Python爬虫番外篇之关于登录
常见的登录方式有以下两种:
- 查看登录页面,csrf,cookie;授权;cookie
- 直接发送post请求,获取cookie
上面只是简单的描述,下面是详细的针对两种登录方式的时候爬虫的处理方法
第一种情况
这种例子其实也比较多,现在很多网站的登录都是第一种的方法,这里通过以github为例子:
分析页面
获取authenticity_token信息
我们都知道登录页面这里都是一个form表单提交,我可以可以通过谷歌浏览器对其进行分析
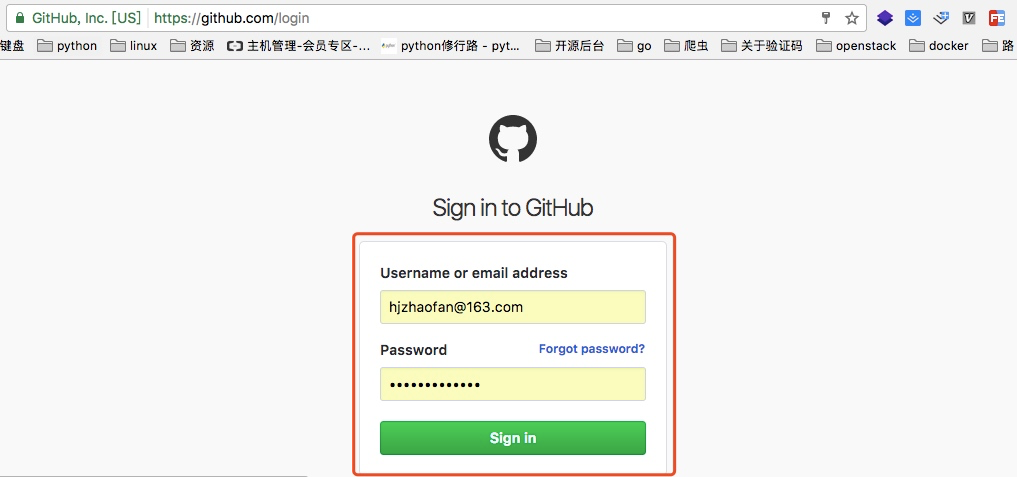
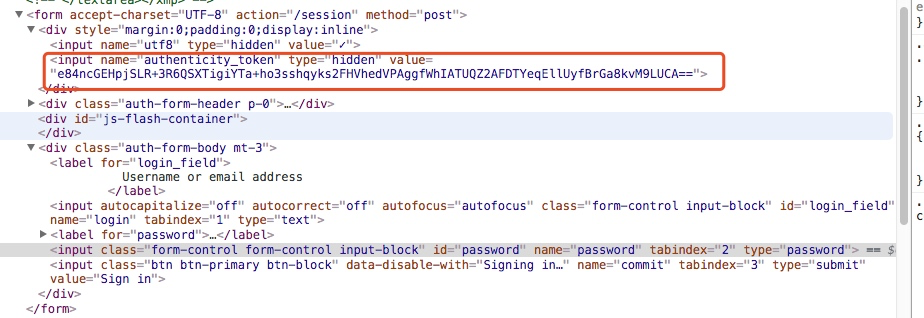
如上图我们找到了这个token信息
所以我们在登录之前应该先通过代码访问这个登录页面获取这个authenticity_token信息
获取登陆页面的cookie信息
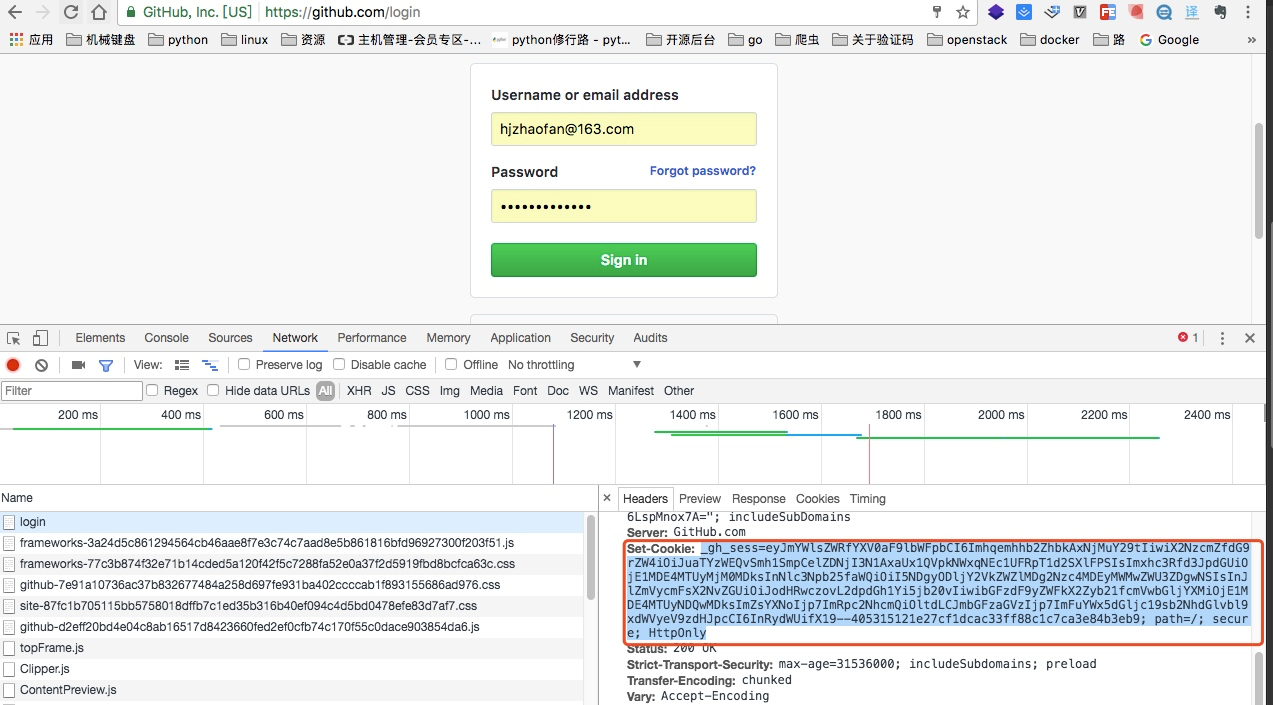
set-cookie这里是登录页面的cookie
分析登录包获取提交地址
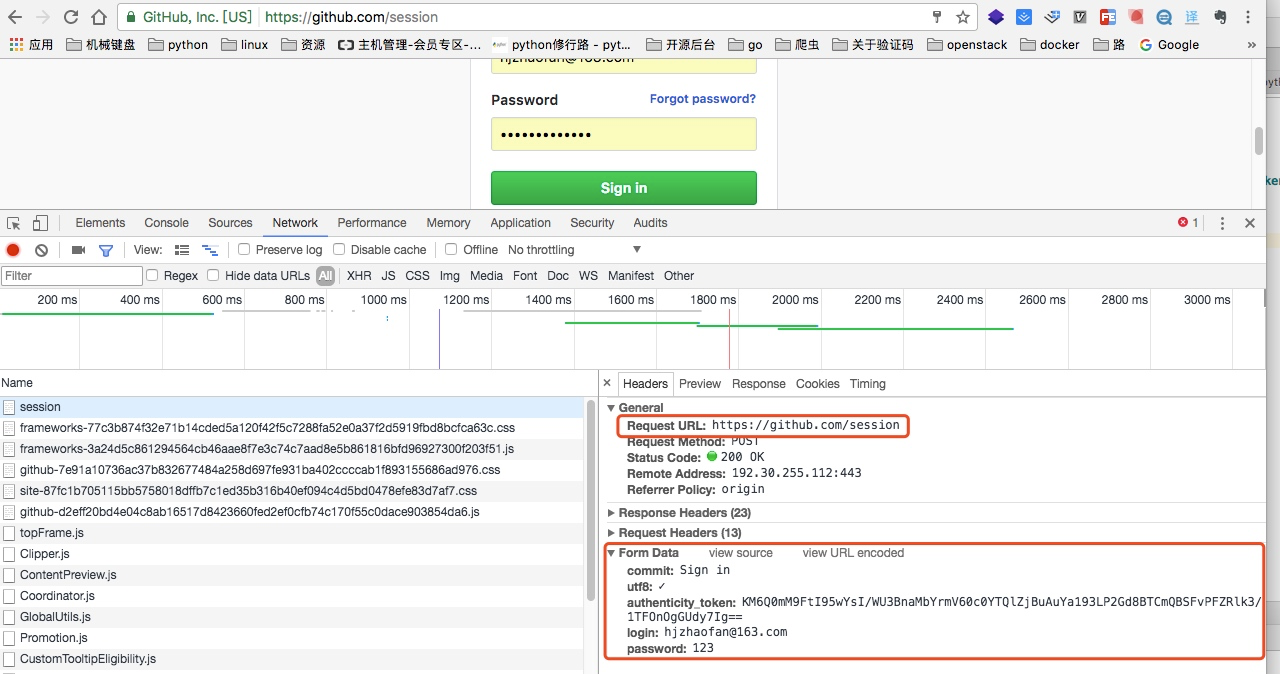
当我们输入用户名和密码之后点击提交,我们可以从包里找到如上图的地址,就是post请求提交form的信息
请求的地址:https://github.com/session
请求的参数有:
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":“KM6Q0mM9FtI95wYsI/WU3BnaMbYrmV60c0YTQlZjBuAuYa193LP2Gd8BTCmQBSFvPFZRlk3/1TFOnOgGUdy7Ig==”,
"login":"hjzhaofan@163.com",
"password":"123"
从这里我们也可以看出提交参数中的“authenticity_token”,而这个参数就是需要我们从登陆页面先获取到。
当我们登录成功后:

再次访问github,这个时候cookie里就增加了两个cookie信息,而这个信息是登录后在增加的信息
所以如果我们想要通过程序登录,我们就需要在登录成功后再次获取cookie信息
然后通过这个cookie去访问我们github的其他信息例如我们的个人信息设置页面:
https://github.com/settings/profile
代码实现
下面代码实现了登录并访问https://github.com/settings/repositories
import requests
from bs4 import BeautifulSoup Base_URL = "https://github.com/login"
Login_URL = "https://github.com/session" def get_github_html(url):
'''
这里用于获取登录页的html,以及cookie
:param url: https://github.com/login
:return: 登录页面的HTML,以及第一次的cooke
'''
response = requests.get(url)
first_cookie = response.cookies.get_dict()
return response.text,first_cookie def get_token(html):
'''
处理登录后页面的html
:param html:
:return: 获取csrftoken
'''
soup = BeautifulSoup(html,'lxml')
res = soup.find("input",attrs={"name":"authenticity_token"})
token = res["value"]
return token def gihub_login(url,token,cookie):
'''
这个是用于登录
:param url: https://github.com/session
:param token: csrftoken
:param cookie: 第一次登录时候的cookie
:return: 返回第一次和第二次合并后的cooke
''' data= {
"commit": "Sign in",
"utf8":"✓",
"authenticity_token":token,
"login":"你的github账号",
"password":"*****"
}
response = requests.post(url,data=data,cookies=cookie)
print(response.status_code)
cookie = response.cookies.get_dict()
#这里注释的解释一下,是因为之前github是通过将两次的cookie进行合并的
#现在不用了可以直接获取就行
# cookie.update(second_cookie)
return cookie if __name__ == '__main__':
html,cookie = get_github_html(Base_URL)
token = get_token(html)
cookie = gihub_login(Login_URL,token,cookie)
response = requests.get("https://github.com/settings/repositories",cookies=cookie)
print(response.text)
第二种情况
这里通过伯乐在线为例子,这个相对于第一种就比较简单了,没有太多的分析过程直接发送post请求,然后获取cookie,通过cookie去访问其他页面,下面直接是代码实现例子:
http://www.jobbole.com/bookmark/ 这个地址是只有登录之后才能访问的页面,否则会直接返回登录页面
这里说一下:http://www.jobbole.com/wp-admin/admin-ajax.php是登录的请求地址这个可以在抓包里可以看到
import requests
def login():
url = "http://www.jobbole.com/wp-admin/admin-ajax.php"
data = {
"action": "user_login",
"user_login":"zhaofan1015",
"user_pass": '******',
}
response = requests.post(url,data)
cookie = response.cookies.get_dict()
print(cookie)
url2 ="http://www.jobbole.com/bookmark/"
response2 = requests.get(url2,cookies=cookie)
print(response2.text) login()
Python爬虫番外篇之关于登录的更多相关文章
- Python爬虫番外篇之Cookie和Session
关于cookie和session估计很多程序员面试的时候都会被问到,这两个概念在写web以及爬虫中都会涉及,并且两者可能很多人直接回答也不好说的特别清楚,所以整理这样一篇文章,也帮助自己加深理解 什么 ...
- python爬虫番外篇(一)进程,线程的初步了解
一.进程 程序并不能单独和运行只有将程序装载到内存中,系统为他分配资源才能运行,而这种执行的程序就称之为进程.程序和进程的区别在于:程序是指令的集合,它是进程的静态描述文本:进程是程序的一次执行活动, ...
- python之爬虫--番外篇(一)进程,线程的初步了解
整理这番外篇的原因是希望能够让爬虫的朋友更加理解这块内容,因为爬虫爬取数据可能很简单,但是如何高效持久的爬,利用进程,线程,以及异步IO,其实很多人和我一样,故整理此系列番外篇 一.进程 程序并不能单 ...
- python爬虫【实战篇】模拟登录人人网
requests 提供了一个叫做session类,来实现客户端和服务端的会话保持 使用方法 1.实例化一个session对象 2.让session发送get或者post请求 session = req ...
- python学习番外篇——字符串的数据类型转换及内置方法
目录 字符串的数据类型转换及内置方法 类型转换 内置方法 优先掌握的方法 需要掌握的方法 strip, lstrip, rstrip lower, upper, islower, isupper 插入 ...
- python自动化测试应用-番外篇--接口测试2
篇2 book-python-auto-test-番外篇--接口测试2 --lamecho辣么丑 大家好! 我是lamecho(辣么丑),今天将继续上一篇python接 ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (II)
#3使用html+css+js制作网页 番外篇 使用python flask 框架 II第二部 0. 本系列教程 1. 登录功能准备 a.python中操控mysql b. 安装数据库 c.安装mys ...
- #3使用html+css+js制作网页 番外篇 使用python flask 框架 (I)
#3使用html+css+js制作网页 番外篇 使用python flask 框架(I 第一部) 0. 本系列教程 1. 准备 a.python b. flask c. flask 环境安装 d. f ...
- 给深度学习入门者的Python快速教程 - 番外篇之Python-OpenCV
这次博客园的排版彻底残了..高清版请移步: https://zhuanlan.zhihu.com/p/24425116 本篇是前面两篇教程: 给深度学习入门者的Python快速教程 - 基础篇 给深度 ...
随机推荐
- .NET 开发环境搭建
概述 在接下来的时间里,将会入手ASP.NET MVC这一专题,尽量用最快的时间,最有效的方法,分别从深度和广度上剖析这一专题,力求讲明白.讲透.以此来与大家分享,力求达到共同学习,共同交流,共同进步 ...
- Android的UI调优
对于一个App的UI而言,在流畅性上的改进目标其实就是降低屏幕绘制的延迟,创建流畅和稳定的帧率以避免卡顿. 在理想情况下,全部的测量.布局和绘制的时间最好在16ms以内,这样才能保证屏幕运行的顺畅性. ...
- net core 程序docker打包镜像并发布到官方store
学习一个技术的第一步,总是要先打印或显示一个hello world的.当然,学习docker也不例外.上一篇文章已经简单的介绍了环境的安装和配置.接下来就要打印我们的hello world了. 首先我 ...
- 短信发送接口被恶意访问的网络攻击事件(三)定位恶意IP的日志分析脚本
前言 承接前文<短信发送接口被恶意访问的网络攻击事件(二)肉搏战-阻止恶意请求>,文中有讲到一个定位非法IP的shell脚本,现在就来公布一下吧,并没有什么技术难度,只是当时花了些时间去写 ...
- R语言统计分析技术研究——岭回归技术的原理和应用
岭回归技术的原理和应用 作者马文敏 岭回归分析是一种专用于共线性分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息,降低精度为代价获得回归系数更为符合 ...
- 取消PHPCMS V9后台新版本升级提示信息
方法非常简单,只要找到文件: phpcms/libs/classes/update.class.php 文件,修改第50行的代码(大概位置): function notice() { return $ ...
- Discuz搜索改为指向帖子
安装的版本是DiscuzX2.5,搜索的时候发现默认指向的是门户里的文章搜索,但程序都没有安装门户,只有论坛,所以不能搜索文章. 在网上找了半天终于找到修改的办法了. <input name=& ...
- Qt开发陷阱一QSTACKWIDGET
原始日期:2015-10-14 00:55 1.使用QStackWidget控件的setCurrentIndex方法时,要注意参数0对应着ui上StackWidget的page1,而不是page0,没 ...
- mac+phpstorm增加xdebug调试
一.版本信息 mac 10.10.5 phpstorm 10.0.3 xdebug 版本需要与phpstorm匹配,匹配地址 点我匹配 点我查看所有版本 提示:不确定xdebug版本的,把php ...
- Pycharm创建的virtualenv环境缺失pip.exe的问题(Windows系统)
Windows环境: 1. Python安装在d:\Python\Python35下, Python新版本安装时默认会勾选pip功能 2. PyCharm的Settings中Create Virtua ...