[UFLDL] ConvNet

反卷积
深度网络结构是由多个单层网络叠加而成的,而常见的单层网络按照编码解码情况可以分为下面3类:
- 既有encoder部分也有decoder部分:比如常见的RBM系列(由RBM可构成的DBM, DBN等),autoencoder系列(以及由其扩展的sparse autoencoder, denoise autoencoder, contractive autoencoder, saturating autoencoder等)。
- 只包含decoder部分:比如sparse coding, 和今天要讲的deconvolution network.
- 只包含encoder部分,那就是普通的feed-forward network.
卷积:假设A=B*C 表示的是:B和C的卷积是A,也就是说已知B和C,求A这一过程叫做卷积;
反卷积:如果已知A和B求C或者已知A和C求B,则这个过程就叫做反卷积;【由feature map卷积feature filter,得到input image】
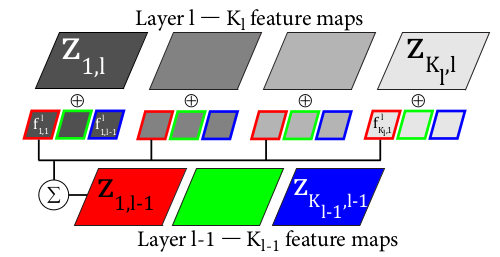
上图表示的是DN(deconvolution network的简称)的第一层,其输入图像是3通道的RGB图,学到的第一层特征有12个,说明每个输入通道图像都学习到了4个特征。而其中的特征图Z是由对应通道图像和特征分别卷积后再求和得到的。
One of the early papers on Deep Q-Learning for Atari games (Mnih et al, 2013) contains this description of its Convolutional Neural Network:
"The input to the neural network consists of an 84 × 84 × 4 image.
The first hidden layer convolves 16 8 × 8 filters with stride 4 with the input image and applies a rectifier nonlinearity.
The second hidden layer convolves 4 × 4 filters with stride 2, again followed by a rectifier nonlinearity.
The final hidden layer is fully-connected and consists of rectifier units.
The output layer is a fully-connected linear layer with a single output for each valid action.
The number of valid actions varied between 4 and 18 on the games we considered."
For each layer in this network, compute the number of weights per neuron in this layer (including bias)?
neurons in this layer?
connections into the neurons in this layer?
independent parameters in this layer?
You should assume there are 18 valid actions (outputs). First Convolutional Layer:
J = K = 84, L = 4, M = N = 8, P = 0, s = 4 weights per neuron: 1 + M × N × L = 1 + 8 × 8 × 4 =
width and height of layer: 1+(J-M)/s = 1+(84-8)/4 =
neurons in layer: 20 × 20 × 16 = 6400
connections: 20 × 20 × 16 × 257 = 1644800
independent parameters: × 257 = 4112
Second Convolutional Layer:
J = K = 20, L = 16, M = N = 4, P = 0, s = 2 weights per neuron: 1 + M × N × L = 1 + 4 × 4 × 16 = 257
width and height of layer: 1+(J-M)/s = 1+(20-4)/2 = 9
neurons in layer: 9 × 9 × 32 = 2592
connections: 9 × 9 × 32 × 257 = 666144
independent parameters: 32 × 257 = 8224
Fully Connected Layer: weights per neuron: 1 + 2592 = 2593
neurons in layer: 256
connections: 256 × 2593 = 663808
independent parameters: 663808
Output Layer: weights per neuron: 1 + 256 = 257
neurons in layer: 18
connections: 18 × 257 = 4626
independent parameters: 4626
链接:https://www.zhihu.com/question/43609045/answer/132235276 [1] Zeiler M D, Krishnan D, Taylor G W, etal. Deconvolutional networks[C]. Computer Vision and Pattern Recognition, 2010.
[2] Zeiler M D, Taylor G W, Fergus R, etal. Adaptive deconvolutional networks for mid and high level featurelearning[C]. International Conference on Computer Vision, 2011.
[3] Zeiler M D, Fergus R. Visualizing andUnderstanding Convolutional Networks[C]. European Conference on ComputerVision, 2013.
[4] Long J, Shelhamer E, Darrell T, et al.Fully convolutional networks for semantic segmentation[C]. Computer Vision andPattern Recognition, 2015.
[5] Unsupervised Representation Learningwith Deep Convolutional Generative Adversarial Networks
[6] Sparse Coding - Ufldl
[7] Denoising Autoencoders (dA)
[8] Convolution arithmetic tutorial
Reference
逆卷积【就是反卷积】的一个很有趣的应用是GAN(Generative Adversarial Network)里用来生成图片:Generative Models
Deconvolution大致可以分为以下几个方面:
- unsupervised learning,其实就是covolutional sparse coding 卷积稀疏编码[1][2]:这里的deconv只是观念上和传统的conv反向,传统的conv是从图片生成feature map,而deconv是用unsupervised的方法找到一组kernel和feature map,让它们重建图片。
- CNN可视化[3]:通过deconv将CNN中conv得到的feature map还原到像素空间,以观察特定的feature map对哪些pattern的图片敏感,这里的deconv其实不是conv的可逆运算,只是conv的transpose,所以tensorflow里一般取名叫transpose_conv。
- upsampling[4][5]:在pixel-wise prediction比如image segmentation[4]以及image generation[5]中,由于需要做原始图片尺寸空间的预测,而卷积由于stride往往会降低图片size, 所以往往需要通过upsampling的方法来还原到原始图片尺寸,deconv就充当了一个upsampling的角色。
链接:https://www.zhihu.com/question/43609045/answer/132235276
[1. covolutional sparse coding]
第一篇文章 Deconvolutional Networks[1] 主要用于学习图片的中低层级的特征表示,
属于unsupervised feature learning,和传统的auto-encoder,RBM比较类似,和它最像的还是sparse coding,
Ref: [UFLDL] Sparse Representation
Sparse coding一个不足就是runtime cost比较高。
- learning阶段需要学习a和phi
- inference阶段还是需要学习a
接下来开始介绍Deconvolutional Network,和sparse coding的思路比较类似,
是学输入图片y的latent feature map z,同时也要学卷积核f。
如果非要用sparse coding那套来类比解释的话,就是学习图片在basis空间f的系数表示z。
只是操作由点乘变成了卷积,如下图所示,
<img src="https://pic3.zhimg.com/50/v2-adc1f9adffa771ed176ba808c0d94f22_hd.png" data-rawwidth="256" data-rawheight="102" class="content_image" width="256">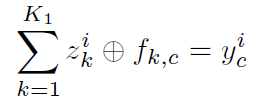
c 是图片的feature map(color channel)数量;
k 是feature map数量;
z 是feature map,【a,系数】
f 是卷积核,【phi,基】
y 是输入图片。
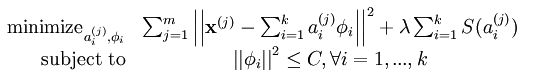
Loss function是:
<img src="https://pic3.zhimg.com/50/v2-5279c7bdd068c2fc29ce2826f938768e_hd.png" data-rawwidth="651" data-rawheight="113" class="origin_image zh-lightbox-thumb" width="651" data-original="https://pic3.zhimg.com/v2-5279c7bdd068c2fc29ce2826f938768e_r.png">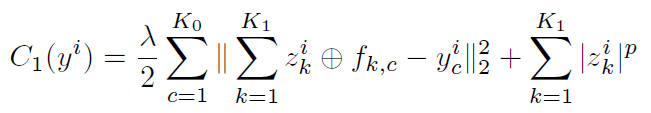
上述结构只是单层的deconvolutional layer,可以继续按照这个方法叠加layer,第一层的z就作为第二层的图片输入。Loss function如式3:
<img src="https://pic1.zhimg.com/50/v2-1ff9c78e02ea86137f0910bc45b129e4_hd.png" data-rawwidth="749" data-rawheight="215" class="origin_image zh-lightbox-thumb" width="749" data-original="https://pic1.zhimg.com/v2-1ff9c78e02ea86137f0910bc45b129e4_r.png">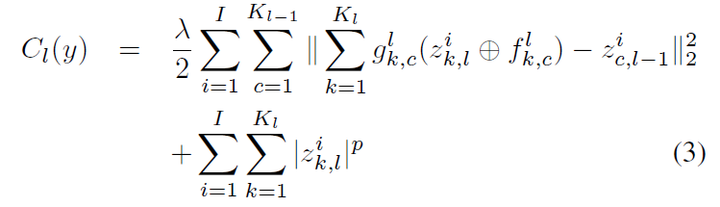
其中
<img src="https://pic3.zhimg.com/50/v2-242a3703ae5c72cf7d996f997b5ff73a_hd.png" data-rawwidth="81" data-rawheight="44" class="content_image" width="81">就是上一层的feature map表示,作为当前层的输入,
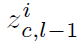 就是上一层的feature map表示,作为当前层的输入,
就是上一层的feature map表示,作为当前层的输入,
<img src="https://pic2.zhimg.com/50/v2-f4aadc2f410aedd660934b82c305fe55_hd.png" data-rawwidth="61" data-rawheight="46" class="content_image" width="61">是一个0-1矩阵,相当于一个mask,用来决定哪些位置的输入需要连接,有点denoising auto-encoder的味道,附上denoising auto-encoder的关于denoising的解释[7]:
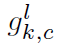 是一个0-1矩阵,相当于一个mask,用来决定哪些位置的输入需要连接,
是一个0-1矩阵,相当于一个mask,用来决定哪些位置的输入需要连接,
有点denoising auto-encoder的味道,附上denoising auto-encoder的关于denoising的解释[7]:
<img src="https://pic3.zhimg.com/50/v2-ec7c82357b96a27dd977d6cd9e84f636_hd.png" data-rawwidth="608" data-rawheight="126" class="origin_image zh-lightbox-thumb" width="608" data-original="https://pic3.zhimg.com/v2-ec7c82357b96a27dd977d6cd9e84f636_r.png">上图说明基于一部分变量去预测另一部分变量的能力是学习变量的联合分布的关键,这也是Gibbs sampling能work的原因。
(1) learning
Deconcolutional Network的学习也是alterlative交替优化,
- 先优化 feature map z
- 再优化 filter f
如果有多层的话也是逐层训练。
首先第一步是学习feature map。
学习Deconcolutional Network的loss function有些困难,原因是feature map中的不同位置的点因为filter互相耦合比较严重。
作者尝试了GD,SGD,IRLS(Iterative Reweighted Least Squares)这些优化方法,效果都不理想。
因此作者使用了另外一个优化方法,不是直接优化式3中的z,而是选择了一个代理变量x,让z接近x,同时正则化x达到和式3中loss function同样的效果:
<img src="https://pic4.zhimg.com/50/v2-d1aebb4137df5c50b59f9b8e8b04da3f_hd.png" data-rawwidth="465" data-rawheight="140" class="origin_image zh-lightbox-thumb" width="465" data-original="https://pic4.zhimg.com/v2-d1aebb4137df5c50b59f9b8e8b04da3f_r.png">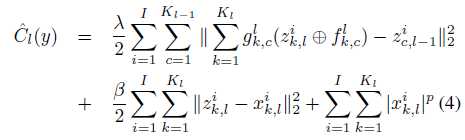
优化上式也是采用交替优化z和x的方法。
第二步是学习filter,正常的梯度下降即可。
整个Deconvolutional Network的学习算法如下图所示,其中红色框是学习feature map,其实也相当于做inference,蓝色框是学习filter,相当于模型本身的参数学习。
<img src="https://pic4.zhimg.com/50/v2-9c463735185823db0504b169b014969b_hd.png" data-rawwidth="481" data-rawheight="404" class="origin_image zh-lightbox-thumb" width="481" data-original="https://pic4.zhimg.com/v2-9c463735185823db0504b169b014969b_r.png">
(2) inference
Inference包括两个层面:
第一,根据输入图片和学到的filter 从而 inference latent feature map,
第二,根据latent feature map reconstruct图片。
以两层Deconcolutional Network为例,首先学习第一层z1,然后学习第二层的z2,注意第二层的学习有两个loss,
- 一个是重建z1的loss,即project 1次学习和z1的误差
<img src="https://pic3.zhimg.com/50/v2-fa38e163127a5387f4a3941482e9f876_hd.png" data-rawwidth="406" data-rawheight="73" class="content_image" width="406"> 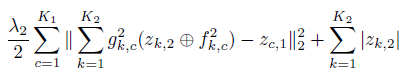
- 一个是继续重建原图片的loss,即project两次学习和原始图片y的误差
<img src="https://pic1.zhimg.com/50/v2-702ec3493d3d1d7b87291b8aa99ef32c_hd.png" data-rawwidth="498" data-rawheight="77" class="origin_image zh-lightbox-thumb" width="498" data-original="https://pic1.zhimg.com/v2-702ec3493d3d1d7b87291b8aa99ef32c_r.png">  <img src="https://pic1.zhimg.com/50/v2-e4ac05f5f594f8733feb3e49d21cd038_hd.png" data-rawwidth="344" data-rawheight="74" class="content_image" width="344">
<img src="https://pic1.zhimg.com/50/v2-e4ac05f5f594f8733feb3e49d21cd038_hd.png" data-rawwidth="344" data-rawheight="74" class="content_image" width="344">
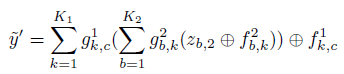
下图是Deconcolutional Network学习到的filter示例,可以看到通过unsupervised的方法一样能学到线条以及线条组合等中低层特征,具体分析可见论文。
<img src="https://pic1.zhimg.com/50/v2-eed4e7134658a5d729e5bd39d36f9020_hd.png" data-rawwidth="468" data-rawheight="733" class="origin_image zh-lightbox-thumb" width="468" data-original="https://pic1.zhimg.com/v2-eed4e7134658a5d729e5bd39d36f9020_r.png">
第二篇文章 Adaptive Deconvolutional Networks for Mid and High Level Feature Learning[2]也是通过deconvolutional network学习图片的特征表示,
和上一篇不同的是加入了pooling,unpooling , deconv (transpose conv,deconv的参数只是原卷积的转置,并不原卷积的可逆运算)。
这篇文章才是可视化常用的反卷积,上篇文章的deconv只是说conv的方向从feature map到图片,也还是feedforward的概念,不是这篇里用的conv和transpose conv。
这篇文章就是要学习图片的所有层级的特征,还是用unsupervised的方法。以往的其它方法在逐层学习的时候图片原始像素丢掉了,学习的target只是上一层的feature map,所以高层的filter和输入图片的连接就没那么强了,导致学得不好,所以它要end to end的学习,学习都是以原始像素作为target学习。
网络结构还是一样有deconvolution。
<img src="https://pic4.zhimg.com/50/v2-74efc1136729ec4025c1f0b77c42b143_hd.png" data-rawwidth="180" data-rawheight="71" class="content_image" width="180">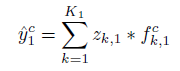
然后引入了pooling,采用的是3D pooling,both in a 2D map and between maps,
然后记录max pooling value and switch idx,也就是pooling的receptive field中最大值的位置。
unpooling的时候最大值的位置还原,其它位置填0,如下图所示:
<img src="https://pic2.zhimg.com/50/v2-f39e054f42aa96a7daf2b783fd0e3529_hd.png" data-rawwidth="461" data-rawheight="250" class="origin_image zh-lightbox-thumb" width="461" data-original="https://pic2.zhimg.com/v2-f39e054f42aa96a7daf2b783fd0e3529_r.png">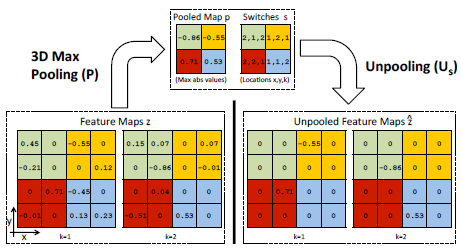
整个网络结构(两层)如下图所示:
<img src="https://pic1.zhimg.com/50/v2-29418ed101812ee96f08a8347949b848_hd.png" data-rawwidth="341" data-rawheight="614" class="content_image" width="341">
首先看右边的卷积通道:y--conv1--z1--pool1--p1--conv2--z2--pool2--p2
然后是左边的反卷积通道:p2--unpool2--z2--devonv2--p1--unpool2--z1--deconv1--y^
同一层中的conv与deconv的参数是转置关系,整个conv通道用
<img src="https://pic4.zhimg.com/50/v2-eadf811cd1e8f76815981c23333985bf_hd.png" data-rawwidth="74" data-rawheight="60" class="content_image" width="74">表示,deconv通道用
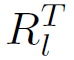 表示,deconv通道用
表示,deconv通道用
<img src="https://pic1.zhimg.com/50/v2-015a6e2ec75e70dab8e27c27c19a9358_hd.png" data-rawwidth="71" data-rawheight="62" class="content_image" width="71">表示,下标l代表deconv网络的层数,conv通道的组成为:
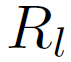 表示,下标l代表deconv网络的层数,conv通道的组成为:
表示,下标l代表deconv网络的层数,conv通道的组成为:
<img src="https://pic2.zhimg.com/50/v2-a0c607fd87df5314776f1a75090caa9d_hd.png" data-rawwidth="471" data-rawheight="65" class="origin_image zh-lightbox-thumb" width="471" data-original="https://pic2.zhimg.com/v2-a0c607fd87df5314776f1a75090caa9d_r.png">
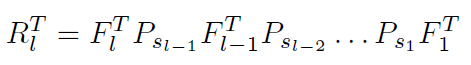
网络的学习也是分两个步骤,先固定filter学习feature map (inference),然后固定feature map学习filter (learning),和上一篇文章一样,学习没什么难的,大致步骤如下图,具体可以参见paper细节,
图片中的红框代表inference,蓝框代表learning。
<img src="https://pic1.zhimg.com/50/v2-e8795dc4e8537f5d02658ca7ece69b1c_hd.png" data-rawwidth="464" data-rawheight="492" class="origin_image zh-lightbox-thumb" width="464" data-original="https://pic1.zhimg.com/v2-e8795dc4e8537f5d02658ca7ece69b1c_r.png">
最后将提出来的feature用于图片识别分类,使用中间层的feature map作为SPM (Spatial Pyramid Matching) 的输入,M个feature map的reconstruction average 起来,得到一个SPM的single pyramid,
最后SPM分类器的效果能达到comparable的效果。
deconv第二个方面是用来做CNN的可视化。
分别简单介绍两篇文章,FCN和DCAN。FCN[4]主要用来做pixel-wise的image segmentation预测,先用传统的CNN结构得到feature map,同时将传统的full connected转换成了对应参数的卷积层,比如传统pool5层的尺寸是7×7×512,fc6的尺寸是4096,传统的full connected weight是7×7×512×4096这样多的参数,将它转成卷积核,kernel size为7×7,input channel为512,output channel为4096,则将传统的分别带有卷积和全连接的网络转成了全卷积网络(fully convolutional network, FCN)。FCN的一个好处是输入图片尺寸大小可以任意,不受传统网络全连接层尺寸限制,传统的方法还要用类似SPP结构来避免这个问题。FCN中为了得到pixel-wise的prediction,也要把feature map通过deconv转化到像素空间。论文中还有一些具体的feature融合,详情可参见论文。
DCGAN[5]中使用deconv就更自然了,本身GAN就需要generative model,需要通过deconv从特定分布的输入数据中生成图片。GAN这种模式被Yann LeCun特别看好,认为是unsupervised learning的一个未来。
[UFLDL] ConvNet的更多相关文章
- 本人AI知识体系导航 - AI menu
Relevant Readable Links Name Interesting topic Comment Edwin Chen 非参贝叶斯 徐亦达老板 Dirichlet Process 学习 ...
- [Paper] **Before GAN: sparse coding
读罢[UFLDL] ConvNet,为了知识体系的完整,看来需要实战几篇论文深入理解一些原理. 如下是未来博文系列的初步设想,为了hold住 GAN而必备的知识体系,也是必经之路. [Paper] B ...
- Deep Learning 19_深度学习UFLDL教程:Convolutional Neural Network_Exercise(斯坦福大学深度学习教程)
理论知识:Optimization: Stochastic Gradient Descent和Convolutional Neural Network CNN卷积神经网络推导和实现.Deep lear ...
- 深度学习入门教程UFLDL学习实验笔记三:主成分分析PCA与白化whitening
主成分分析与白化是在做深度学习训练时最常见的两种预处理的方法,主成分分析是一种我们用的很多的降维的一种手段,通过PCA降维,我们能够有效的降低数据的维度,加快运算速度.而白化就是为了使得每个特征能有同 ...
- Deep Learning 13_深度学习UFLDL教程:Independent Component Analysis_Exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:三十三(ICA模型).Deep learning:三十九(ICA模型练习) 实验环境:win7, matlab2015b,16G内存,2T机 ...
- Deep Learning 12_深度学习UFLDL教程:Sparse Coding_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程.Deep learning:二十六(Sparse coding简单理解).Deep learning:二十七(Sparse coding中关于矩阵的范数求导).Deep ...
- Deep Learning 11_深度学习UFLDL教程:数据预处理(斯坦福大学深度学习教程)
理论知识:UFLDL数据预处理和http://www.cnblogs.com/tornadomeet/archive/2013/04/20/3033149.html 数据预处理是深度学习中非常重要的一 ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
- Deep Learning 9_深度学习UFLDL教程:linear decoder_exercise(斯坦福大学深度学习教程)
前言 实验内容:Exercise:Learning color features with Sparse Autoencoders.即:利用线性解码器,从100000张8*8的RGB图像块中提取颜色特 ...
随机推荐
- [ Visual Studio ] MSDN
在 Visual Studio 中创建自定义项目和项模板 编写和重构代码 (C++) C# 指南 C#最新版本 使用 MSBuild 如何:管理编辑器模式,进入全屏模式编写代码 自定义代码折叠
- 前端AngularJS后端ASP.NET Web API上传文件
本篇体验使用AngularJS向后端ASP.NET API控制器上传文件. 首先服务端: public class FilesController : ApiController { //usi ...
- iOS:百度长语音识别具体的封装:识别、播放、进度刷新
一.介绍 以前做过讯飞语音识别,比较简单,识别率很不错,但是它的识别时间是有限制的,最多60秒.可是有的时候我们需要更长的识别时间,例如朗诵古诗等功能.当然讯飞语音也是可以通过曲线救国来实现,就是每达 ...
- C++ 并发编程,std::unique_lock与std::lock_guard区别示例
背景 平时看代码时,也会使用到std::lock_guard,但是std::unique_lock用的比较少.在看并发编程,这里总结一下.方便后续使用. std::unique_lock也可以提供自动 ...
- eclipse-修改启动JDK版本
打开eclipse安装目录下的eclipse.ini文件,将红色内容加入 -vm ../Java/jdk1.6.0_26/bin (或者指向具体目录:D:/software/jdk_1.8u91/bi ...
- DNS缓存中毒是怎么回事?
近来,网络上出现互联网漏洞——DNS缓存漏洞,此漏洞直指我们应用中互联网脆弱的安全系统,而安全性差的根源在于设计缺陷.利用该漏洞轻则可以让用户无法打开网页,重则是网络钓鱼和金融诈骗,给受害者造成巨大损 ...
- akka actors默认邮箱介绍
1. UnboundedMailbox is the default unbounded MailboxType used by Akka Actors ”无界邮箱“ 是akka actors默认使用 ...
- vmware vSphere 5.5的14个新功能
摘录自:http://www.networkworld.com/slideshow/117304/12-terrific-new-updates-in-vmware-vsphere-55.html#s ...
- 视觉SLAM中的数学基础 第三篇 李群与李代数
视觉SLAM中的数学基础 第三篇 李群与李代数 前言 在SLAM中,除了表达3D旋转与位移之外,我们还要对它们进行估计,因为SLAM整个过程就是在不断地估计机器人的位姿与地图.为了做这件事,需要对变换 ...
- mysql 编译安装 window篇
传送门 # mysql下载地址 https://www.mysql.com/downloads/ # 找到MySQL Community Edition (GPL) https://dev.mysql ...