Django基础(ORM)
数据库与ORM
数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:


DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'books', #你的数据库名称
'USER': 'root', #你的数据库用户名
'PASSWORD': '', #你的数据库密码
'HOST': '', #你的数据库主机,留空默认为localhost
'PORT': '3306', #你的数据库端口
}
}
注意:
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。 设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。 然后,启动项目,会报错:no module named MySQLdb 这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入: import pymysql
pymysql.install_as_MySQLdb() 问题解决!
总结详细步骤:
1. 手动创建数据库
2. 在app/models.py里面写上一个类,必须继承models.Model这个类 (注意启动Django项目)
3. 在Django 项目的settings.py 里面 配置上数据库的相关信息
4. 在Django项目里的__init__.py里面写上 两句话 import pymysql pymysql.install_as_MySQLdb()
5. 给Django发布命令
1. python manage.py makemigrations # 相当于去你的models.py 里面看一下有没有改动
2. python manage.py migrate # 把改动翻译成SQL语句,然后去数据库执行
ORM表模型
表(模型)的创建:
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名。
作者详细模型:把作者的详情放到详情表,包含性别,email地址和出生日期,作者详情模型和作者模型之间是一对一的关系(one-to-one)(类似于每个人和他的身份证之间的关系),在大多数情况下我们没有必要将他们拆分成两张表,这里只是引出一对一的概念。
出版商模型:出版商有名称,地址,所在城市,省,国家和网站。
书籍模型:书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many),一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many),也被称作外键
from django.db import models<br>
class Publisher(models.Model):
name = models.CharField(max_length=30, verbose_name="名称")
address = models.CharField("地址", max_length=50)
city = models.CharField('城市',max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField() class Meta:
verbose_name = '出版商'
verbose_name_plural = verbose_name def __str__(self):
return self.name class Author(models.Model):
name = models.CharField(max_length=30)
def __str__(self):
return self.name class AuthorDetail(models.Model):
sex = models.BooleanField(max_length=1, choices=((0, '男'),(1, '女'),))
email = models.EmailField()
address = models.CharField(max_length=50)
birthday = models.DateField()
author = models.OneToOneField(Author) class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2,default=10)
def __str__(self):
return self.title
分析代码:
<1> 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
<2> 每个模型相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。大家可以留意下其它的类型都和数据库里的什么字段对应。
<3> 模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
简单的增删改查
查询数据时需要注意查询结果为单个对象还是数据对象的列表
# 增
models.Tb1.objects.create(c1='xx', c2='oo') # 增加一条数据,可以接受字典类型数据 **kwargs
obj = models.Tb1(c1='xx', c2='oo')
obj.save() # 查
models.Tb1.objects.get(id=123) # 获取单条数据,不存在则报错(不建议)
models.Tb1.objects.all() # 获取全部
models.Tb1.objects.filter(name='seven') # 获取指定条件的数据
models.Tb1.objects.exclude(name='seven') # 去除指定条件的数据 # 删
# models.Tb1.objects.filter(name='seven').delete() # 删除指定条件的数据 # 改
models.Tb1.objects.filter(name='seven').update(gender='0') # 将指定条件的数据更新,均支持 **kwargs
obj = models.Tb1.objects.get(id=1)
obj.c1 = '111'
obj.save() # 修改单条数据
ORM之增(create,save)
from app01.models import *
#create方式一: Author.objects.create(name='Alvin')
#create方式二: Author.objects.create(**{"name":"alex"})
#save方式一: author=Author(name="alvin")
author.save()
#save方式二: author=Author()
author.name="alvin"
author.save()
重点来了------->那么如何创建存在一对多或多对多关系的一本书的信息呢?(如何处理外键关系的字段如一对多的publisher和多对多的authors)
#一对多(ForeignKey):
#方式一: 由于绑定一对多的字段,比如publish,存到数据库中的字段名叫publish_id,所以我们可以直接给这个
# 字段设定对应值:
Book.objects.create(title='php',
publisher_id=2, #这里的2是指为该book对象绑定了Publisher表中id=2的行对象
publication_date='2017-7-7',
price=99)
#方式二:
# <1> 先获取要绑定的Publisher对象:
pub_obj=Publisher(name='河大出版社',address='保定',city='保定',
state_province='河北',country='China',website='http://www.hbu.com')
OR pub_obj=Publisher.objects.get(id=1)
# <2>将 publisher_id=2 改为 publisher=pub_obj
#多对多(ManyToManyField()):
author1=Author.objects.get(id=1)
author2=Author.objects.filter(name='alvin')[0]
book=Book.objects.get(id=1)
book.authors.add(author1,author2)
#等同于:
book.authors.add(*[author1,author2])
book.authors.remove(*[author1,author2])
#-------------------
book=models.Book.objects.filter(id__gt=1)
authors=models.Author.objects.filter(id=1)[0]
authors.book_set.add(*book)
authors.book_set.remove(*book)
#-------------------
book.authors.add(1)
book.authors.remove(1)
authors.book_set.add(1)
authors.book_set.remove(1)
#注意: 如果第三张表是通过models.ManyToManyField()自动创建的,那么绑定关系只有上面一种方式
# 如果第三张表是自己创建的:
class Book2Author(models.Model):
author=models.ForeignKey("Author")
Book= models.ForeignKey("Book")
# 那么就还有一种方式:
author_obj=models.Author.objects.filter(id=2)[0]
book_obj =models.Book.objects.filter(id=3)[0]
s=models.Book2Author.objects.create(author_id=1,Book_id=2)
s.save()
s=models.Book2Author(author=author_obj,Book_id=1)
s.save()
ORM之删(delete)
>>> Book.objects.filter(id=1).delete()
(3, {'app01.Book_authors': 2, 'app01.Book': 1})
我们表面上删除了一条信息,实际却删除了三条,因为我们删除的这本书在Book_authors表中有两条相关信息,这种删除方式就是django默认的级联删除
ORM之改(update和save)
实例:
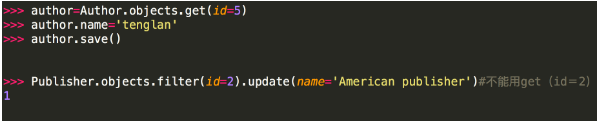
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列
#---------------- update方法直接设定对应属性----------------
models.Book.objects.filter(id=3).update(title="PHP")
##sql:
##UPDATE "app01_book" SET "title" = 'PHP' WHERE "app01_book"."id" = 3; args=('PHP', 3) #--------------- save方法会将所有属性重新设定一遍,效率低-----------
obj=models.Book.objects.filter(id=3)[0]
obj.title="Python"
obj.save()
# SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price",
# "app01_book"."color", "app01_book"."page_num",
# "app01_book"."publisher_id" FROM "app01_book" WHERE "app01_book"."id" = 3 LIMIT 1;
#
# UPDATE "app01_book" SET "title" = 'Python', "price" = 3333, "color" = 'red', "page_num" = 556,
# "publisher_id" = 1 WHERE "app01_book"."id" = 3;
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
Django项目完整版LOGGING配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]'
},
'simple': {
'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
},
'collect': {
'format': '%(message)s'
}
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
'handlers': {
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'], # 只有在Django debug为True时才在屏幕打印日志
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_info.log"), # 日志文件
'maxBytes': 1024 * 1024 * 50, # 日志大小 50M
'backupCount': 3,
'formatter': 'standard',
'encoding': 'utf-8',
},
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_err.log"), # 日志文件
'maxBytes': 1024 * 1024 * 50, # 日志大小 50M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
'collect': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_collect.log"),
'maxBytes': 1024 * 1024 * 50, # 日志大小 50M
'backupCount': 5,
'formatter': 'collect',
'encoding': "utf-8"
}
},
'loggers': {
# 默认的logger应用如下配置
'': {
'handlers': ['default', 'console', 'error'], # 上线之后可以把'console'移除
'level': 'DEBUG',
'propagate': True,
},
# 名为 'collect'的logger还单独处理
'collect': {
'handlers': ['console', 'collect'],
'level': 'INFO',
}
},
}
ORM之查(filter,value)
查询API:
# 查询相关API: # <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <2>all(): 查询所有结果 # <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <6>order_by(*field): 对查询结果排序 # <7>reverse(): 对查询结果反向排序 # <8>distinct(): 从返回结果中剔除重复纪录 # <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <11>first(): 返回第一条记录 # <12>last(): 返回最后一条记录 # <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False
使用示例
models.Class.objects.values("id")
<QuerySet [{'id': 1}, {'id': 3}]>
(0.001) SELECT `app01_class`.`id` FROM `app01_class` LIMIT 21; args=()
models.Class.objects.values("cname")
<QuerySet [{'cname': '全栈8期'}, {'cname': '全栈9期'}]>
(0.000) SELECT `app01_class`.`cname` FROM `app01_class` LIMIT 21; args=()
models.Class.objects.order_by("-id")
<QuerySet [<Class: 全栈9期>, <Class: 全栈8期>]>
(0.001) SELECT `app01_class`.`id`, `app01_class`.`cname`, `app01_class`.`first_day` FROM `app01_class` ORDER BY `app01_class`.`id` DESC LIMIT 21; args=()
models.Class.objects.order_by("id")
<QuerySet [<Class: 全栈8期>, <Class: 全栈9期>]>
(0.000) SELECT `app01_class`.`id`, `app01_class`.`cname`, `app01_class`.`first_day` FROM `app01_class` ORDER BY `app01_class`.`id` ASC LIMIT 21; args=()
models.Class.objects.values_list("id","cname")
(0.001) SELECT `app01_class`.`id`, `app01_class`.`cname` FROM `app01_class` LIMIT 21; args=()
<QuerySet [(1, '全栈8期'), (3, '全栈9期')]>
注意:一定区分Object与QuerySet的区别 !!!
QuerySet有update方法而Object默认没有
总结:
返回的是QuerySet对象:
1. all()
2. filter()
3. exclude()
4. valus()
5. values_list()
6. order_by()
7. reverse()
8. distinct()
返回数字的:
1. count()
返回布尔值的:
1. exists()
返回具体的数据对象的:
1. get()
2. first()
3. last()
单表查询之神奇的双下划线
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") # 获取name字段包含"ven"的
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 3]) # id范围是1到3的,等价于SQL的bettwen and 类似的还有:startswith,istartswith, endswith, iendswith date字段还可以:
models.Class.objects.filter(first_day__year=2017)
Django基础(ORM)的更多相关文章
- Django基础——ORM字段和字段参数
ORM概念: 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象( 1. 不同的程序员写的SQL水平参差不齐 2. ...
- Django 基础 ORM系统
Object Relational Mapping(ORM) ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据 ...
- {Django基础六之ORM中的锁和事务}一 锁 二 事务
Django基础六之ORM中的锁和事务 本节目录 一 锁 二 事务 一 锁 行级锁 select_for_update(nowait=False, skip_locked=False) #注意必须用在 ...
- day 67 django 之ORM 基础安装
一 ORM的基础部分 1 ORM的概念 对象关系映射(Object Relational Mapping(映射),简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 2 ...
- day 71 Django基础六之ORM中的锁和事务
Django基础六之ORM中的锁和事务 本节目录 一 锁 二 事务 三 xxx 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 锁 行级锁 select_for_update(no ...
- day 58 Django基础六之ORM中的锁和事务
Django基础六之ORM中的锁和事务 本节目录 一 锁 二 事务 三 xxx 四 xxx 五 xxx 六 xxx 七 xxx 八 xxx 一 锁 行级锁 select_for_update( ...
- Django基础二静态文件和ORM
Django基础二静态文件和ORM 目录 Django基础二静态文件和ORM 1. 静态文件 1.1 静态文件基本配置: 1.2 静态文件进阶配置 2. request参数 3. Django配置数据 ...
- Django基础四之测试环境和ORM查询
Django基础四之测试环境和ORM查询 目录 Django基础四之测试环境和ORM查询 1. 搭建测试环境 1.1 测试环境搭建方法: 1.2 使用测试环境对数据库进行CURD 1.3 返回Quer ...
- Django之ORM基础
ORM简介 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用描述 ...
随机推荐
- linux下安装python的第三方module
1.首先需要有python环境 2.安装pip软件:下载地址,https://pypi.python.org/pypi/pip/6.0.8 解压pip的压缩包:sudo tar -zxvf pip-6 ...
- windows-redis 集群搭建
Windows 配置Reids集群 Redis Cluster 1. 下载安装Redis Redis官方不支持Windows,但是Microsoft Open Tech group在 GitHub上开 ...
- 极光Java后台推送APP对接
1.极光对接,首先需要注册用户,和创建应用 2,.Java对接需要依赖包 <dependency> <groupId>cn.jpush.api</groupId> ...
- Oracle 10gR2 RAC 启动与关闭
一. 检查共享设备 一般情况下, 存放OCR 和 Voting Disk 的OCFS2 或者raw 都是自动启动的. 如果他们没有启动,RAC 肯定是启动不了的. 1.1 如果使用ocfs2的,检查o ...
- MathType可以编辑带圈乘号吗
在数学中有很多符号,可能这些符号我们用得上,也有些符号我们很少用,甚至用不上,但是我们用不上,不代表不存在这个符号,也不代表别人用不上,只是各自所涉及到的知识领域不一样而已.而对于加减乘除运算,几乎每 ...
- poj 3249(bfs+dp或者记忆化搜索)
题目链接:http://poj.org/problem?id=3249 思路:dp[i]表示到点i的最大收益,初始化为-inf,然后从入度为0点开始bfs就可以了,一开始一直TLE,然后优化了好久才4 ...
- Linux shell(. /path/filename)
在 /etc/profile 文件中,有一段脚本: if [ -f /etc/bash.bashrc ]; then . /etc/bash.bashrc fi 这里的 “点号 + 空格 + 文件” ...
- 彻底解决 webpack 打包文件体积过大
http://www.jianshu.com/p/a64735eb0e2b https://segmentfault.com/q/1010000006018592?_ea=985024 http:// ...
- Echoprint系列--编译
近期要做一个音乐相关的client.当中一个功能是音乐识别.搜索了一些资料选择Echoprint来开发.Echoprint是开源免费的,并且多种client都支持能节约非常多时间,今天主要下载和编译源 ...
- golang 内置函数new()
new() 这是一个用来分配内存的内置函数,它的第一个参数是一个类型,不是一个值,它的返回值是一个指向新分配的 t 类型的零值的指针. 在golang的代码定义如下: func new(t Type) ...