背景
我们使用的HiveServer2的版本为0.13.1-cdh5.3.2,目前的任务使用Hive SQL构建,分为两种类型:手动任务(临时分析需求)、调度任务(常规分析需求),两者均通过我们的Web系统进行提交。以前两种类型的任务都被提交至Yarn中一个名称为“hive”的队列,为了避免两种类型的任务之间相互受影响以及并行任务数过多导致“hive”队列资源紧张,我们在调度系统中构建了一个任务缓冲区队列,所有被提交的任务(手动任务、调度任务)并不会直接被提交至集群,而是提交至这个缓冲区队列中,然后固定数目的工作者线程再将缓冲区队列的任务取出提交至集群执行。
这种运行模式在运行任务数不是很多的情况下尚且可行,一旦我们的常规分析需求变多,调度任务数也会随之增加,这时临时分析需求建立的手动任务就可能会影响调度任务的执行,这种影响主要表现在以下两个方面:
(1)手动任务与调度任务共用一个队列“hive”,而队列“hive”的资源分配主要是根据调度任务的资源消耗情况进行分配的,这样随机提交的手动任务与调度任务共同执行时,就可能会影响原有调度任务的执行速度;而且无法根据两种任务各自的特性选择合适的调度策略(如:FIFO、Fair);
(2)手动任务的提交需要经过调度系统内部的缓冲区队列,如果调度任务比较多,则手动任务可能需要在缓冲区队列中等待很长的时间才能够提交至集群运行,而任务运行时所需资源需要与调度任务共享,执行时间无法保证,用户通常需要等待较长时间;
针对上述情况,我们对队列“hive”进行拆分:hive.temporary、hive.common,其中hive.temporary用于临时分析需求的手动任务,hive.common用于常规分析需求的调度任务,这样我们就可以根据业务的实际情况,为两者灵活的进行资源分配。
队列拆分之后,我们就有了如下思考:手动任务(临时分析需求)是否依然需要经过调度系统的缓冲区队列再提交至集群?
队列拆分一定程度上意味着资源的独立,亦即手动任务与调度任务之间做到了物理上的隔离,如果手动任务依然使用调度系统的缓冲区队列,则也必须是专门针对手动任务的队列;而手动任务是临时分析需求,不可能预留太多的资源给它,为了保证手动任务在可接受的时间内执行完成,我们必须限制队列“hive.temporary”可同时运行任务的数目,以此来保证正在运行的任务有足够的资源去执行;如果某个时间点提交给集群的手动任务超过队列“hive.temporary”可同时运行任务数目的限制,则它们会被暂时“堆积”在Yarn调度器的队列当中。
由此可见,我们并不需要再为手动任务在调度系统中建立专门的缓冲区队列,直接利用Yarn调度器的队列即可。我们可以直接将手动任务直接提交至集群,由Yarn调度器根据队列“hive.temporary”根据调度策略及目前队列资源使用情况决定是否运行任务。
因为现在的手动任务不经过调度系统的缓冲区队列直接提交至集群,则手动任务的提交可以不再受限于Web系统,用户可以通过Hive官方推荐的Beeline客户端直接提交Hive SQL。
这就涉及到本文的核心问题:Beeline连接HiveServer2后如何使用指定的队列(Yarn)运行Hive SQL语句?
解决方案
MapReduce运行队列的指定是通过配置(Configuration)属性“mapreduce.job.queuename”指定的。
大家可能首先想到的是通过“set mapreduce.job.queuename=queueName”的方式来选取运行队列,这在手动任务(临时分析需求)的场景下是不可取的,如前所述,我们为这类似的任务专门分配了相应的队列资源“hive.temporary”,我们必须能够保证用户通过Beeline连接HiveServer2后提交的Hive SQL语句运行在指定的队列“hive.temporary”中,而且用户无法随意更改运行队列,即无法随意更改属性“mapreduce.job.queuename”。
目前HiveServer2使用的权限控制策略为SQL Standard Based Hive Authorization和Storage Based Authorization in the Metastore Server。其中SQL Standard Based Hive Authorization会对Hive终端命令“set”做出限制:只能针对白名单(hive.security.authorization.sqlstd.confwhitelist)中列出的属性进行赋值。白名单默认包含一批属性,其中就包括“mapreduce.job.queuename”,我们需要通过配置文件hive-site.xml或者启动HiveServer2时通过参数“--hiveconf”设置白名单“hive.security.authorization.sqlstd.confwhitelist”的值,排除属性“mapreduce.job.queuename”,使得我们的用户通过Beeline连接至HiveServer2之后,无法随意更改“mapreduce.job.queuename”的值。
既然用户无法更改属性“mapreduce.job.queuename”,那么HiveServer2启动之后属性“mapreduce.job.queuename”必须具有一个默认值,即“hive.temporary”,这样用户通过Beeline连接HiveServer2之后提交的Hive SQL就会运行在队列“hive.temporary”中。那么,接下来的问题就是如果完成这个默认设定?
一般情况下,我们会这样认为,HiveServer2的运行至少涉及到两份配置文件:
(1)Hadoop:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
(2)Hive:hive-site.xml
这些配置文件中的属性值都会“打包”到MapReduce任务的配置属性中去。我们自然会想到在mapred-site.xml或者hive-site.xml中指定“mapreduce.job.queuename”即可,然而实际验证之后发现情况并不是这样的。
(1)在hive-site.xml(mapred-site.xml)中指定“mapreduce.job.queuename”;
(2)测试指定值“test”是否生效;
我们发现通过Beeline使用账号“hdfs”连接至HiveServer2后,属性“mapreduce.job.queuename”的值被替换为“root.hdfs”,实际执行Hive SQL语句时也会发现相应的MapReduce任务被提交至队列“root.hdfs”。
其中的一个解决方案如下:
其实质就是通过建立连接时的URL参数传递属性值。
但是这种方法对于我们没有用处,我们不可能强制我们的用户连接HiveServer2时都指定队列,但这个解决方案给了我们一个思路:既然我们可以通过“客户端”建立连接时初始化属性值,那么“服务端”接受连接时会不会也有初始化的操作?
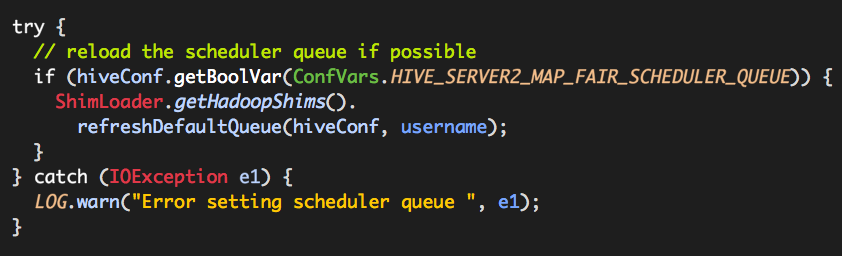
通过对源代码以及日志输出的各种“DEBUG”,最终找到了问题所在。大家都知道,HiveServer2有一个“Session”的概念,就是每一个用户有自己的一个会话(“set”的作用就是在用户自己的会话中设置特定的属性值),用户会话之间相互隔离。根据我们的猜测,我们找到了HiveServer2 Session的实现类:org.apache.hive.service.cli.session.HiveSessionImpl.HiveSessionImpl,它的初始化(构造函数)就是“魔法”发生的地方,关键片段如下:
而且ConfVars.HIVE_SERVER2_MAP_FAIR_SCHEDULER_QUEUE的值默认为true,如下:
上述代码片段默认情况下肯定会被执行,也就是说HiveSession的构建过程涉及到了Hadoop Scheduler的具体使用。
refreshDefaultQueue的作用就是在可用的情况下为特定用户根据公平调度策略选取队列,其中可用的情况:
(1)MapReduce2;
(2)用户名不为空值;
(3)使用公平调度策略;
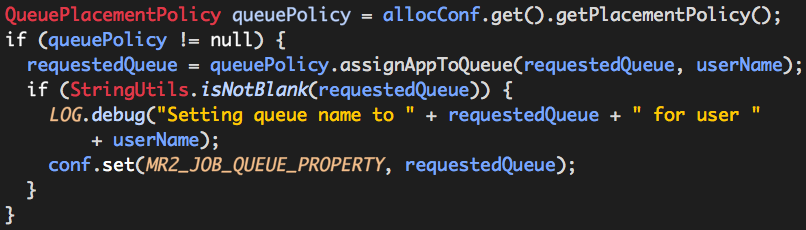
继续跟进代码,可以看到如下代码片段:
…...
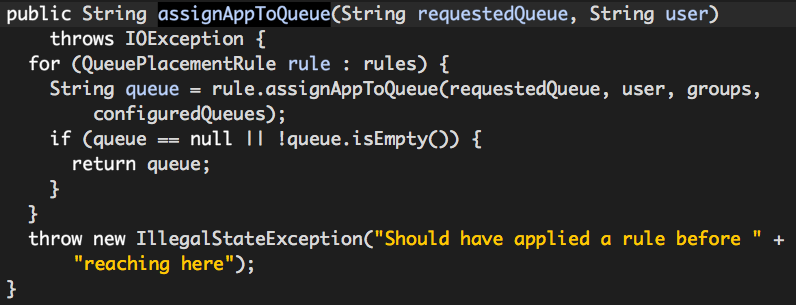
QueuePlacementPolicy assignAppToQueue的作用就是为用户分配队列的,其中YarnConfiguration.DEFAULT_QUEUE_NAME的值为default,MR2_JOB_QUEUE_PROPERTY的值为mapreduce.job.queuename,conf实际是HiveConf实例,我们在hive-site.xml或者mapred-site.xml中指定的mapreduce.job.queuename的值也就是在此处被覆盖的(注意:每一个用户会话中都保存着自己的conf)。
从上面的代码可以看出,最终是由某个QueuePlacementRule决定用户队列的,那么什么决定rules的呢?
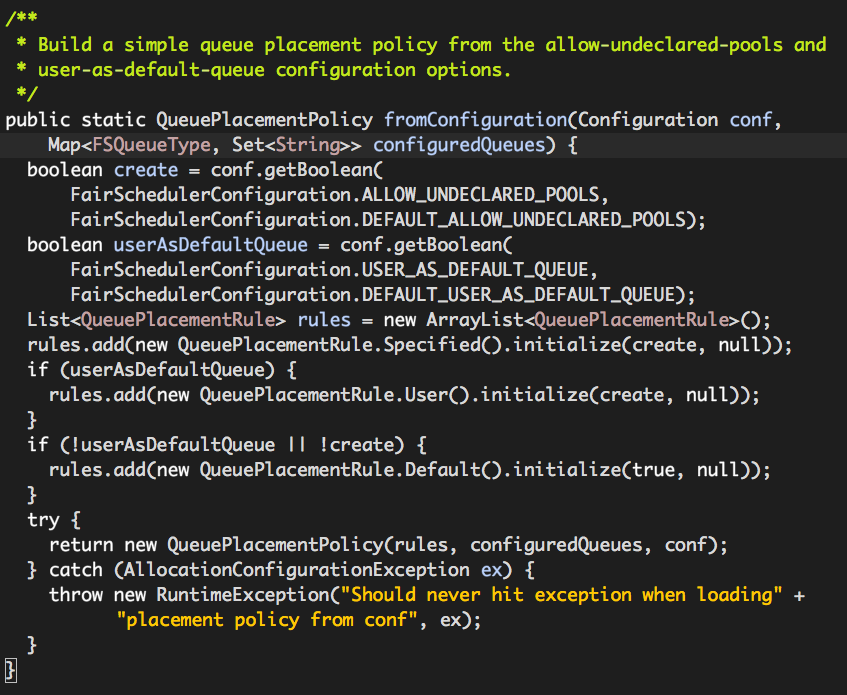
其中FairSchedulerConfiguration.USER_AS_DEFAULT_QUEUE的值为yarn.scheduler.fair.user-as-default-queue,FairSchedulerConfiguration.DEFAULT_USER_AS_DEFAULT_QUEUE的值为true,也就是说默认情况下rules包含两个QueuePlacementRule实例:
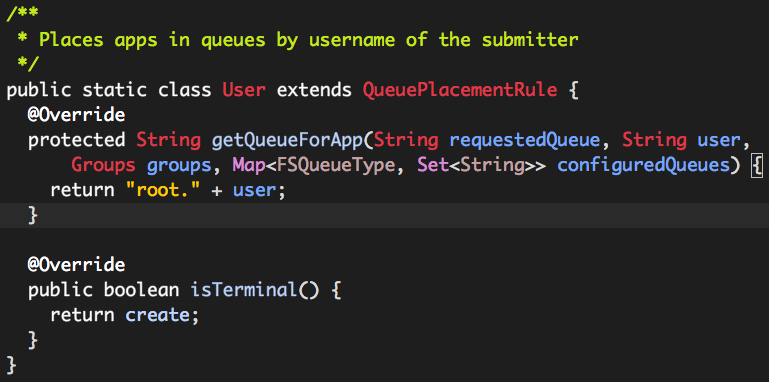
(1)org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.QueuePlacementRule.Specified
如前所述,requestedQueue值为“default”,因此该rule返回值为“”(空字符串),继续下一个rule的队列选取。
(2)org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.QueuePlacementRule.User
该rule队列的选取规则特别简单:root. + 用户名。
这也就是上述验证过程中出现队列“root.hdfs”的原因所在。
结论
综上所述,用户通过Beeline连接HiveServer2后的队列选取,默认情况下受公平调度策略的影响,如果想通过hive-site.xml或者mapred-site.xml中指定mapreduce.job.queuename,有一个非常简单的办法就是将属性值hive.server2.map.fair.scheduler.queue(ConfVars.HIVE_SERVER2_MAP_FAIR_SCHEDULER_QUEUE)置为false,可以在hive-site.xml中指定或或者启动HiveServer2时通过参数指定,这样HiveServer2队列的选取就不再受公平调度策略的影响。
- 【原创】大叔经验分享(38)beeline连接hiveserver2报错impersonate
beeline连接hiveserver2报错 Error: Could not open client transport with JDBC Uri: jdbc:hive2://localhost: ...
- hiveserver2启动成功但无法通过beeline连接
可能是配置的问题. 我将hive.metastore.uris从配置文件中注释掉之后解决了hiveserver2启动成功但无法通过beeline连接的问题. [root@node03 conf]# v ...
- beeline无密码连接hiveserver2
1.说明 #hiveserver2增加了权限控制,需要在hadoop的配置文件中配置 core-site.xml 增加以下内容: <property> <name>hadoop ...
- hive Beeline plus HiveServer2简单使用
HiveServer2是经常与beeline一起使用,可以用jdbc客户端远程连接,一般用于生产环境. 在提供传统客服端的功能之外,还提供其他功能: Beeline连接 1.先在hadoop集群启动H ...
- 用Java代码通过JDBC连接Hiveserver2
1.在终端启动hiveserver2#hiveserver2 2.使用beeline连接hive另外打开一个终端,输入如下命令(xavierdb必须是已经存在的数据库)#beeline -u jdbc ...
- beeline连接hive server遭遇MapRedTask (state=08S01,code=1)错误
采用beeline连接hive server是遭遇到如下错误: 5: jdbc:hive2://bluejoe0/default> select * from hive_triples wher ...
- sparkSQL元数据缓存不同步 beeline连接的表结构与hive不一致
之前遇到过的坑,通过beeline连接spark thirft server,当在Hive进行表结构修改,如replace/add/change columns后,表结构没有变化,还是旧的表结构,导致 ...
- 使用 beeline 连接 hive 数据库报错处理
一.beeline连接hive报错 1. User: root is not allowed to impersonate root (state=08S01,code=0) 在初次搭建完hadoop ...
- SQL Server 无法连接到服务器。SQL Server 复制需要有实际的服务器名称才能连接到服务器。请指定实际的服务器名称。
异常处理汇总-数据库系列 http://www.cnblogs.com/dunitian/p/4522990.html SQL性能优化汇总篇:http://www.cnblogs.com/dunit ...
随机推荐
- PHP安全编程:HTTP请求欺骗(转)
一个比欺骗表单更高级和复杂的攻击方式是HTTP请求欺骗.这给了攻击者完全的控制权与灵活性,它进一步证明了不能盲目信任用户提交的任何数据. 为了演示这是如何进行的,请看下面位于http://exampl ...
- Python之路,Day4 - Python基础4 (new版)
Python之路,Day4 - Python基础4 (new版) 本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发 ...
- codevs 1281 Xn数列 (矩阵乘法)
/* 再来个题练练手 scanf longlong 有bug....... */ #include<cstdio> #include<iostream> #include< ...
- ExtJs的事件机制Event(学员总结)
一.事件的三种绑定方式 1.HTML/DHTML 在标签中直接增加属性触发事件 [javascript] view plaincopy <script type="text/javas ...
- c#字符串驻留机制
http://www.cnblogs.com/instance/archive/2011/05/24/2056091.html
- RSA PKCS1padding 填充模式
在BouncyCastle实现RSA的PKCS1V1.5模式中,如果是公钥加密信息(forEncryption=true),密钥长度为1024位,那么输出的密文块长度为128个字节,输入的明文块长度为 ...
- 将对象保存至文件——CArchive
CArchive允许以一个二进制的形式保存一个对象的复杂网络,也可以再次装载它们,在内存中重新构造,这一过程叫作串行化/序列化(Serialization),简单的说,CArchive与CFile配合 ...
- [C++] 对象地址与接口指针的故事
刚想到一个问题,一直在思考C++中对象地址与接口指针的故事. 问题:多继承的情况下,一个具体类对象实现了多个接口,那么多该对象获取的不同接口指针是一样的吗?不是一样吗?不是对象地址吗?-- 困惑原因, ...
- Hibernate 事件监听
事件监听是JDK中常见的一种模式. Hibernate中的事件监听机制可以对Session对象的动作进行监听,一旦发生了特殊的事件,Hibernate就会调用监听器类中的事件处理方法.在某些功能的设计 ...
- 浅谈MIPS地址对齐问题
1.什么叫地址对齐? RISC 下使用访存指令读取或写入数据单元时,目标地址必须是所访问之数据单元字节数的整数倍,这个叫做地址对齐. 2.计算机主要的架构分哪两类?及其地址对齐在两者的区别? 计算机主 ...