GPGPU OpenCL/CUDA 高性能编程的10大注意事项
转载自:http://hc.csdn.net/contents/content_details?type=1&id=341
1.展开循环
如果提前知道了循环的次数,可以进行循环展开,这样省去了循环条件的比较次数。但是同时也不能使得kernel代码太大。
#include
using namespace std; int main(){
int sum=;
for(int i=;i<=;i++){
sum+=i;
} sum=;
for(int i=;i<=;i=i+){
sum+=i;
sum+=i+;
sum+=i+;
sum+=i+;
sum+=i+;
}
return ;
}
2.避免处理非标准化数字
OpenCL中非标准化数字,是指数值小于最小能表示的正常值。由于计算机的位数有限,表示数据的范围和精度都不可能是无限的。(具体可以查看IEEE 754标准,http://zh.wikipedia.org/zh-cn/IEEE_754)
在OpenCL中使用非标准化数字,可能会出现“除0操作”,处理很耗时间。
如果在kernel中“除0”操作影响不大的话,可以在编译选项中加入-cl-denorms-are-zero,如:
clBuildProgram(program, 0, NULL, "-cl-denorms-are-zero", NULL, NULL);
3.通过编译器选项传输常量基本类型数据到kernel,而不是使用private memory
如果程序中需要给kernel 传输常量基本类型数据,最好是使用编译器选项,比如宏定义。而不是,每个work-item都定义一个private memory变量。这样编译器在编译时,会直接进行变量替换,不会定义新的变量,节省空间。
如下面代码所示(Dmacro.cpp):
1 #include
2 int main()
3 {
4 int a=SIZE;
5 printf("a=%d, SIZE=%d\n",a,SIZE);
6 return 0;
7 }
编译:
g++ -DSIZE=128 -o A Dmacro.cpp
4.如果共享不重要的话,保存一部分变量在private memory而不是local memory
work-item访问private memory速度快于local memory,因此可以把一部分变量数据保存在private memory中。当然,当private memory容量满时,GPU硬件会自动将数据转存到local memory中。
5.访问local memory应避免bank conflicts
local memory被组织为一个一个的只能被单独访问的bank,bank之间交叉存储数据,以便连续的32bit被保存在连续的bank中。如下图所示:
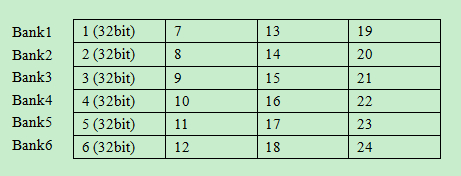
(1)如果多个work-item访问连续的local memory数据,他们就能最大限度的实现并行读写。
(2)如果多个work-item访问同一个bank中的数据,他们就必须顺序执行,严重降低数据读取的并行性。因此,要合理安排数据在local memory中的布局。
(3)特殊情况,如果一个wave/warp中的线程同时读取一个local memory中的一个地址,这时将进行广播,不属于bank 冲突。
6.避免使用”%“操作
"%"操作在GPU或者其他OpenCL设备上需要大量的处理时间,如果可能的话尽量避免使用模操作。
7.kernel中重用(Reuse) private memory,为同一变量定义不同的宏
如果kernel中有两个或者以上的private variable在代码中使用(比如一个在代码段A,一个在代码段B中),但是他们可以被数值相同。
也就是当一个变量用作不同的目的时,为了避免代码中的命名困惑,可以使用宏。在一个变量上定义不同的宏。
1 #include
2 int main(){
3 int i=4;
4 #define EXP i
5 printf("EXP=%d\n",EXP);
6
7 #define COUNT i
8 printf("COUNT=%d\n",COUNT);
9 getchar();
10 return 0;
11 }
8.对于(a*b+c)操作,尽量使用 fma function
如果定义了“FP_FAST_FMAF”宏,就可以使用函数fma(a,b,c)精确的计算a*b+c。函数fma(a,b,c)的执行时间小于或等于计算a*b+c。
9.在program file 文件中对非kernel的函数使用inline
inline修饰符告诉编译器在调用inline函数的地方,使用函数体替换函数调用。虽然会使得编译后的代码占用memory增加,但是省去了函数调用时上下、函数调用栈的切换操作,节省时间。
10.避免分支预测惩罚,应该尽量使得条件判断为真的可能性大
现代处理器一般都会进行“分支预测”,以便更好的提前“预取”下一条要执行的指令,使得“取指令、译码分析、执行、保存”尽可能的并行。
在“分支预测”出错时,提前取到的指令,不是要执行的指令,就需要根据跳转指令,进行重新取指令,就是“分支预测惩罚”。
看如下的代码:
#include
int main()
{
int i=;
int b=;
if(i == )
b=;
else
b=;
return ;
}
对应的汇编代码:
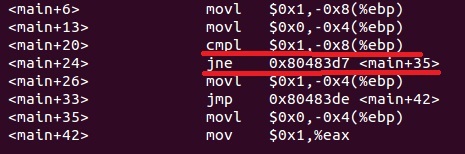
(movl 赋值,cmpl 比较,jne 不等于跳转,jmp 无条件跳转)
从上面的汇编指令代码看出,如果比较(<main+24>)结果相等,则执行<main+26>也就是比较指令的下一条指令,对应b=1顺序执行;如果比较(<main+24>)结果不相等,则执行跳转到<main+35>,不是顺序执行。
当然,有的处理器可能会根据以往“顺序执行”与“跳转执行”的比例来进行分支预测,但是这也是需要积累的过程。况且并不是,每个处理器多能这样只能。
最后,上面的10个tips,能过提升kernel函数的性能,但是你应该进行具体的性能分析知道程序中最耗时的地方在哪里。当然了,只有通过实验才能真正学会OpenCL高性能编程。
GPGPU OpenCL/CUDA 高性能编程的10大注意事项的更多相关文章
- 【并行计算-CUDA开发】GPGPU OpenCL/CUDA 高性能编程的10大注意事项
GPGPU OpenCL/CUDA 高性能编程的10大注意事项 1.展开循环 如果提前知道了循环的次数,可以进行循环展开,这样省去了循环条件的比较次数.但是同时也不能使得kernel代码太大. 循环展 ...
- CUDA高性能编程中文实战11章例子中多设备的例子编译提示问题
提示的问题如下: error : argument of type "void *(*)(void *)" is incompatible with parameter of ty ...
- PMP证书的获取,不知道10大注意事项会吃亏
作为一个已经考过PMP的小项目经理我来说,近来接到不少咨询PMP的,有咨询考试事宜的,也有咨询后续的换审和PDU的,今天我这边就说说PMP项目管理证书要获取的一些注意事项,不注意的话可是会吃大亏的. ...
- [问题解决]《GPU高性能编程CUDA实战》中第4章Julia实例“显示器驱动已停止响应,并且已恢复”问题的解决方法
以下问题的出现及解决都基于"WIN7+CUDA7.5". 问题描述:当我编译运行<GPU高性能编程CUDA实战>中第4章所给Julia实例代码时,出现了显示器闪动的现象 ...
- Golang优秀开源项目汇总, 10大流行Go语言开源项目, golang 开源项目全集(golang/go/wiki/Projects), GitHub上优秀的Go开源项目
Golang优秀开源项目汇总(持续更新...)我把这个汇总放在github上了, 后面更新也会在github上更新. https://github.com/hackstoic/golang-open- ...
- 人们对Python在企业级开发中的10大误解
From : 人们对Python在企业级开发中的10大误解 在PayPal的编程文化中存在着大量的语言多元化.除了长期流行的C++和Java,越来越多的团队选择JavaScript和Scala,Bra ...
- .NET高性能编程 - C#如何安全、高效地玩转任何种类的内存之Span的本质(一)。
前言 作为.net程序员,使用过指针,写过不安全代码吗? 为什么要使用指针,什么时候需要使用它,以及如何安全.高效地使用它? 如果能很好地回答这几个问题,那么就能很好地理解今天了主题了.C#构建了一个 ...
- Netty高性能编程备忘录(上)
http://calvin1978.blogcn.com/articles/netty-performance.html 网上赞扬Netty高性能的文章不要太多,但如何利用Netty写出高性能网络应用 ...
- (转)Android高性能编程(1)--基础篇
关于专题 本专题将深入研究Android的高性能编程方面,其中涉及到的内容会有Android内存优化,算法优化,Android的界面优化,Android指令级优化,以及Android应用内存占 ...
随机推荐
- 系统监控的一些工具w , vmstat
w 命令:--w 查看的是系统整体上的负载 # w 15:23:46 up 3:34, 2 users, load average: 0.03, 0.05, 0.00 USER TTY FROM LO ...
- jQuery EasyUI 提示框(Messager)用法
jQuery EasyUI 提示框(Messager)不仅强大,而且也不用任何的HTML代码,只需要按照<jQuery EasyUI框架使用文档>包含必要文件后,在$(function() ...
- 简单Linq笔记
Linq是.net 3.5才引入的 要引入命名空间System.Linq. Linq to XML要引入System.Xml.Linq Linq to ADO.NET要引入System.Data.L ...
- PHP程序缓存之文件缓存处理方式
PHP程序缓存之文件缓存处理方式在开发程序过程中,缓存的设置大大提升程序效率,减小数据库负载.基本配置缓存和常规配置缓存 基本配置缓存在项目开发中类似这样子的格式: 文件:config.php $CF ...
- XML2_XML的节点和元素
在JAVA语言中使用JAXP操作XML文件的时候,有两个接口,一个是Node,一个是Element,Element接口继承自Node接口. 在这一层次我们进一步理解XML中更具体的分类: 元素,属性, ...
- CCTV评论员评论步行者与奇才的比赛
步行者客场迎战主场作战的奇才,奇才的战士可能由于过度兴奋或是过度紧张身体僵硬,本来能打进的球都失掉了.反而,由于步行者取得了两位数的领先,越大心情越放松,打出了过去很少见的流畅局面. CCTV评论员就 ...
- ie8下jquery读取当前点击的标签位置错误,原因是里面有内容写了text-indent:-9999px
今天写一地图的效果,鼠标点击对应的区域,弹出所点击区域的名字. 因为设计的区域名字有特殊效果,所以,在点击区域里面套了个标签写上区域名字用来识别,但是这个文字呢不同显示在页面上,所以就给 em 加个了 ...
- python中enumerate的使用
在python的应用中,当我们使用一个数组或者列表的时候既要遍历索引又要遍历元素的时候通常的做法是这样的: >>> lsi = [1,2,3,4,5,6,7,8,9] >> ...
- 靓号正则表达式(前后向查找等) 和 apache正则包使用
一般公司在开发一类对的号码时,会预留一些号码给以后升级的会员使用,比如旺旺靓号,QQ号等,采用正则表达式实现较好,通过规则引擎的后台页面做成实时可配置的也是不错的选择. 一. 一般会有如下的正则需求 ...
- 使用 .NET 平台,如何玩转 Universal Windows 应用?
2015年7月30日 本文作者是 Managed Languages 团队项目经理 Lucian Wischik. 不久前,Visual Studio 2015上新增 Windows 10 应用的开发 ...