间(Time Window)(比如每30s)或者数据(Count Window)(如每100个元素)驱动。DataStream API提供了Time和Count的Window。
一个Flink窗口应用的大致骨架结构如下所示:
// Keyed Window
stream
.keyBy(...) <- 按照一个Key进行分组
.window(...) <- 将数据流中的元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
// Non-Keyed Window
stream
.windowAll(...) <- 不分组,将数据流中的所有元素分配到相应的窗口中
[.trigger(...)] <- 指定触发器Trigger(可选)
[.evictor(...)] <- 指定清除器Evictor(可选)
.reduce/aggregate/process() <- 窗口处理函数Window Function
Flink窗口的骨架结构中有两个必须的两个操作:
- 使用窗口分配器(WindowAssigner)将数据流中的元素分配到对应的窗口。
- 当满足窗口触发条件后,对窗口内的数据使用窗口处理函数(Window Function)进行处理,常用的Window Function有
reduce、aggregate、process
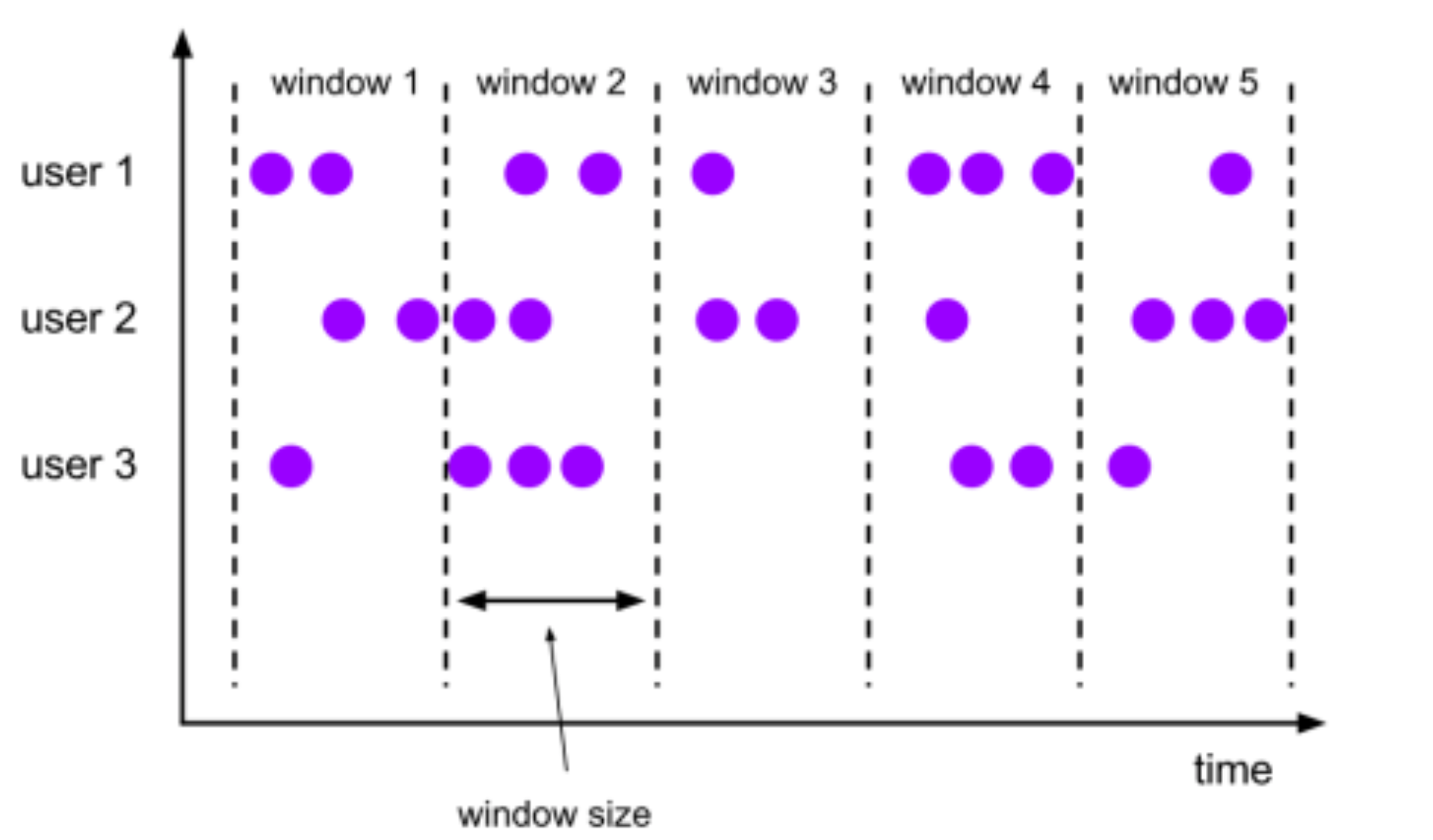
滚动窗口
基于时间驱动
将数据依据固定的窗口长度对数据进行切分,滚动窗口下窗口之间之间不重叠,且窗口长度是固定的。我们可以用TumblingEventTimeWindows和TumblingProcessingTimeWindows创建一个基于Event Time或Processing Time的滚动时间窗口。窗口的长度可以用org.apache.flink.streaming.api.windowing.time.Time中的seconds、minutes、hours和days来设置。
//关键处理案例
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = mapStream.keyBy(0);
// 基于时间驱动,每隔10s划分一个窗口
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> timeWindow =
keyedStream.timeWindow(Time.seconds(10));
// 基于事件驱动, 每相隔3个事件(即三个相同key的数据), 划分一个窗口进行计算
// WindowedStream<Tuple2<String, Integer>, Tuple, GlobalWindow> countWindow =
keyedStream.countWindow(3);
// apply是窗口的应用函数,即apply里的函数将应用在此窗口的数据上。
timeWindow.apply(new MyTimeWindowFunction()).print();
// countWindow.apply(new MyCountWindowFunction()).print();
基于事件驱动
当我们想要每100个用户的购买行为作为驱动,那么每当窗口中填满100个”相同”元素了,就会对窗口进行计算,很好理解,下面是一个实现案例
public class MyCountWindowFunction implements WindowFunction<Tuple2<String, Integer>,
String, Tuple, GlobalWindow> {
@Override
public void apply(Tuple tuple, GlobalWindow window, Iterable<Tuple2<String, Integer>>
input, Collector<String> out) throws Exception {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
int sum = 0;
for (Tuple2<String, Integer> tuple2 : input){
sum += tuple2.f1;
}
//无用的时间戳,默认值为: Long.MAX_VALUE,因为基于事件计数的情况下,不关心时间。
long maxTimestamp = window.maxTimestamp();
out.collect("key:" + tuple.getField(0) + " value: " + sum + "| maxTimeStamp :"+ maxTimestamp + "," + format.format(maxTimestamp)
);
}
}
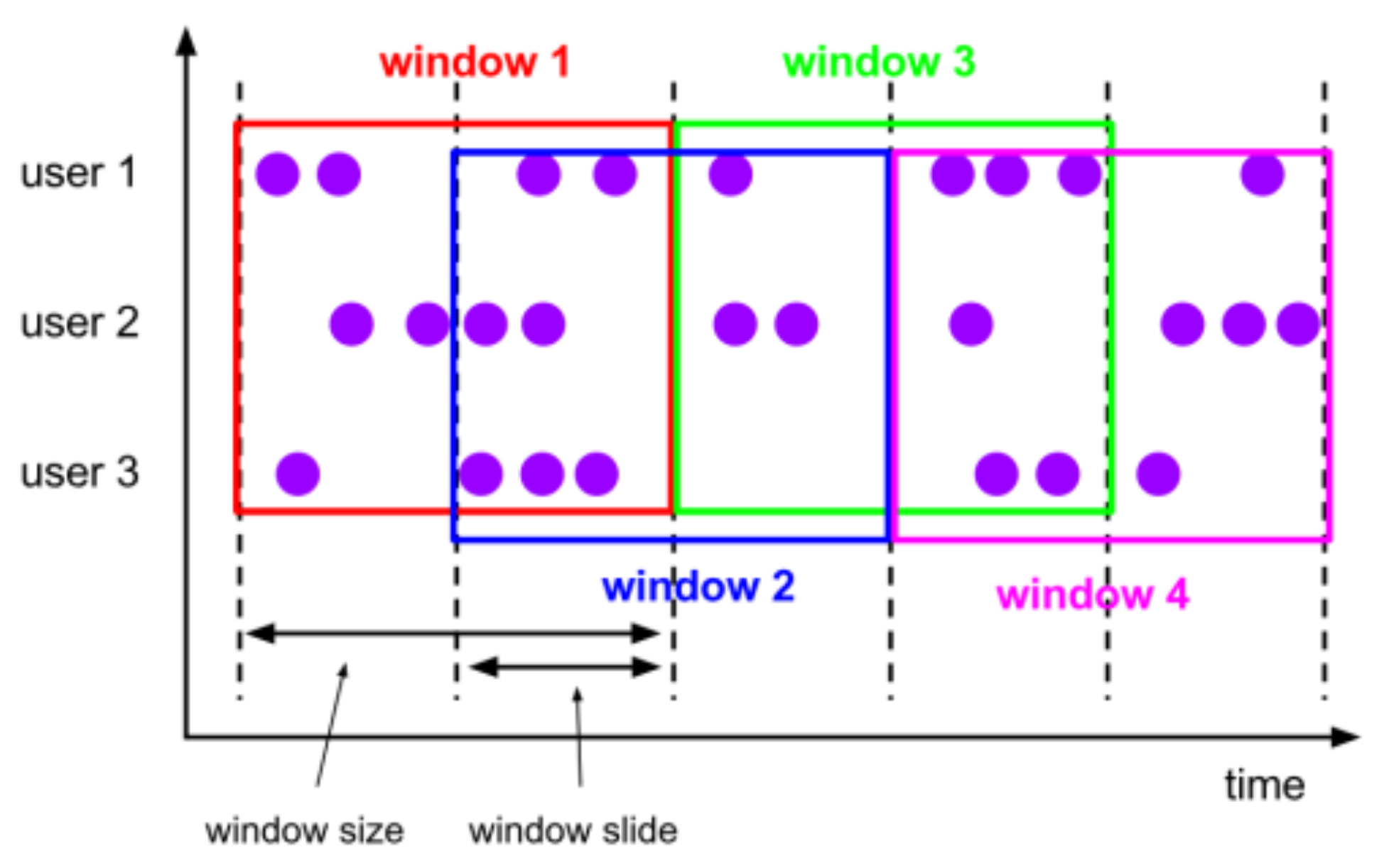
滑动时间窗口
动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成,特点:窗口长度固定,可以有重叠,滑动窗口以一个步长(Slide)不断向前滑动,窗口的长度固定。使用时,我们要设置Slide和Size。Slide的大小决定了Flink以多大的频率来创建新的窗口,Slide较小,窗口的个数会很多。Slide小于窗口的Size时,相邻窗口会重叠,一个事件会被分配到多个窗口;Slide大于Size,有些事件可能被丢掉
基于时间的滚动窗口
//基于时间驱动,每隔5s计算一下最近10s的数据
// WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> timeWindow =
keyedStream.timeWindow(Time.seconds(10), Time.seconds(5));
SingleOutputStreamOperator<String> applyed = countWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, GlobalWindow>() {
@Override
public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception {
Iterator<Tuple3<String, String, String>> iterator = input.iterator();
StringBuilder sb = new StringBuilder();
while (iterator.hasNext()) {
Tuple3<String, String, String> next = iterator.next();
sb.append(next.f0 + ".." + next.f1 + ".." + next.f2);
}
// window.
out.collect(sb.toString());
}
});
基于事件的滚动窗口
/**
* 滑动窗口:窗口可重叠
* 1、基于时间驱动
* 2、基于事件驱动
*/
WindowedStream<Tuple3<String, String, String>, String, GlobalWindow> countWindow = keybyed.countWindow(3,2);
SingleOutputStreamOperator<String> applyed = countWindow.apply(new WindowFunction<Tuple3<String, String, String>, String, String, GlobalWindow>() {
@Override
public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, String>> input, Collector<String> out) throws Exception {
Iterator<Tuple3<String, String, String>> iterator = input.iterator();
StringBuilder sb = new StringBuilder();
while (iterator.hasNext()) {
Tuple3<String, String, String> next = iterator.next();
sb.append(next.f0 + ".." + next.f1 + ".." + next.f2);
}
// window.
out.collect(sb.toString());
}
});
会话时间窗口
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口,在这种模式下,窗口的长度是可变的,每个窗口的开始和结束时间并不是确定的。我们可以设置定长的Session gap,也可以使用SessionWindowTimeGapExtractor动态地确定Session gap的长度。
val input: DataStream[T] = ...
// event-time session windows with static gap
input
.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<window function>(...)
// event-time session windows with dynamic gap
input
.keyBy(...)
.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[T] {
override def extract(element: T): Long = {
// determine and return session gap
}
}))
.<window function>(...)
// processing-time session windows with static gap
input
.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(10)))
.<window function>(...)
// processing-time session windows with dynamic gap
input
.keyBy(...)
.window(DynamicProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor[T] {
override def extract(element: T): Long = {
// determine and return session gap
}
}))
.<window function>(...)
窗口函数
在窗口划分完毕后,就是要对窗口内的数据进行处理,一是增量计算对应reduce 和aggregate,二是全量计算对应process ,增量计算指的是窗口保存一份中间数据,每流入一个新元素,新元素与中间数据两两合一,生成新的中间数据,再保存到窗口中。全量计算指的是窗口先缓存该窗口所有元素,等到触发条件后对窗口内的全量元素执行计算
参考
https://cloud.tencent.com/developer/article/1584926
吴邪,小三爷,混迹于后台,大数据,人工智能领域的小菜鸟。
更多请关注

大数据开发-Flink-窗口全解析的更多相关文章
- 拼多多大数据开发工程师SQL实战解析
不久前,裸考国内知名电商平台拼多多的大数据岗位在线笔试,问答题(写SQL)被虐的很惨,完了下来默默学习一波.顺便借此机会复习一下SQL语句的用法. 本文主要涉及到的SQL知识点包括CREATE创建数据 ...
- BAT推荐免费下载JAVA转型大数据开发全链路教程(视频+源码)价值19880元
如今随着环境的改变,物联网.AI.大数据.人工智能等,是未来的大趋势,而大数据是这些基石,万物互联,机器学习都是大数据应用场景! 为什么要学习大数据?我们JAVA到底要不要转型大数据? 好比问一个程序 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- 2019春招——Vivo大数据开发工程师面经
Vvio总共就一轮技术面+一轮HR面,技术面总体而言,比较宽泛,比较看中基础,面试的全程没有涉及简历上的东西(都准备好跟他扯项目了,感觉是抽取的题库...)具体内容如下: 1.熟悉Hadoop哪些组件 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
随机推荐
- poj_3617 解题
题意: 给定长度为N的字符串S,要构造一个长度为N的字符串T串. 从S的头部删除一个字符,加到T的尾部 从S的尾部删除一个字符,加到T的尾部 目标是构造字典序尽可能小的字符串. 示例输入: ACDBC ...
- 把握好集成测试大关,ERP就成功了一大半
欢迎关注微信公众号:sap_gui (ERP咨询顾问之家) 前段时间收到一个朋友的信息,说他们目前正在实施ERP系统,已经到了集成测试环节了,但整个测试过程下来并不是太理想,很多接口不通,功能也还在开 ...
- C++介绍和class的介绍
课程介绍 程序设计II是程序设计I的延续,继续提高编程能力,并能掌握面向对象(Object Oriented Programming)的程序设计方法.所谓面向对象,指的是将具体的流程变得模块化.这可以 ...
- C语言基础知识错误总结
1. 以下选项中能表示合法常量的是( ). Select one: a. '\' b. 1.5E2.0 c. "\007" d. 1,200 Feedback The corre ...
- 1038 Recover the Smallest Number
Given a collection of number segments, you are supposed to recover the smallest number from them. Fo ...
- MyBatisPlus入门学习
目录 MyBatisPlus 概述 快速入门 配置日志输出 CRUD拓展 插入 主键生成策略 更新操作 自动填充 乐观锁 查询操作 分页查询 删除操作 逻辑删除 性能分析插件 条件构造器 代码自动生成 ...
- 为什么有时博客中的代码复制进自己的VS中报错
昨天写代码时遇到一个问题,我搜了一篇博客,然后复制到我的WPF中, 然后,全报错(当时快给我气死了,一篇有一篇的不能用,试了一次又一次,时间全浪费在这上面了,没打游戏,做的东西也没出来) 问题原因: ...
- 2- 计算机的组成以及VMware使用
计算机的组成: 硬件: 处理器(CPU):I3 I5 I7 运行内存RAM(存储数据) 容量(字节为单位) 主板(总线设备) 输入输出设备(显示屏,键盘,鼠标,触目屏) 外部存储设备(硬盘,U盘,TF ...
- jquery 和 bootstrap 的使用
jquery 和 bootstrap 的使用参考 bootstrap简介 jqury在线手册 jquery快速入门教程 jQuery 核心函数和方法 jQuery API jQuery CDN jQu ...
- Windows PE 第一章开发环境和基本工具使用
第一章 Windows PE 基本工具 1.1开发语言MASM32 1.1.1设置开发环境 这个不细说了,我在整理Intel汇编的时候详细的说了环境搭建以及细节.地址是:http://blog.csd ...