教你用python写:HDU刷题神器
声明:本文以学习为目的,请不要影响他人正常判题
HDU刷题神器,早已被前辈们做出来了,不过没有见过用python写的。大一的时候见识了学长写这个,当时还是一脸懵逼,只知道这玩意儿好屌…。时隔一年,决定自己实现这个功能。

96名,没有再继续刷(,,,已经被管理员发现啦)
首先对辛苦刷题的acmer和hdu的管理员道歉,各位,抱歉。
介绍整体思路:
- 整体用多线程:线程执行从爬代码到提交的全部过程
- 分层次:对搜索引擎搜索的结果,进行划分,分层爬取
局部思路:
- 爬取搜索引擎得到的与题目相关的url,得到url_list
- 爬取url_list中的url,扒到代码就提交
- 检查提交结果,WA之后继续爬取url_list中的代码
- 循环,直到列表为空或者AC
相关模块:
- threadpool线程池,分配线程任务,多线程并发提交代码
- 用requests模块发送请求
- 正则爬取url和代码
- Sqlite存放AC代码(打表啊,再申请个账号从数据库中提交代码100%AC)
1)采用线程池实现多线程,注意控制最大并发数量
搜索引擎使用CSDN的搜索,因为我们爬取的代码全都来自CSDN的博客,可以看一下其他论坛,博客的代码:

(右键,在新标签页中打开查看高清图片)


(右键,在新标签页中打开查看高清图片)

哦,这实在太不友好了,而CSDN博客的代码就好很多了(尽管很友好了,class和name有些先后顺序不一样,也会添乱)

所以,我们决定扒CSDN博客的代码。
搜索引擎的选择,CSDN(部分搜索结果是百度提供的)

其实,第一想到的是百度的,然而。。。

加密了,增大了我们的工作量,所以,就直接用CSDN的(也有百度的结果)
在CSDN搜索结果的最下方,我们可以看到上图中有14W结果(好唬人啊),其实事情是这样的:
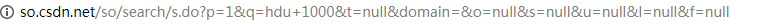

这是一个搜索hdu 1000的url,我们注意到用的get()方法传数据,发现只有p=?,试一下就知道,这个是页码。如果页码改为200呢?
100?
开玩笑啊,14W结果呢?最后我们得出结论:搜索结果只有页,而且越往后,得到我们想要代码的可能性就越小,所以我只爬到20页就结束程序
关于线程池的部分,在python-线程池里说明
# coding :utf-8
# @Time : 2017/8/7 11:24
# @Author : Yong-life
# @File : crawling_hdu.py
import requests
import re
from headers_cookies import *
import threadpool
from searching_code import code_url_list
import threading
from searching_code import submit_code_from_url
import time
'''我要AK HDU'''
def search_pid():
problem_list = []
'''共52页题目'''
page_number = 2
for i in range(page_number):
'''请求url'''
url = 'http://acm.hdu.edu.cn/listproblem.php?vol=' + str(i)
response = requests.get(url, headers=get_headers(), cookies=get_cookie_from_chrome())
'''抓取题目信息'''
patternPidList = r'><script language="javascript">([\s\S]*?);</script>'
problems = re.search(patternPidList, response.text).group(1).split(';')
for problem in problems:
pid = problem[4:8]
status = problem[9]
problem_list.append((int(pid), int(status)))
return problem_list
def start_crawling():
pid_list = []
'''最大并发数量,超过10就很影响别人'''
THREAD_NUMBER = 2
'''从搜索到的第crawl_level_begin页继续开始扒代码'''
crawl_level_begin = 1
'''分段式扒代码'''
crawl_level = 4
END_MARK = True
while END_MARK:
print("正在爬取题目信息……")
for problem in search_pid():
pid, status = problem
# if pid < 3300:
# continue
if status != 5:
'''多参数构造'''
pid_list.append(([pid, crawl_level_begin, crawl_level], None)) # 必须封装为元组,否则会给参数再封装一层列表,也可以改目标函数
if len(pid_list) == THREAD_NUMBER:
'''定义线程池大小'''
task_pool = threadpool.ThreadPool(THREAD_NUMBER)
'''任务列表'''
request_task = []
'''构造任务列表'''
request_task = threadpool.makeRequests(submit_code_from_url, pid_list)
'''将每个任务放到线程池中,等待线程池中线程各自读取任务'''
[task_pool.putRequest(req) for req in request_task]
'''等待所有任务处理完成,则返回,如果没有处理完,则一直阻塞'''
task_pool.wait()
pid_list = []
'''判断是否全对,全对结束'''
END_MARK = False
for status in search_pid()[1]:
if status != 5:
END_MARK = True
'''增加搜索范围'''
crawl_level_begin = crawl_level
crawl_level += 4
break
'''CSDN搜索最搜索到20页数据,而且部分是百度提供的结果'''
if crawl_level > 20:
break
if __name__ == '__main__':
start_crawling()
2)线程开始跑了:分布式思想,分块,分层,完成AK任务
- 爬取crawl_level_begin-crawl_level页搜索结果的url
- 按照url_list爬取代码
- 提交代码
# coding :utf-8
# @Time : 2017/8/7 15:06
# @Author : Yong-life
# @File : searching_code.py
from urllib import request
import urllib
from headers_cookies import get_headers
import re
import sqlite3
from sqlite_hdu import Sql
from submit_codes import *
import threading
from submit_codes import SubmitCode
import sys
def submit_code_from_url(pid, crawl_level_begin, crawl_level):
'''爬取url_list,提交代码'''
url_list = code_url_list(str(pid), crawl_level_begin, crawl_level)
for url in url_list:
'''仅爬取博客链接'''
if url[7:11] != 'blog': # 删选url
continue
code = crawling_code(pid, url)
if code == '':
'''未查找到代码'''
continue
submit = SubmitCode(pid, code.encode("utf-8"))
if submit.submit_manager():
'''AC,保存代码'''
sql_save_code = Sql()
if sql_save_code.query_pid(pid) is None:
sql_save_code.insert_msg(pid, 5, code)
else:
sql_save_code.update_problem_code(pid, code)
sql_save_code.sql_close()
return
print("爬取代码完毕,任务结束: " + str(pid) + "提交尚未成功!")
return
def code_url_list(problem_msg, crawl_level_begin, crawl_level): # 题号和其他信息
'''爬取题目链接'''
url_list = []
'''页码,根据爬虫等级,扩大搜索范围'''
page_number = crawl_level_begin
'''最大页码'''
MAX_PAGE = crawl_level
while page_number < MAX_PAGE:
'''发送url请求'''
url = 'http://so.csdn.net/so/search/s.do?p=' + str(page_number) + '&q=' + 'hdu' + request.quote(problem_msg)
req = request.Request(url, headers=get_headers())
try:
respongse = request.urlopen(req).read().decode('utf-8')
except urllib.error.HTTPError:
continue
'''爬取url链接'''
pattern_problem_url = '<dt>[\S\s]*?<a href="(.*?)"'
result_list = re.findall(pattern_problem_url, respongse)
url_list.extend(result_list)
print(problem_msg + ': ' + str(page_number) + '页已搜索完毕!')
page_number += 1
print('题目url列表爬取完毕!!!')
return url_list
def crawling_code(pid, code_url):
'''爬代码'''
req = request.Request(code_url, headers=get_headers())
response = ''
try:
response = request.urlopen(req).read().decode('utf-8')
except urllib.error.HTTPError as e:
print(e)
'''查找C,C++代码'''
pattern_code_cpp = 'class="cpp">([\s\S]*?)</pre>'
code = re.search(pattern_code_cpp, response)
if code is not None:
print(str(pid) + 'cpp, 已找到!')
'''对代码中html元素进行处理'''
code = ' + code.group(1)
code = translate_code(code)
return code
'''查找JAVA代码'''
pattern_code_java = 'class="java">([\s\S]*?)</pre>'
code = re.search(pattern_code_java, response)
if code is not None:
print(str(pid) + 'java, 已找到!')
code = ' + code.group(1)
code = translate_code(code)
return code
return ''
3)对代码中的html元素处理
Compilation Error次数多了就知道什么元素没处理了
# coding :utf-8
# @Time : 2017/8/7 19:08
# @Author : Yong-life
# @File : translate_code.py
def translate_code(code):
'''转化代码中的html元素'''
code = code.replace('<', '<')
code = code.replace('>', '>')
code = code.replace('"', '"')
code = code.replace('&', '&')
code = code.replace('+', '+')
code = code.replace(''', '\'')
code = code.replace(' ', ' ')
code = code.replace(' ', ' ')
'''替换'''
code = code.replace('</pre>', ' ')
code = code.replace('</div>', ' ')
code = code.replace('<pre>', ' ')
code = code.replace('<div>', ' ')
code = code.replace('</span>', ' ')
return code
4)根据不同语言,选择不同编译器提交代码,并检查代码结果
我们爬取了c,c++,java的代码,提交代码时,要注意选择编译器,我们需要通过提交不同的代码查看请求参数的不同。
这里推荐一款抓包软件:fiddler,小型,实用
关于fiddler的说明:使用fiddler进行抓包测试
测试后,发现:

c:3
c++: 2
G++: 0
JAVA: 5
OK!那么我们在post提交时,修改language参数就可以实现使用不同的编译器进行提交了。提交后,递归检查提交结果。
检查结果时:注意author必须是账户名,用昵称是搜不到

# coding :utf-8
# @Time : 2017/8/7 15:00
# @Author : Yong-life
# @File : submit_codes.py
import requests
from sqlite_hdu import Sql
from headers_cookies import *
from translate_code import translate_code
import re
import time
class SubmitCode():
'''题目号,代码'''
def __init__(self, pid, code):
self.cu = Sql()
self.pid = pid
self.code = code
def submit_manager(self):
print("提交代码,休息3秒: " + str(self.pid))
self.submit(self.pid, self.code)
'''提交代码,休息3秒'''
time.sleep(3)
if self.query_result(self.pid):
print("题号: " + str(self.pid) + "已AC")
self.cu.sql_close()
return True
else:
print("题号: " + str(self.pid) + "WA ,正在继续提交!")
self.cu.sql_close()
return False
'''提交代码'''
def submit(self, pid, code):
url = 'http://acm.hdu.edu.cn/submit.php?action=submit'
try:
data = {
',
'problemid': str(pid),
'language': code[0],
'usercode': code[1:]
}
except IndexError:
print("empty code")
return
response = requests.post(url, data, headers=get_headers(), cookies=get_cookie_from_chrome())
'''检查提交结果'''
def query_result(self, pid):
USER_NAME = self.get_user_name()
'''请求url'''
url = 'http://acm.hdu.edu.cn/status.php?first=&pid=' + str(pid) + '&user=' + USER_NAME + '&lang=0&status=0'
response = requests.get(url, headers=get_headers(), cookies=get_cookie_from_chrome())
'''检查结果'''
pattern_query = r'<td><font color=red>(.*?)</font>'
query_result = re.findall(pattern_query, response.text)
if len(query_result) > 0:
'''AC'''
return True
else:
'''判断代码提交代码状态'''
'''是否在判题中'''
if response.text.find("Queuing") != -1 or response.text.find("Running") != -1 or response.text.find(
"Compiling") != -1:
'''等待判题中,暂不提交'''
print('等待判题')
time.sleep(1)
return self.query_result(pid)
else:
'''代码WA'''
return False
'''爬取账号名,账号名和昵称,只能用账号名查找结果'''
def get_user_name(self):
url = 'http://acm.hdu.edu.cn/'
response = requests.get(url, headers=get_headers(), cookies=get_cookie_from_chrome()).text
pattern_user_name = r'width:150px"><a href="/userstatus.php\?user=(.*?)"'
user_name = re.search(pattern_user_name, response).group(1)
return user_name
5)将AC代码存入数据库,代表,以备100%AK
注意:sql查找语句,传值必须是元组的形式,即使只有一个值,要加‘,’
# coding :utf-8
# @Time : 2017/8/7 15:42
# @Author : Yong-life
# @File : sqlite_hdu.py
import sqlite3
class Sql():
def __init__(self):
file_path = 'E:\python_workspace\crawling_hdu\sql_databases\hdu.db'
self.con = sqlite3.connect(file_path, check_same_thread=False) # 支持多线程访问
self.cu = self.con.cursor()
# self.cu.execute('DROP TABLE IF EXISTS problem')
self.cu.execute("CREATE TABLE IF NOT EXISTS problem (pid INTEGER PRIMARY KEY , status INT, code TEXT)")
def insert_msg(self, pid, status=0, code=''):
'''插入信息'''
value = (pid, status, code)
self.cu.execute("INSERT INTO problem(pid, status, code) VALUES (?,?,?)", value)
self.con.commit()
def query_code(self, pid):
'''查找代码'''
self.cu.execute("SELECT code FROM problem WHERE pid=?", (pid,)) # why
return self.cu.fetchone()[0]
def query_pid(self, pid):
'''检查代码是否已存库'''
self.cu.execute("SELECT pid FROM problem WHERE pid=?", (pid,)) # why
return self.cu.fetchone()
def delete_problem_msg(self, pid):
'''删除'''
self.cu.execute("DELETE FROM problem WHERE pid=?", (pid,)) # why
self.con.commit()
def update_problem_code(self, pid, code):
'''更新代码'''
self.cu.execute("UPDATE problem SET code=? WHERE pid=?", (code, pid))
self.con.commit()
def sql_close(self):
self.cu.close()
self.con.close()
6)cookie与header的获取:
cookie可以从google的chrome浏览器获取,路径在:“C:\Users\Garbos\AppData\Local\Google\Chrome\User Data\Default\Cookies”,对应改一下用户名就好了
# coding :utf-8
# @Time : 2017/7/30 16:42
# @Author : Jingxiao Fu
# @File : headers_cookies.py
import random
import os
import subprocess
import sqlite3
import win32crypt
import sys
header_str = '''Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50
Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)
Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)'''
def get_headers():
header = header_str.split('\n')
header_length = len(header)
headers = {'user-agent': header[random.randint(0, header_length - 1)]}
return headers
def get_cookie_use_hand():
'''手动复制cookie'''
cookie = "Cookie:exesubmitlang=0; PHPSESSID=uqfje2cajo7j3kicrn8d2fol25"
cookie = cookie.replace('Cookie:', '')
cookie = cookie.replace(' ', '')
cookies = cookie.split(';')
for i in range(len(cookies)):
cookies[i] = cookies[i].replace('=', ':', 1)
cookies_dict = {}
for header in cookies:
L = header.split(':', 1)
cookies_dict[L[0]] = L[1]
return cookies_dict
'''从chrome浏览器获取cookie'''
def get_cookie_from_chrome():
host_url = 'acm.hdu.edu.cn'
cookie_file_path = r"C:\Users\Garbos\AppData\Local\Google\Chrome\User Data\Default\Cookies"
sql_query = "select host_key, name, encrypted_value ,value from cookies WHERE host_key='%s'" % host_url
with sqlite3.connect(cookie_file_path) as con:
cu = con.cursor()
cu.execute(sql_query)
cookies_sql = {name: win32crypt.CryptUnprotectData(encrypted_value)[1].decode() for
host_key, name, encrypted_value, value in cu.execute(sql_query).fetchall()}
return cookies_sql
开始你的AK之旅吧!
教你用python写:HDU刷题神器的更多相关文章
- 手把手教你用C++ 写ACM自动刷题神器(冲入HDU首页)
转载注明原地址:http://blog.csdn.net/nk_test/article/details/49497017 少年,作为苦练ACM,通宵刷题的你 是不是想着有一天能够荣登各大OJ榜首,俯 ...
- python在leecode刷题-第一题和第七题
class Solution(object): def twoSum(self, nums, target): """ :type nums: List[int] num ...
- python(9)- python基础知识刷题
1. 执行 Python 脚本的两种方式 交互方式:命令行 Windows操作系统下,快捷键cmd,输入“python”启动交互式python解释器. 文件方式:python文件 2. 简述位.字 ...
- hdu 刷题记录
1007 最近点对问题,采用分治法策略搞定 #include<iostream> #include<cmath> #include<algorithm> using ...
- hdu刷题2
hdu1021 给n,看费波纳列数能否被3整除 算是找规律吧,以后碰到这种题就打打表找找规律吧 #include <stdio.h> int main(void) { int n; whi ...
- 500行代码,教你用python写个微信飞机大战
这几天在重温微信小游戏的飞机大战,玩着玩着就在思考人生了,这飞机大战怎么就可以做的那么好,操作简单,简单上手. 帮助蹲厕族.YP族.饭圈女孩在无聊之余可以有一样东西让他们振作起来!让他们的左手 / 右 ...
- (python)leetcode刷题笔记 02 Add Two Numbers
2. Add Two Numbers You are given two non-empty linked lists representing two non-negative integers. ...
- (python)leetcode刷题笔记 01 TWO SUM
1. Two Sum Given an array of integers, return indices of the two numbers such that they add up to a ...
- hdu刷题1
1002 大数加法 #include<iostream> #include<cstring> using namespace std; int main() { ],b[]; ...
随机推荐
- Entity Framework入门教程:创建实体数据模型
下图为一个已经创建好的数据库表关系 实体数据模型的创建过程 在Visual Studio项目中,右键程序集菜单,选择[添加]->[新建项],在[添加新项窗口]中选择[ADO.NET实体数据模型] ...
- jquery按钮倒计时
<html> <head> <script src="http://libs.baidu.com/jquery/1.9.0/jquery.js"> ...
- webpack的简单配置
本人刚开始也不会写webpack配置,刚开始在网上搜索了了一些,看的也是刚刚理解,所以准备自己写下来,已作纪念和贡献给像我一样不会配置的“童鞋”们! 1.创建webpack配置文件 在项目文件下创建一 ...
- 2017全球互联网技术大会回顾(附PPT)
有幸遇见 GITC2017上海站,刚好遇见你! 为期两天(6.23~24)的GITC大会在上海举行,我有幸参加了24号的那场,也就是上周六,之所以今天才来回顾,是我想等PPT出来后分享给大家! 这应该 ...
- 2.Smarty的引入和实例化
1.把demo和lib复制出来,并且创建一个test文件夹作为工作的目录 如图所示: 2.这是libs里面的内容,其中smarty.class.php包含了smarty各种方法和功能,需要实例化它还工 ...
- iOS中UIWebView执行JS代码(UIWebView)
iOS中UIWebView执行JS代码(UIWebView) 有时候iOS开发过程中使用 UIWebView 经常需要加载网页,但是网页中有很多明显的标记让人一眼就能看出来是加载的网页,而我们又不想被 ...
- 闭包JS
一句话概括的话:闭包就是一个函数,捕获作用域内的外部绑定. 官方的定义:一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因为这些变量也称为该表达式的一部分. 自由变量和闭包的关系:自 ...
- 在suse上折腾iptables
需求背景:有台服务器希望屏蔽掉某IP对它的SSH连接. 临时客串下DevOps,下面的做法可能在专业运维的同学里不太专业,还请指教. 该服务器的操作系统是SuSE Linux,服务器上是安装了ipta ...
- VB6之图像灰度与二值化
老代码备忘,我对图像处理不是太懂. 注:部分代码引援自网上,话说我到底自己写过什么代码... Private Declare Function GetBitmapBits Lib "gdi3 ...
- Jenkins迁移job
说明:从一个Jenkins服务器A将现有job迁移到另外一个Jenkins服务器B. 方法:You can copy or move build jobs between instances of p ...