Hadoop2.9下运行JAR包时System.out.println的输出日志
根据博文——Hadoop日志存放路径详解中所述,Container日志包含ApplicationMaster日志和普通Task日志(关于其他类型的日志的详细说明请参考该博文,本文不再赘述)
所以可知,System.out.println的输出日志是属于Mapreduce程序的Container日志的普通Task日志
以下配置均在yarn-site.xml中,可在官网上查看默认配置的说明:http://hadoop.apache.org/docs/r2.9.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
Container日志的在本地文件系统中的存放路径
日志默认位于${HADOOP_HOME}/logs/userlogs
配置项如下:
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>${yarn.log.dir}/userlogs</value>
<description>应用程序的本地化的日志目录</description>
</property>
官网上对该配置项的描述如下:
Where to store container logs. An application's localized log directory will be found in ${yarn.nodemanager.log-dirs}/application_${appid}. Individual containers' log directories will be below this, in directories named container_{$contid}. Each container directory will contain the files stderr, stdin, and syslog generated by that container.
根据博文——Hadoop日志到底存在哪里?中所述,Container日志存放在目录${HADOOP_HOME}/logs/userlogs/application_xxx下,其中ApplicationMaster日志目录名称为container_xxx_000001,普通task日志目录名称则为container_xxx_000002,container_xxx_000003,….,每个目录下包含三个日志文件:stdout、stderr和syslog,且具体含义是一样的。(事实上,还有两个文件,prelaunch.out和prelaunch.err,不知是不是2.9版本的原因)
Container日志的在HDFS文件系统中的存放路径
1. 开启日志聚合
配置项如下:
<property>
<name>yarn.log-aggregation-enable</name>
<value>True</value>
<description>启用日志聚合,默认值为False,即禁用</description>
</property>
官网上对该配置项的描述如下:
Whether to enable log aggregation. Log aggregation collects each container's logs and moves these logs onto a file-system, for e.g. HDFS, after the application completes. Users can configure the "yarn.nodemanager.remote-app-log-dir" and "yarn.nodemanager.remote-app-log-dir-suffix" properties to determine where these logs are moved to. Users can access the logs via the Application Timeline Server.
2. 日志路径
日志默认位于${fs.defaultFS}/tmp/logs/${user}/logs
eg. 我的${fs.defaultFS}在core-site.xml中配置的值为hdfs://Master:9000,用户名为hadoop,所以我的日志位于hdfs://Master:9000/tmp/logs/hadoop/logs
配置项如下:
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>日志聚合路径</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
<description>当前用户的日志存放位置</description>
</property>
官网上对该配置项的描述如下:
Where to aggregate logs to.
The remote log dir will be created at {yarn.nodemanager.remote-app-log-dir}/${user}/{thisParam}
注意:
1. 只有作为数据节点的主机(即存在进程DataNode)的文件系统中才会在运行Mapreduce程序时被建立路径${HADOOP_HOME}/logs/userlogs
2. 当启用了日志聚合时,日志会存放到HDFS文件系统中,只能通过web用户界面查看,本地节点的文件系统中,路径${HADOOP_HOME}/logs/userlogs虽然存在,但是为空
接下来,关于注意的两点,来进行解释,同时详细说明查看System.out.println的输出日志的两种方式,即在本地查看&在web用户界面查看。
测试的JAR包的源码其实只是在wordCount代码的基础上增加了一些System.out.println语句,详见本人的另一篇博文:
MapReduce程序——WordCount(Windows_Eclipse + Ubuntu14.04_Hadoop2.9.0)
一、在本地查看System.out.println的输出日志
1. 配置/usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
<description>ResourceManager的主机名</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager的辅助服务</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>False</value>
<description>禁用日志聚合,默认值也为False,这条配置项可不写</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/Hadoop_test/userlogs</value>
<description>应用程序的本地化的日志目录,默认值为${yarn.log.dir}/userlogs,为了测试该条配置项是否起了作用,我进行了修改</description>
</property>
</configuration>
2. 初始化Hadoop工作环境
具体操作见本人另一篇博文:ubuntu14.04搭建Hadoop2.9.0集群(分布式)环境的第八节——“八、更改配置或初始化工作环境”
3. 运行JAR包
$ hadoop jar wordCount.jar wordCount.WordMain

可以看到,在Main方法里面的部分都可以在终端输出,而一旦程序进入Mapper和Reducer的部分,这个时候在集群上运行,任务是分发到DataNode的主机里面跑,就不会在终端显示了,所以在Mapper和Reducer里面的是无法看到的。
我们需要去自己定义的日志目录下,查看打印信息。
4. 查看任务分发运行情况
我们先去web用户界面http://master:8088/cluster查看任务分发运行情况
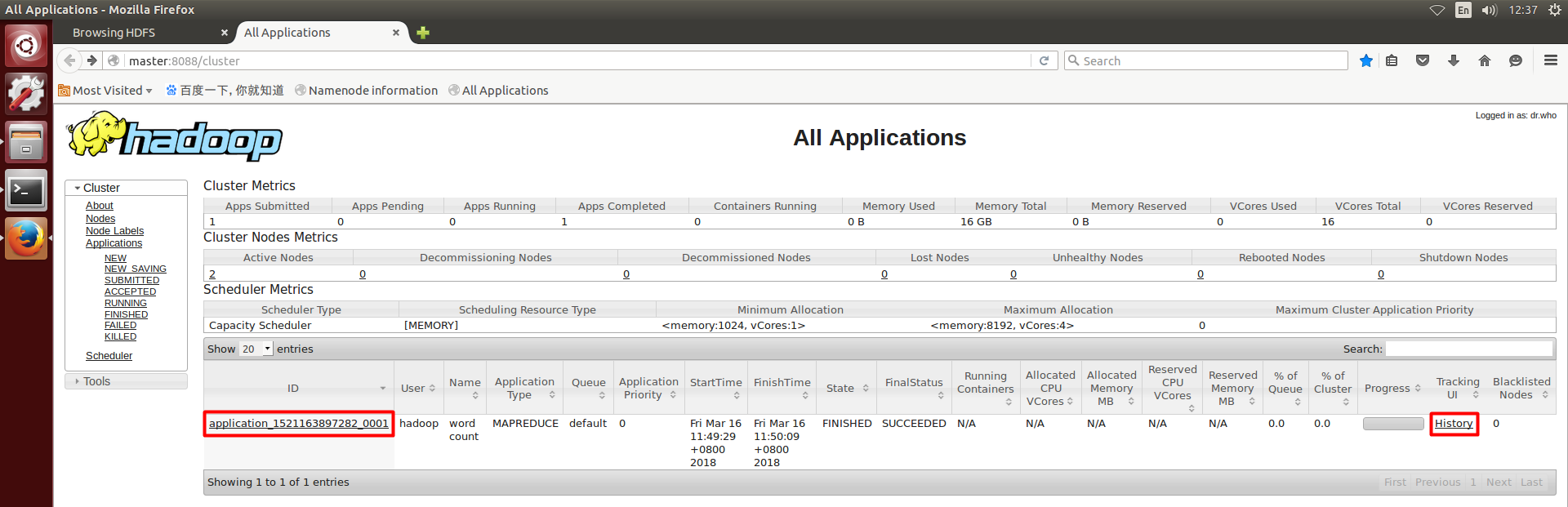
点击History

上面的红框的logs是ApplicationMaster日志
点击Maps和Reduces后面的数字链接,就能看到每个任务运行的情况

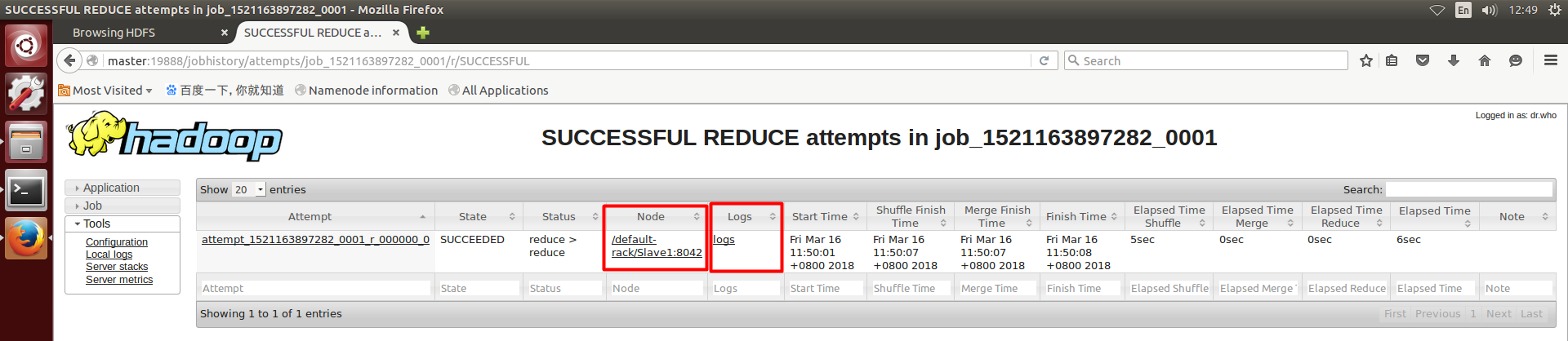
可以看到,Maps和Reduces均运行在主机Slave1
点击后面的logs链接,会报错如下:

因为我们未启用日志聚合,具体的说明见本文第二节——“二、在web用户界面查看System.out.println的输出日志”
5. 查看日志信息
现在我们可以去主机Slave1中查看打印信息了

路径~/Hadoop_test/userlogs是自动生成的
进入文件夹application_xxx内,ApplicationMaster日志目录名称为container_xxx_000001,普通task日志目录名称则为container_xxx_000002,container_xxx_000003,….
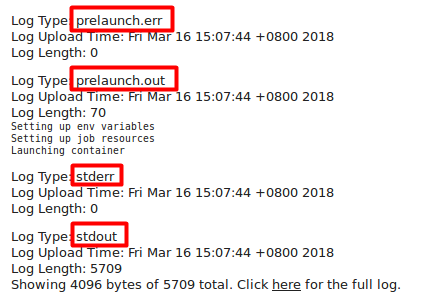
每个目录下包含五个日志文件:prelaunch.out、prelaunch.err、stdout、stderr和syslog,System.out.println的输出日志就在文件stdout中
6. 其他主机的情况
Master——不是数据节点——不存在路径~/Hadoop_test/userlogs

Slave2——虽然是数据节点,但是未运行MapReduce程序——自动生成路径~/Hadoop_test/userlogs,但是为空

二、在web用户界面查看System.out.println的输出日志
1. 配置/usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
<description>ResourceManager的主机名</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager的辅助服务</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>True</value>
<description>启用日志聚合,默认值为False,即禁用</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/Hadoop_test/userlogs</value>
<description>应用程序的本地化的日志目录,默认值为${yarn.log.dir}/userlogs,为了测试该条配置项是否起了作用,我进行了修改</description>
</property>
</configuration>
2. 初始化Hadoop工作环境
3. 运行JAR包
4. 查看任务分发运行情况
以上操作与第一节相同

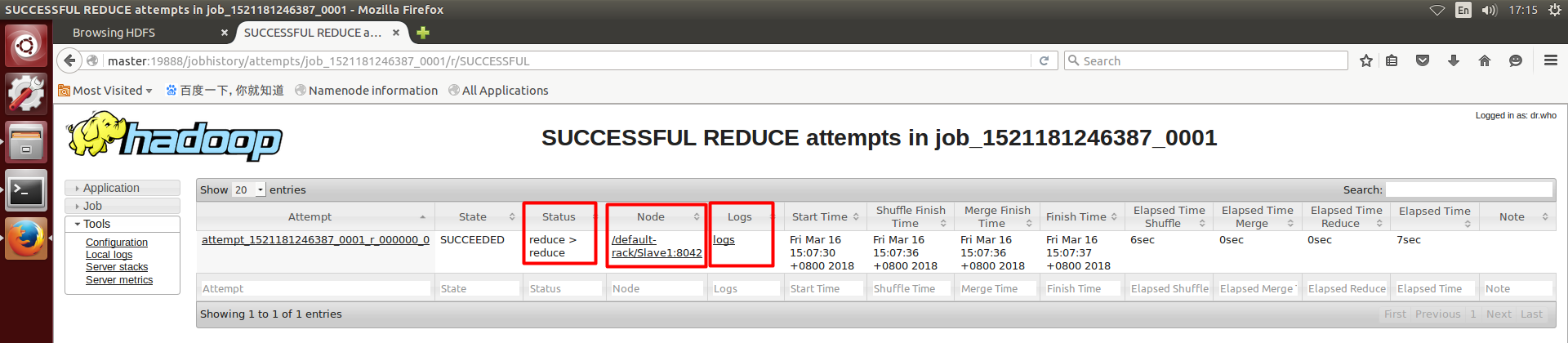
可以看到,Maps运行在主机Slave2,Reduces运行在主机Slave1
5. 查看日志信息
点击logs链接,因为启用了日志聚合,不会再报错了,而是显示出日志信息

用命令行查看
hdfs dfs -ls hdfs://Master:9000/tmp/logs/hadoop/logs

每个节点的各个类型的日志全部聚合成了一个文件,可以直接查看
hdfs dfs -cat XXX
6. 主机的情况
Master——不是数据节点——不存在路径~/Hadoop_test/userlogs

Slave1——虽然是数据节点,并运行了MapReduce程序,但是由于启用了日志聚合,日志未存储在本地——自动生成路径~/Hadoop_test/userlogs,但是为空

Slave2——虽然是数据节点,并运行了MapReduce程序,但是由于启用了日志聚合,日志未存储在本地——自动生成路径~/Hadoop_test/userlogs,但是为空

以上
Hadoop2.9下运行JAR包时System.out.println的输出日志的更多相关文章
- 导出成可运行jar包时所遇问题的解决办法 - 转载
Could not find main method from given launch configuration 当我把我的Java工程导出为可运行的jar包时,遇到了“Could not fin ...
- Linux下运行jar包
方法① 1.vim xxx.jar 2.配置程序入口:找到MANIFEST.MF,添加Main-Class:+空格+package.class 3.引入第三方jar包:①在MANIFEST.MF中加入 ...
- IntelliJ IDEA打可运行jar包时的错误
1.[ERROR] 'build.resources.resource.directory' 解决:需要在pom.xml的project->build->resources节点下,加入以 ...
- spark-sql用hive表格,在spark-submit运行jar包时遇到的问题
1.编程时无法加载hive包,需要在编译好的spark(用spark-shell启动,用spark-sql能够直接访问hive表)的lib目录下,考出assembly包,为其创建一个maven的rep ...
- 在linux系统下运行jar包的命令如下
1.java -jar xxxxx.jar // 当前ssh窗口被锁定,可按CTRL + C打断程序运行,或直接关闭窗口,程序退出 2.java -jar xxxxx.jar & //当 ...
- java -jar命令运行jar包时指定外部依赖jar包 linxux or windows
前尘回顾: setup.bat [chenquan@hostuser tartest]$ cat ../setup.sh javac -encoding UTF-8 -Djava.ext.dirs=. ...
- Hadoop 运行jar包时 java.lang.ClassNotFoundException: Class com.zhen.mr.RunJob$HotMapper not found
错误如下 Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.zhen.mr.RunJob$H ...
- windows 下启动运行 jar 包程序
windows 下 运行 jar 包 java -jar XXX.jar java -server -Xms1024m -Xmx20480m -jar $JAR_NAME.jar windows 后台 ...
- Intellij IDEA下导出Java工程的可运行JAR包
Intellij IDEA下导出Java工程的可运行JAR包 昨天一直向导出一个Java工程的可运行JAR包,然后查阅网上的资料以及自己一遍一遍的尝试,均以失败告终.可以导出JAR包,但是导出的JAR ...
随机推荐
- window.location.href = window.location.href window.location.reload()
w 0-会议预订提交了预订日期,预订成功后默认显示仅显示当前日期的新页面若显示预定日的信息,则可以对预定日存入cookie: http://stackoverflow.com/questions/24 ...
- filebeat 简介安装
Filebeat is a lightweight shipper for forwarding and centralizing log data. Installed as an agent on ...
- System.Core, Version=2.0.5.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e, Retargetable=Yes”
“System.Core, Version=2.0.5.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e, Retargetable=Yes” 或 ...
- python学习之路-第八天-文件IO、储存器模块
文件IO.储存器模块 文件IO 代码示例: # -*- coding:utf-8 -*- #! /usr/bin/python # filename:using_file.py poem = '''\ ...
- Linux用户、群组及权限
由于对文件的操作需要切换到相应文件夹下进行,所以对文件内容的修改,最基本的是需要其文件夹执行的权限. 文件夹的读权限(read)可以独立行使,但是对文件夹内容的写权限(对其内文件的新建.删除.重命名) ...
- WinForm下的Nhibernate+Spring.Net的框架配置文件
1.先将配置文件放到如下:<?xml version="1.0" encoding="utf-8"?> <configuration> ...
- (转)HttpWebRequest以UTF-8编码写入内容时发生“Bytes to be written to the stream exceed the Content-Length bytes size specified.”错误
from:http://www.cnblogs.com/Gildor/archive/2010/12/13/1904060.html HttpWebRequest以UTF-8编码写入内容时发生“Byt ...
- Spring框架学习之IOC(二)
Spring框架学习之IOC(二) 接着上一篇的内容,下面开始IOC基于注解装配相关的内容 在 classpath 中扫描组件 <context:component-scan> 特定组件包 ...
- HDU - 3488 Tour (KM最优匹配)
题意:对一个带权有向图,将所有点纳入一个或多个环中,且每个点只出现一次,求其所有环的路径之和最小值. 分析:每个点都只出现一次,那么换个思路想,每个点入度出度都为1.将一个点拆成两个点,一个作为入度点 ...
- ThreadLocal管理登录信息
通常在项目中,用户登录后,我们会将用户的信息存到session,如果想在其它地方获取session中的用户信息,我们需要先获取HttpServletRequest,再通过request.getSess ...