day21-22Redis Mahout
PS: Redis 在博客的 JavaEE PS:大数据实时执行3个特性,Storm,kafka,Redis
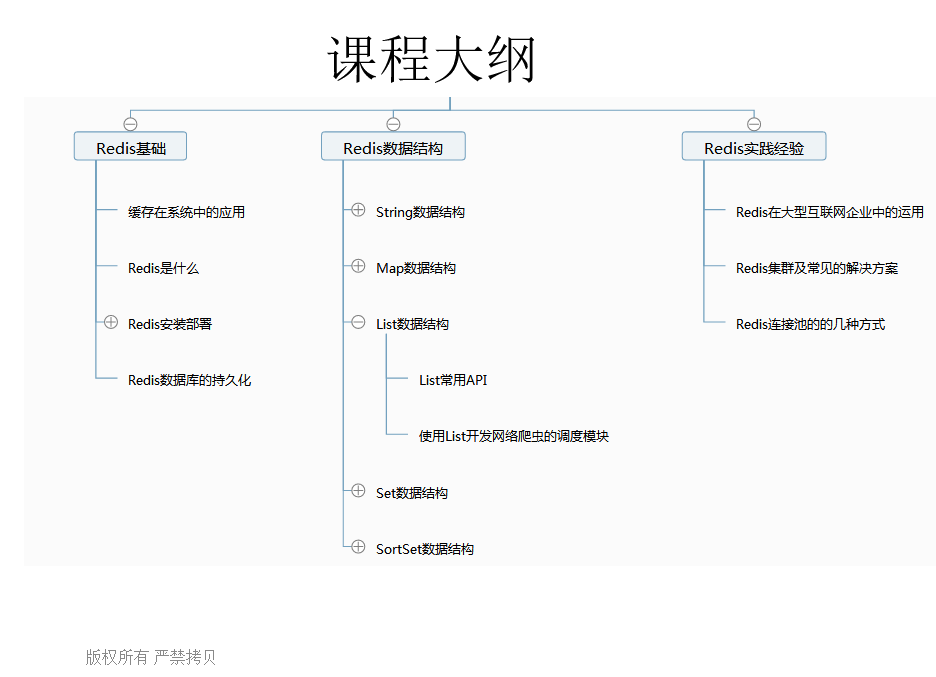
PS:比如在系统中,1s中有大量的请求涌入的系统中,那么请求就存入数据库就挂了,这就需要到了Redis缓存了。


day22 ------------------------
PS: 主要讲诉了日志采集系统,后台又代码,可以参看 flume +kafka+ storm +redis



package mahout; import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.similarity.ItemSimilarity;
import org.apache.mahout.cf.taste.similarity.precompute.example.GroupLensDataModel; import java.io.File;
import java.util.List; /**
* Describe:
* 与基于用户的技术不同的是,这种方法比较的是内容项与内容项之间的相似度。
* Item-based 方法同样需要进行三个步骤获得推荐:
* 1)得到内容项(Item)的历史评分数据;
* 2)针对内容项进行内容项之间的相似度计算,找到目标内容项的“最近邻居”;
* 3)产生推荐。这里内容项之间的相似度是通过比较两个内容项上的用户行为选择矢量得到的。
* 第二代协同过滤算法
* Author: maoxiangyi
* Domain: www.itcast.cn
* Data: 2015/11/26.
*/
public class BaseItemRecommender { public static void main(String[] args) throws Exception {
//准备数据 这里是电影评分数据
File file = new File("E:\\itcast\\项目中心\\大数据课程研发\\大数据课程-参考资料\\推荐系统\\数据\\ml-10m\\ml-10M100K\\ratings.dat");
//将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的
DataModel dataModel = new GroupLensDataModel(file);
//计算相似度,相似度算法有很多种,欧几里得、皮尔逊等等。
ItemSimilarity itemSimilarity = new PearsonCorrelationSimilarity(dataModel);
//构建推荐器,协同过滤推荐有两种,分别是基于用户的和基于物品的,这里使用基于物品的协同过滤推荐
GenericItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, itemSimilarity);
//给用户ID等于5的用户推荐10个与2398相似的商品
List<RecommendedItem> recommendedItemList = recommender.recommendedBecause(5, 2398, 10);
//打印推荐的结果
System.out.println("使用基于物品的协同过滤算法");
System.out.println("根据用户5当前浏览的商品2398,推荐10个相似的商品");
for (RecommendedItem recommendedItem : recommendedItemList) {
System.out.println(recommendedItem);
}
long start = System.currentTimeMillis();
recommendedItemList = recommender.recommendedBecause(5, 34, 10);
//打印推荐的结果
System.out.println("使用基于物品的协同过滤算法");
System.out.println("根据用户5当前浏览的商品2398,推荐10个相似的商品");
for (RecommendedItem recommendedItem : recommendedItemList) {
System.out.println(recommendedItem);
}
System.out.println(System.currentTimeMillis() -start);
}
}
day21-22Redis Mahout的更多相关文章
- [Mahout] 完整部署过程
概述 Mahout底层依赖Hadoop,部署Mahout过程中最困难的就是Hadoop的部署 本文假设用户本身没有进行Hadoop的部署,记述部署Mahout的过程 ...
- Mahout之数据承载
转载自:https://www.douban.com/note/204399134/ 推荐数据的处理是大规模的,在集群环境下一次要处理的数据可能是数GB,所以Mahout针对推荐数据进行了优化. Pr ...
- Mahout推荐算法API详解
转载自:http://blog.fens.me/mahout-recommendation-api/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 从源代码剖析Mahout推荐引擎
转载自:http://blog.fens.me/mahout-recommend-engine/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pi ...
- mahout 安装测试
1 下载 在http://archive.apache.org/dist/mahout下载相应版本的mahout 版本,获取官网查看http://mahout.apache.org 相关的信息
- Hadoop里的数据挖掘应用-Mahout——学习笔记<三>
之前有幸在MOOC学院抽中小象学院hadoop体验课. 这是小象学院hadoop2.X的笔记 由于平时对数据挖掘做的比较多,所以优先看Mahout方向视频. Mahout有很好的扩展性与容错性(基于H ...
- 初学Mahout测试kmeans算法
预备工作: 启动hadoop集群 准备数据 Synthetic_control.data数据集下载地址http://archive.ics.uci.edu/ml/databases/synthetic ...
- Mahout安装与配置
一.安装mahout 1.下载mahout(mahout-distribution-0.9.tar.gz) http://pan.baidu.com/s/1kUtOMQb 2.解压至指定目录 我平时都 ...
- Mahout 的安装
Mahout 的安装 Mahout是Hadoop的一种高级应用.运行Mahout需要提前安装好Hadoop,Mahout只在Hadoop集群的NameNode节点上安装一个即可,其他数据节点上不需要安 ...
- Mahout源码分析之 -- 文档向量化TF-IDF
fesh个人实践,欢迎经验交流!Blog地址:http://www.cnblogs.com/fesh/p/3775429.html Mahout之SparseVectorsFromSequenceFi ...
随机推荐
- 【资料收集】PCA降维
重点整理: PCA(Principal Components Analysis)即主成分分析,是图像处理中经常用到的降维方法 1.原始数据: 假定数据是二维的 x=[2.5, 0.5, 2.2, 1. ...
- URL组成成分及各部分作用简介及urllib.parse / uri
URL的一般格式为(带方括号[]的为可选项): protocol :// hostname[:port] / path / [;parameters][?query]#fragment urllib. ...
- VSTO:使用C#开发Excel、Word【10】
第二部分:.NET中的Office编程本书前两章介绍了Office对象模型和Office PIA. 您还看到如何使用Visual Studio使用VSTO的功能构建文档中的控制台应用程序,加载项和代码 ...
- 4.2 C++虚成员函数
参考:http://www.weixueyuan.net/view/6371.html 总结: virtual关键字仅用于函数声明,如果函数是在类外定义,则不需要再加上virtual关键字了. 在C+ ...
- Comparable和Comparator接口是干什么的?列出它们的区别。
Comparable和Comparator接口是干什么的?列出它们的区别. Java提供了只包含一个compareTo()方法的Comparable接口.这个方法可以个给两个对象排序.具体来说,它返回 ...
- jdk,jre和jvm
JDK(Java Development Kit)是针对Java开发员的产品,是整个Java的核心,包括了Java运行环境JRE.Java工具和Java基础类库 JRE是Java Runtime En ...
- elk之logstash
环境: centos7 jdk8 1.创建Logstash源 rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch touch ...
- java.util.concurrent ThreadPoolExecutor源码分析
实现的接口:Executor, ExecutorService 子类:ScheduledThreadPoolExecutor 这类为java线程池的管理和创建,其中封装好的线程池模型在Executor ...
- <zk的典型应用场景>
Overview zk是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员可以使用它来进行分布式数据的发布与订阅. 另一方面,通过对zk中丰富的数据节点进行交叉使用,配合watcher事件通 ...
- [从Paxos到ZooKeeper][分布式一致性原理与实践]<二>一致性协议[Paxos算法]
Overview 在<一>有介绍到,一个分布式系统的架构设计,往往会在系统的可用性和数据一致性之间进行反复的权衡,于是产生了一系列的一致性协议. 为解决分布式一致性问题,在长期的探索过程中 ...