Hadoop学习---Eclipse中hadoop环境的搭建
在eclipse中建立hadoop环境的支持
1.需要下载安装eclipse
2.需要hadoop-eclipse-plugin-2.6.0.jar插件,插件的终极解决方案是https://github.com/winghc/hadoop2x-eclipse-plugin下载并编译。也是可用提供好的插件。
3.复制编译好的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse插件目录(plugins目录)下,如图所示
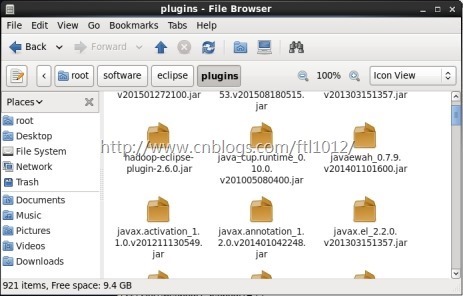
重启eclipse
4.在eclipse中配置hadoop安装目录
windows ->preference -> hadoop Map/Reduce -> Hadoop installation directory在此处指定hadoop的安装目录
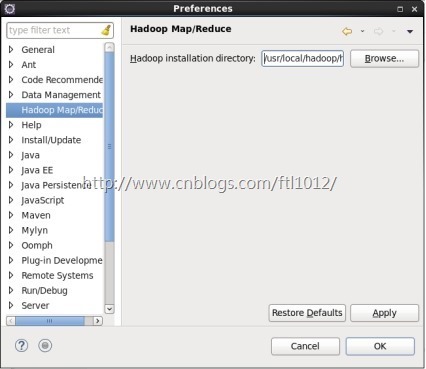
点击Apply,点击OK确定
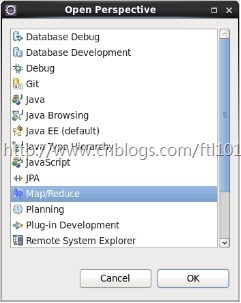
5.配置Map Reduce视图
window -> Open Perspective ->other-> Map/Reduce -> 点击“OK”
window -> show view -> other -> Map/Reduce Locations -> 点击“OK”
6.在“Map/Reduce Location”Tab页点击图标<大象+>或者在空白的地方右键,选择“New Hadoop location...”,弹出对话框“New hadoop location...”,进行相应的配置
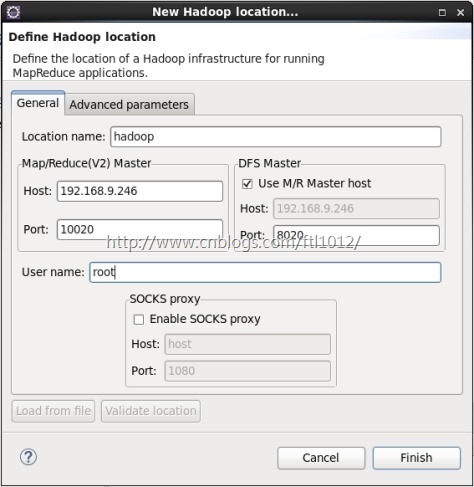
设置Location name为任意都可以,Host为hadoop集群中主节点所在主机的ip地址或主机名,这里MR Master的Port需mapred-site.xml配置文件一致为10020,DFS Master的Port需和core-site.xml配置文件的一致为9000,User name为root(安装hadoop集群的用户名)。之后点击finish。在eclipse的DFS Location目录下出现刚刚创建的Location name(这里为hadoop),eclipse就与hadoop集群连接成功,如图所示。

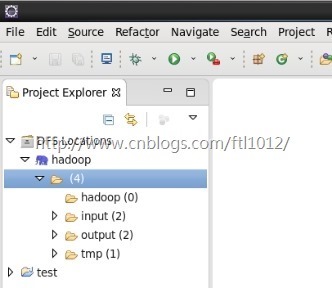
7.打开Project Explorers查看HDFS文件系统,如图所示
8.新建Map/Reduce任务
需要先启动Hadoop服务
File -> New -> project -> Map Reduce Project ->Next
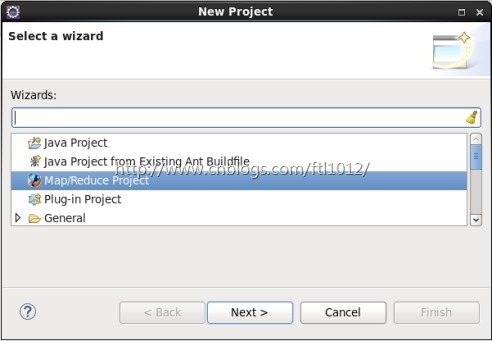
填写项目名称
编写WordCount类:
package test; import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class MyMap extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class MyReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
运行WordCount程序:
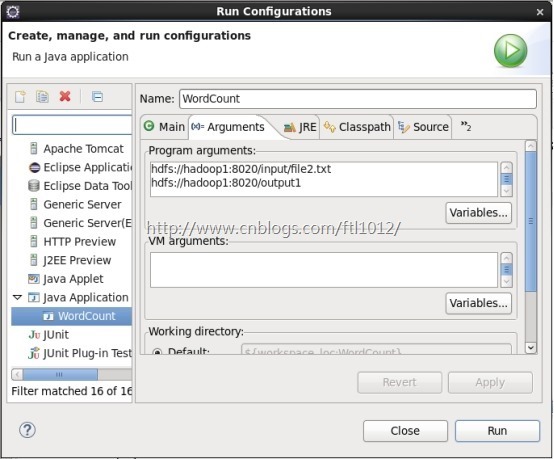
右键单击Run As -> Run Configurations
选择Java Applications ->WordCount(要运行的类)->Arguments
在Program arguments中填写输入输出路径,点击Run
Hadoop学习---Eclipse中hadoop环境的搭建的更多相关文章
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- Hadoop学习---Ubuntu中hadoop完全分布式安装教程
软件版本 Hadoop版本号:hadoop-2.6.0-cdh5.7.0: VMWare版本号:VMware 9或10 Linux系统:CentOS 6.4-6.5 或Ubuntu版本号:ubuntu ...
- hadoop学习(一)环境的搭建
1.安装几台Linux虚拟机.安装的过程就不赘述了,网上教程很多.win7系统上装了一个VMWare,因为一些原因,VMWare版本不是最新的,是VMWare7.1版本,由于VMWare版本不高,所以 ...
- eclipse中JDK环境的搭建
现在就可以用记事本开发java程序了,但是eclipse是一款java开发不可缺少的IDE,并且安装简单,下面说一下步骤,首先下载eclipse, 官网下载链接:http://www.eclipse. ...
- Hadoop学习笔记(3)——分布式环境搭建
Hadoop学习笔记(3) ——分布式环境搭建 前面,我们已经在单机上把Hadoop运行起来了,但我们知道Hadoop支持分布式的,而它的优点就是在分布上突出的,所以我们得搭个环境模拟一下. 在这里, ...
- Hadoop在eclipse中的配置
在安装完linux下的hadoop框架,实现完所现有的wordCount程序,能够完美输出结果之后,我们开始来搭建在window下的eclipse的环境,进行相关程序的编写. 在网上有很多未编译版本, ...
- Eclipse中Hadoop插件配置
Eclipse中Hadoop插件DFS配置 http://www.cnblogs.com/xia520pi/archive/2012/05/20/2510723.html
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
- 吴裕雄--天生自然Hadoop学习笔记:Hadoop简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储.Hadoop实现了一个分布式文件系统(H ...
随机推荐
- JWT(Json Web Token)初探与实践
前言什么是JWT?为什么使用JWT?什么时候使用JWT?JWT的基本结构HeaderPayloadSignature将他们放在一起项目实践JWT后端前端关于安全性总结参考 协议标准:https://t ...
- fix the issue that disk space is not the size that aws ec2 have.
在申请aws ec2时,按照向导,在选择存储的时候默认硬盘大小是 8 G,这时候可以根据自己的需要输入一个合适的数字,例如100.完成向导并启动ec2 instance 后登陆机器.使用命令: df ...
- (转)Systemd 入门教程:命令篇
Systemd 入门教程:命令篇 原文:http://www.ruanyifeng.com/blog/2016/03/systemd-tutorial-commands.html Systemd 入门 ...
- 看一段Delphi导出到Word的源代码
procedure TFrmWeekAnalysisQry.BtnExportToExcelClick(Sender: TObject);var wordApp,WordDoc,WrdSelectio ...
- <a>标签里面嵌图片<img>下面出现一小段空白的原因
今天做项目的时候,发现在a标签,里面嵌入<img>会出现空白 css 内容: a{ border:1px solid black; } img{ width:200px; } html内容 ...
- JVM的内存分配和回收策略
对象的Class加载 虚拟机遇到一条new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载.解析和初始化过.如果没有,那必须先执行相应 ...
- Visual Studio中修改项目的输出目录
1. 如在Solution中的项目名称为 ProjectA 但在本地目录显示却想换成: MyProject 2. 应该做的修改是: 2.1. 将本地目录的 ProjectA手动修改成 MyProjec ...
- Visual Studio中判断项目的类型
1. 打开项目的属性,查看Application的Output type
- jmeter(1)——环境部署及安装
公司人事还有老大都找我谈了一下2019的目标和技能成长规划,所以整体想了一下,技能方面,自己今年准备从性能测试开始着手,也去咨询了一下大神,切入点最好是工具.性能测试是一门非常庞大的课程,最初级,最入 ...
- sql 递归 STUFF
select distinct fm_id, ,,'') AS SO_Nums from [dbo].[t_BADItems] its 表内一对多 的关系查询