【Spark】源码分析之RDD的生成及stage的切分
一、概述
Spark源码整体的逻辑(spark1.3.1):
从saveAsTextFile()方法入手
-->saveAsTextFile()
--> saveAsHadoopFile()
--> 封装hadoopConf,并传入saveAsHadoopDataset()方法
--> 拿到写出流SaprkHadoopWriter,调用self.context.runJob(self,writeToFile)
--> runJob方法中,使用dagScheduler划分stage
--> submitJob开始提交作业
-->任务处理器的post方法启动线程,获取队列中的任务,并调用onRecevie()方法提交任务
-->调用handleJobSubmitted,使用newStage中的getParentStage方法对stage进行切分
-->getParentStage方法中,使用HashSet、Stack来存放stage和RDD,用栈来存储RDD主要是为了便于后面通过循环进行模式匹配,判断该RDD和父RDD的依赖关系,如果是宽依赖就会生成stage,如果是窄依赖,就会继续找父RDD
二、Spark源码详情
1. 在spark1.3.1的源码中,saveAsTextFile的关键代码在于它内部调用了saveAsHadoopFile()方法。
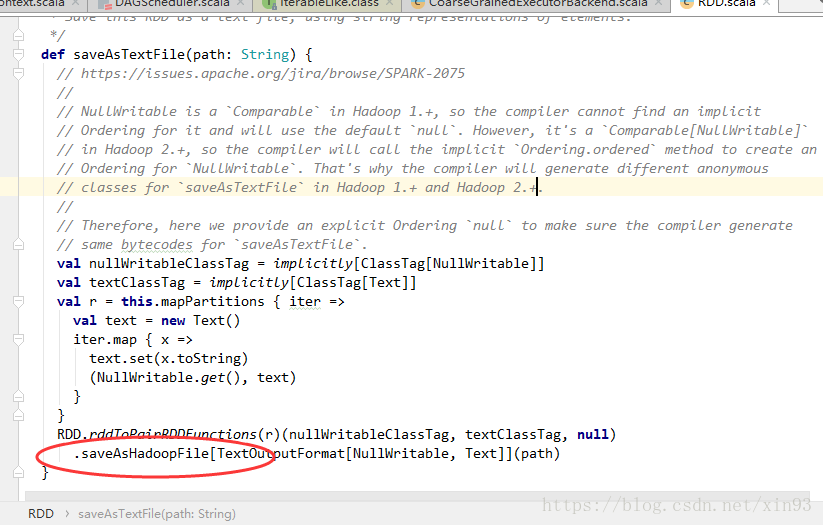
2. 进入到saveAsHadoopFile()方法中,首先spark会对配置信息进行封装,然后将配置信息传入saveAsHadoopDataset( )方法
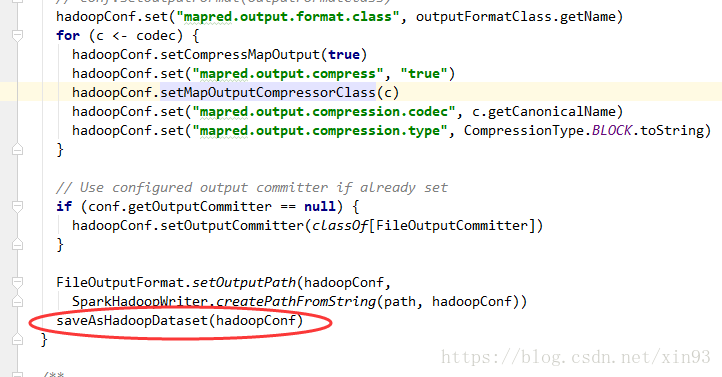
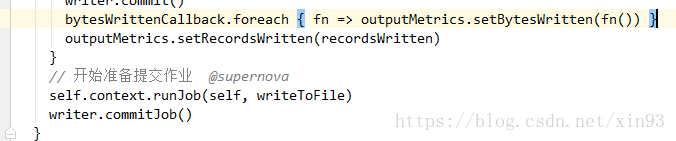
3. saveAsHadoopDataset()方法中将会拿到Spark的写出流,并调用runJob方法准备开始提交作业。

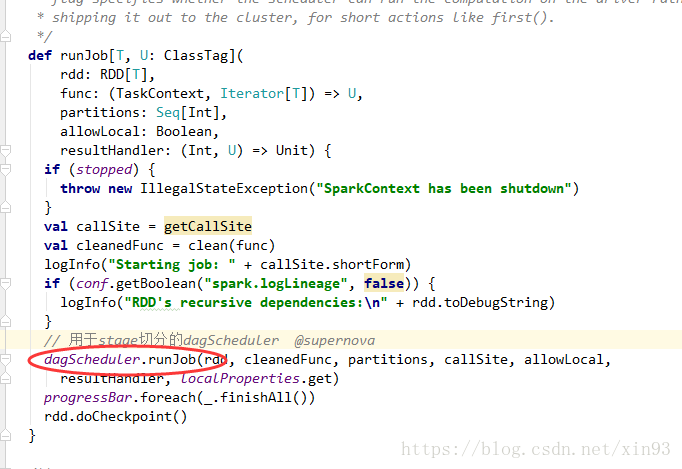
4. 进入runJob方法中,会使用dagScheduler进行stage的切分
5. submitJob开始提交作业

6. 获取finalRDD的分区数,并调用任务处理器的post方法,循环取出数据放入队列中
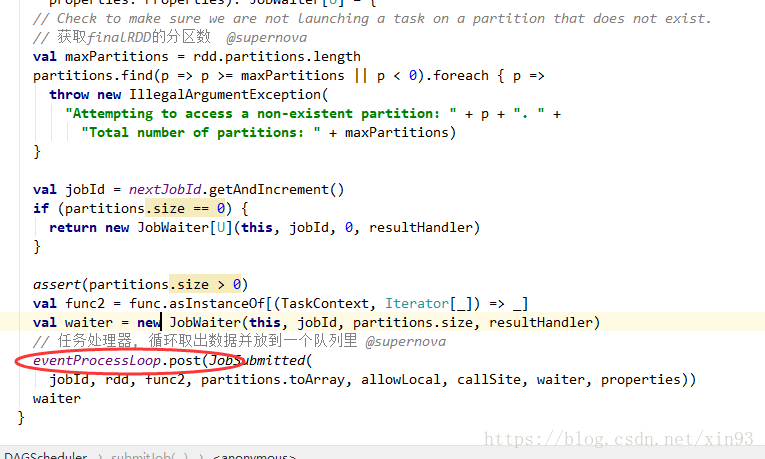
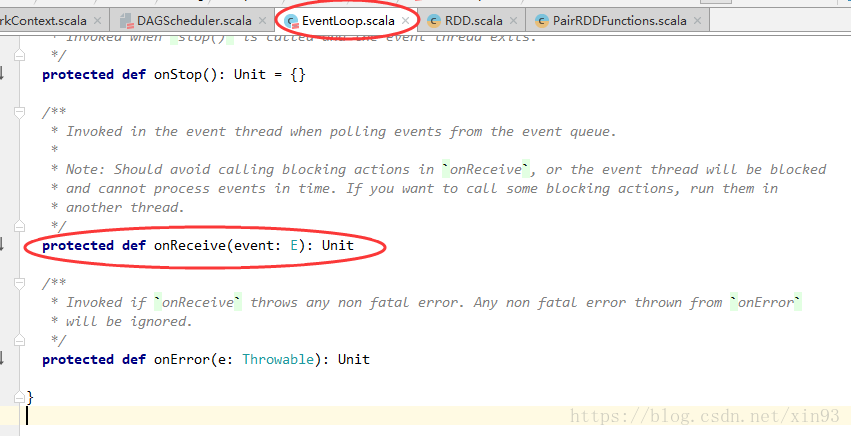
7. post方法中,将启动一个线程,将获取队列中的任务,并调用onRecevie()方法提交任务

8. 进入onReceive(),可以看到它是一个抽象类中的方法
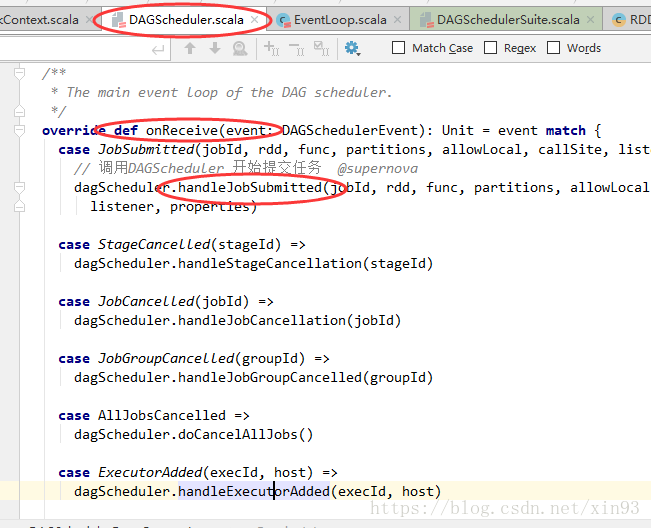
9. 方法的实现在DAGScheduler中,对方法进行模式匹配。 匹配到任务提交的方法后,调用handleJobSumitted提交任务
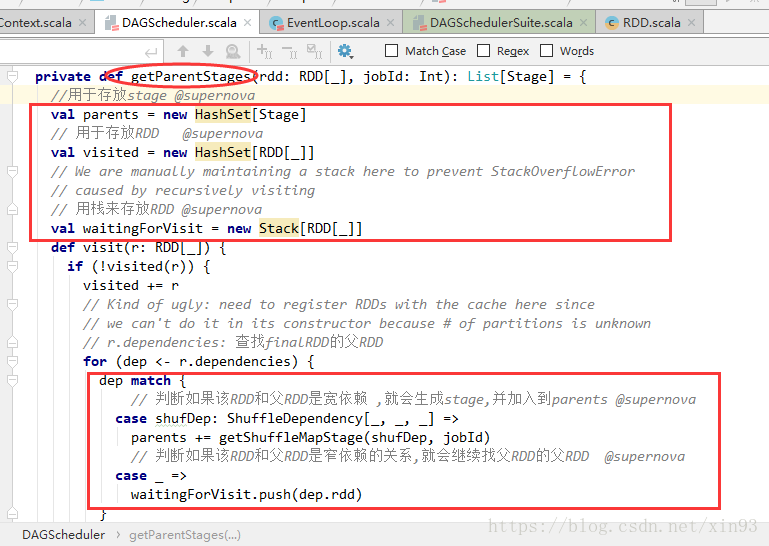
10. handleJobSubmitted中,使用newStage中的getParentStage方法对stage进行切分

11. getParentStage方法中,使用HashSet、Stack来存放stage和RDD,用栈来存储RDD主要是为了便于后面通过循环进行模式匹配,判断该RDD和父RDD的依赖关系,如果是宽依赖就会生成stage,如果是窄依赖,就会继续找父RDD
【Spark】源码分析之RDD的生成及stage的切分的更多相关文章
- spark 源码分析之一 -- RDD的四种依赖关系
RDD的四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和OneToOneDependency四种依赖关系.如 ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- Spark 源码分析系列
如下,是 spark 源码分析系列的一些文章汇总,持续更新中...... Spark RPC spark 源码分析之五--Spark RPC剖析之创建NettyRpcEnv spark 源码分析之六- ...
- spark源码分析以及优化
第一章.spark源码分析之RDD四种依赖关系 一.RDD四种依赖关系 RDD四种依赖关系,分别是 ShuffleDependency.PrunDependency.RangeDependency和O ...
- Spark源码分析 – DAGScheduler
DAGScheduler的架构其实非常简单, 1. eventQueue, 所有需要DAGScheduler处理的事情都需要往eventQueue中发送event 2. eventLoop Threa ...
- Spark源码分析:多种部署方式之间的区别与联系(转)
原文链接:Spark源码分析:多种部署方式之间的区别与联系(1) 从官方的文档我们可以知道,Spark的部署方式有很多种:local.Standalone.Mesos.YARN.....不同部署方式的 ...
- Spark源码分析 – Shuffle
参考详细探究Spark的shuffle实现, 写的很清楚, 当前设计的来龙去脉 Hadoop Hadoop的思路是, 在mapper端每次当memory buffer中的数据快满的时候, 先将memo ...
- Spark源码分析 – BlockManager
参考, Spark源码分析之-Storage模块 对于storage, 为何Spark需要storage模块?为了cache RDD Spark的特点就是可以将RDD cache在memory或dis ...
- Spark源码分析 – SparkContext
Spark源码分析之-scheduler模块 这位写的非常好, 让我对Spark的源码分析, 变的轻松了许多 这里自己再梳理一遍 先看一个简单的spark操作, val sc = new SparkC ...
随机推荐
- js 显示 base64编码 的二进制流 图片
Data URI scheme.Data URI scheme是在RFC2397中定义的,目的是将一些小的数据,直接嵌入到网页中,从而不用再从外部文件载入.比如上面那串字符,其实是一张小图片,将这些字 ...
- Windows下将jar包封装成服务程序
1 准备 使用工具Procrun(http://commons.apache.org/proper/commons-daemon/procrun.html),下载地址(http://archive.a ...
- ORACLE 收集统计信息
1. 理解什么是统计信息优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- SQL SERVER ->> IDENTITY相关函数
IDENTITY函数 -- 只能用在SELECT INTO语句中,用于在插入数据的时候模拟IDENTITY属性的作用生成自增长值. ,) AS ID_Num INTO NewTable FROM Ol ...
- 对于char *s1 和 char s2[] 的认识
对于char *s1 和 char s2[] 认识有误区(认为无区别),导致有时出现“难以理解”的错误. char *s1 = "hello"; char s2[] = " ...
- SAP人工智能服务Recast.AI的一个简单例子
关于这个例子的完整介绍,请参考公众号 "汪子熙"的两篇文章: SAP C/4HANA与人工智能和增强现实(AR)技术结合的又一个创新案例 和使用Recast.AI创建具有人工智能的 ...
- SAP CRM One order里user status和system status的mapping逻辑
Below example show: How the mapping relationship between User status and System status maintained in ...
- c++新标准的一个问题
显示转换运算符存在多个兼容版本的时候,explicit 关键字无效,编译器默认会选择那个兼容版本进行转换,而不是报错. 测试环境:gcc4.8.1 示例代码: class plebe { privat ...
- sublime text html5开发学习 插件篇记录
1.第一步先按照 Package Control,具体步骤自行百度,Google. 2. view in browser 默认的快捷键应该是这样的,我用的是IE浏览器.所以ctrl+alt+i 即可让 ...
- [原]零基础学习SDL开发之在Android使用SDL2.0渲染PNG图片
在上一篇文章我们知道了如何在android使用SDL2.0来渲染显示一张bmp图,但是如果是一张png或者一张jpg的图,那么还能显示成功么?答案是否定的 我们需要移植SDL_image库来支持除bm ...