经典排序算法的总结及其Python实现
经典排序算法总结:
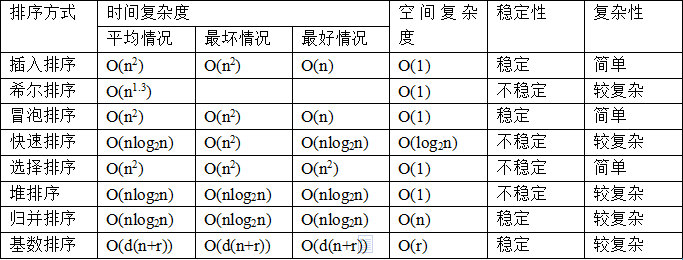
结论:
排序算法无绝对优劣之分。
不稳定的排序算法有:选择排序、希尔排序、快速排序、堆排序(口诀:“快速、选择、希尔、堆”)。其他排序算法均为稳定的排序算法。
第一趟排序后就能确定某个元素最终位置的有:选择排序、冒泡排序、快速排序、堆排序。
快速排序“偏爱”基本无序的序列。
希尔排序的关键在于步长的选择,希尔排序的时间复杂度和步长的选择有关。
快速排序之所以叫快速排序,并不代表它比堆排序、归并排序优良,在最好情况下它的渐进复杂度与堆排序、归并排序相同,只是它的常量系数比较小而已。
工程上的排序是综合排序,当数组较小时,选择插入排序;数组较大时,选择快速排序或其他O(n*log n)的排序。
排序算法的Python实现
1.冒泡排序:
冒泡排序就是把小的元素往前调(或者把大的元素往后调)。注意是相邻的两个元素进行比较,而且是否需要交换也发生在这两个元素之间。
实现代码:
## 1.冒泡排序
def bubbleSort(array):
for times in range(len(array)-1,0,-1):
for i in range(times):
if array[i]>array[i+1]:
temp=array[i]
array[i]=array[i+1]
array[i+1]=temp
return array
2.选择排序:
选择排序即是给每个位置选择待排序元素中当前最小的元素。比如给第一个位置选择最小的,在剩余元素里面给第二个位置选择次小的,
依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。
代码实现一:(推荐)
## 2.选择排序
def selectSort(array):
for i in range(len(array)-1):
small=i
for j in range(i+1,len(array)):
if array[j]<array[small]:
small=j
if small!=i:
temp=array[small]
array[small]=array[i]
array[i]=temp
return array
代码实现二:
# Finds the smallest value in an array
def findSmallest(arr):
# Stores the smallest value
smallest = arr[0]
# Stores the index of the smallest value
smallest_index = 0
for i in range(1, len(arr)):
if arr[i] < smallest:
smallest = arr[i]
smallest_index = i
return smallest_index # Sort array
def selectionSort(arr):
newArr = []
for i in range(len(arr)):
# Finds the smallest element in the array and adds it to the new array
smallest = findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr print selectionSort([5, 3, 6, 2, 10])
3.插入排序:
插入排序是在一个已经有序的小序列的基础上,一次插入一个元素。当然,刚开始这个有序的小序列只有1个元素,也就是第一个元素(默认它有序)。
比较是从有序序列的末尾开始,也就是把待插入的元素和已经有序的最大者开始比起,如果比它大则直接插入在其后面。
否则一直往前找直到找到它该插入的位置。如果遇见一个与插入元素相等的,那么把待插入的元素放在相等元素的后面。
代码实现:
## 3. 插入排序
def insertSort(array):
for i in range(1,len(array)):
curr_val=array[i]
pos=i
while pos>0 and array[pos-1]>curr_val:
array[pos]=array[pos-1]
pos-=1
array[pos]=curr_val
return array
4.快速排序:
递归实现:
def quicksort(array):
if len(array) < 2:
# base case, arrays with 0 or 1 element are already "sorted"
return array
else:
# recursive case
pivot = array[0]
# sub-array of all the elements less than the pivot
less = [i for i in array[1:] if i <= pivot]
# sub-array of all the elements greater than the pivot
greater = [i for i in array[1:] if i > pivot]
return quicksort(less) + [pivot] + quicksort(greater) print quicksort([10, 5, 2, 3])
非递归实现:写起来比较复杂。
5.归并排序
## 5.归并排序(递归实现) def merge(left, right):
res = []
i, j = 0, 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
res+=left[i:]
res+=right[j:] return res def mergeSort(array):
if len(array)<=1:
return array
mid=len(array)//2
left=mergeSort(array[:mid])
right=mergeSort(array[mid:]) return merge(left,right)
6.堆排序
## 6.堆排序(以最大堆为例)
def heapSort(array):
first=len(array)//2-1
# 从最后一个有孩子节点的节点开始调整最大堆
for i in range(first,-1,-1):
sift_down(array,i,len(array)-1) #将最大的值放到堆的最后一个位置,然后继续调整排序
for j in range(len(array)-1,0,-1):
array[0],array[j]=array[j],array[0]
sift_down(array,0,j-1)
return array def sift_down(array,start,end):
root=start
# 从 root 开始对最大堆进行调整
while True:
# 左孩子节点
child = 2*root+1
if child>end:#如果超出范围,直接跳出
break
# 左右孩子节点的值比较,选出大的那个
if child+1<=end and array[child+1]>array[child]:
child+=1
# 将大值调整到root的位置
if array[root]<array[child]:
array[root],array[child]=array[child],array[root]
root=child
else:
break
7.希尔排序
## 7.希尔排序
def shellSort(array):
gap=len(array)//2
n=len(array)
while gap>=1:
for j in range(gap,n):
i=j
while i-gap>=0:
if array[i]<array[i-gap]:
array[i], array[i-gap] = array[i-gap], array[i]
i-=gap
else:
break
gap//=2 return array
8.基数排序
基数排序时借助于多关键字的思想进行排序的。
基数排序时一种按最低位优先法(Least Significant Digit First,LSD)排序的方法。它利用“分配”和“收集”两种运算实现排序。
基数排序的主要思想:假设单关键字ki可以分解为d个分量ki0,ki1,ki2,...,kid-1,其中最低位是kid-1,最高位是ki0,每个分量都有radix个取值,radix称为基数,比如整数614按radix=10可以分解成d=3个分量。基数排序先按最低位kid-1将序列R中的n个元素“分配”到0~radix-1个队列中,再按队列顺序“收集”到R,完成第一趟排序;第二趟排序按kid-2将序列R中的n个元素“分配”到0~radix-1个队列中,再按队列顺序“收集”到R,知道最后一趟按ki0“分配”和“收集”完成后,排序结束。
该算法对n个元素共进行d趟排序,每趟的“分配”需要将元素放到radix个队列中,“收集”需要收集n个元素,这样一趟“分配”和“收集”的时间为O(radix+n),因此总的时间复杂度为O(d*(radix+n))
基数排序只有等到排序结束后才能确定元素的最终位置。它是稳定的排序方法。
9.计数排序
两者思想来源于桶排序
它们不是局域比较的排序算法,时间复杂度为O(N),空间复杂度为O(M),M为选择的桶的数量,相当于以空间换时间。
具体代码实现见参考链接
二分查找:
对于有序,或者某些部分有序的序列,查找满足题意的一个数,可以考虑使用二分查找(或者二分查找的变形)
经典的二分查找(查找有序数组中的某个值)代码如下:
# 二分查找
def binarySearch(array,val):
start=0
end=len(array)-1
found=False
#mid=(start+end)//2
while start<=end and not found:
mid=start+(end-start)//2 #这样写不会溢出,更安全
if array[mid]==val:
found=True
else:
if array[mid]<val:
start=mid+1
else:
end=mid-1
return found print(binarySearch([0,1,2,8,13,17,19,32,42],9))
参考:
桶排序&基数排序&计数排序:https://www.cnblogs.com/linxiyue/p/3555175.html
https://blog.csdn.net/xiaotao_1/article/details/78278622
经典排序算法的总结及其Python实现的更多相关文章
- 经典排序算法总结与实现 ---python
原文:http://wuchong.me/blog/2014/02/09/algorithm-sort-summary/ 经典排序算法在面试中占有很大的比重,也是基础,为了未雨绸缪,在寒假里整理并用P ...
- 经典排序算法及python实现
今天我们来谈谈几种经典排序算法,然后用python来实现,最后通过数据来比较几个算法时间 选择排序 选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理是每一次从待排序的数据 ...
- 十大经典排序算法(python实现)(原创)
个人最喜欢的排序方法是非比较类的计数排序,简单粗暴.专治花里胡哨!!! 使用场景: 1,空间复杂度 越低越好.n值较大: 堆排序 O(nlog2n) O(1) 2,无空间复杂度要求.n值较大: 桶排序 ...
- python 经典排序算法
python 经典排序算法 排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存.常见的内部排序算 ...
- 经典排序算法及总结(python实现)
目录 1.排序的基本概念和分类 排序的稳定性: 内排序和外排序 影响内排序算法性能的三个因素: 根据排序过程中借助的主要操作,可把内排序分为: 按照算法复杂度可分为两类: 2.冒泡排序 BubbleS ...
- python实现十大经典排序算法
Python实现十大经典排序算法 代码最后面会给出完整版,或者可以从我的Githubfork,想看动图的同学可以去这里看看: 小结: 运行方式,将最后面的代码copy出去,直接python sort. ...
- 用Python实现十大经典排序算法-插入、选择、快速、冒泡、归并等
本文来用图文的方式详细讲解了Python十大经典排序算法 —— 插入排序.选择排序.快速排序.冒泡排序.归并排序.希尔排序.插入排序.桶排序.基数排序.计数排序算法,想要学习的你们,继续阅读下去吧,如 ...
- 十大经典排序算法最强总结(含Java、Python码实现)
引言 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法.排序算法在很多领域得到相当地重视,尤其是在大量数据的处理方面 ...
- python基础__十大经典排序算法
用Python实现十大经典排序算法! 排序算法是<数据结构与算法>中最基本的算法之一.排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大, ...
随机推荐
- Unix系统编程(一)
主要内容:文件输入/输出的系统调用. 在Linux中,万事万物皆文件. 文件描述符的概念 通用I/O模型的系统调用: 打开文件 open 关闭文件 close 向文件写数据 write 从文件读数据 ...
- JVM源码分析之Metaspace解密
概述 metaspace,顾名思义,元数据空间,专门用来存元数据的,它是jdk8里特有的数据结构用来替代perm,这块空间很有自己的特点,前段时间公司这块的问题太多了,主要是因为升级了中间件所 ...
- js 控制按钮点击后不可用
<input type="button" id="btn" value="免费获取验证码" /> <script type ...
- mfc小工具开发之定时闹钟之---多线程急线程同步
一.MFC对多线程编程的支持 MFC中有两类线程,分别称之为工作者线程和用户界面线程.二者的主要区别在于工作者线程没有消息循环,而用户界面线程有自己的消息队列和消息循环. 工作者线程没有消息机制,通常 ...
- abp项目如何按业务功能模块横向分割?
1.为什么要做分层? 请先看项目分层的最后结构: 2.设计的初衷 项目较大,且主题鲜明,分为:BI模块.DM-用户洞察模块.Manage-应用管理模块.Report应用分析报表模块,大模块之间并无依赖 ...
- smartJS 0.1 API 讲解 - Trigger
上篇介绍了PromiseEvent,本篇介绍Trigger - 基于Promise的aop的体现:(感觉自己的对这些命名一直都很挫,也懒得想了,所以就凑合的用) Trigger 在目标对象上加入触发器 ...
- ajax 跨域 4种方法
一,传统的ajax方法 1,js代码 查看复制打印? $("#ajax").click(function(){ $.ajax({ type: "POST", u ...
- 利用jsonrpc技术包装uiautomator
昨天一天在网上搜索解决上一篇文章中的exception: monkeyrunner内置uiautomator出错的原因 尽管没找到解决办法.可是让我无意中发现了一个好工具,比sl4a更好用的工具.直接 ...
- py-faster-rcnn 训练自己的数据
转载:http://blog.csdn.net/sinat_30071459/article/details/51332084 Faster-RCNN+ZF用自己的数据集训练模型(Python版本) ...
- iOS开发,利用文件流,算大文件的MD5值(程序不会导致内存崩溃)
CFStringRef FileMD5HashCreateWithPath(CFStringRef filePath, size_t chunkSizeForReadingData) { // Dec ...