[转]Core Kubernetes: Jazz Improv over Orchestration
(因为写的真的是太好了,所以必须要转载)
This is the first in a series of blog posts that details some of the inner workings of Kubernetes. If you are simply an operator or user of Kubernetes you don’t necessarily need to understand these details. But if you prefer depth-first learning and really want to understand the details of how things work, this is for you.
This article assumes a working knowledge of Kubernetes. I’m not going to define what Kubernetes is or the core components (e.g. Pod, Node, Kubelet).
In this article we talk about the core moving parts and how they work with each other to make things happen. The general class of systems like Kubernetes is commonly called container orchestration. But orchestration implies there is a central conductor with an up front plan. However, this isn’t really a great description of Kubernetes. Instead, Kubernetes is more like jazz improv. There is a set of actors that are playing off of each other to coordinate and react.
We’ll start by going over the core components and what they do. Then we’ll look at a typical flow that schedules and runs a Pod.
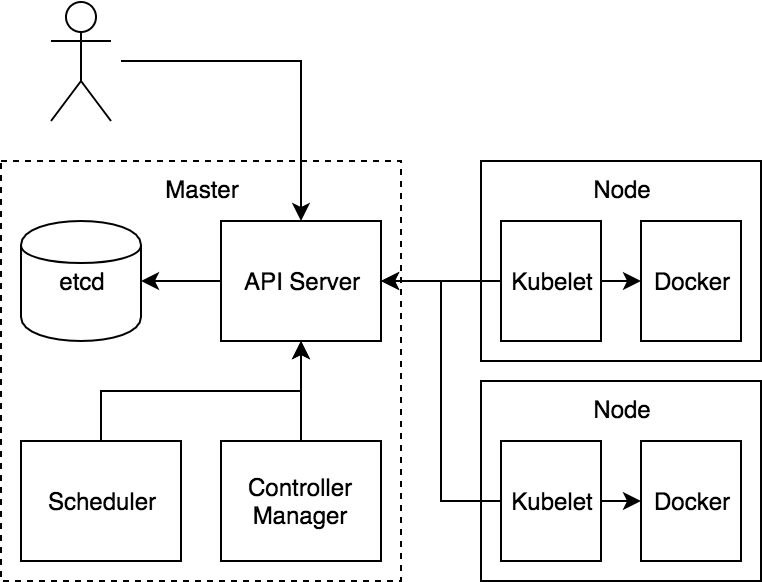
Datastore: etcd
etcd is the core state store for Kubernetes. While there are important in-memory caches throughout the system, etcd is considered the system of record.
Quick summary of etcd: etcd is a clustered database that prizes consistency above partition tolerance. Systems of this class (ZooKeeper, parts of Consul) are patterned after a system developed at Google called chubby. These systems are often called “lock servers” as they can be used to coordinate locking in a distributed systems. Personally, I find that name a bit confusing. The data model for etcd (and chubby) is a simple hierarchy of keys that store simple unstructured values. It actually looks a lot like a file system. Interestingly, at Google, chubby is most frequently accessed using an abstracted File interface that works across local files, object stores, etc. The highly consistent nature, however, provides for strict ordering of writes and allows clients to do atomic updates of a set of values.
Managing state reliably is one of the more difficult things to do in any system. In a distributed system it is even more difficult as it brings in many subtle algorithms like raft or paxos. By using etcd, Kubernetes itself can concentrate on other parts of the system.
The idea of watch in etcd (and similar systems) is critical for how Kubernetes works. These systems allow clients to perform a lightweight subscription for changes to parts of the key namespace. Clients get notified immediately when something they are watching changes. This can be used as a coordination mechanism between components of the distributed system. One component can write to etcd and other componenents can immediately react to that change.
One way to think of this is as an inversion of the common pubsub mechanisms. In many queue systems, the topics store no real user data but the messages that are published to those topics contain rich data. For systems like etcd the keys (analogous to topics) store the real data while the messages (notifications of changes) contain no unique rich information. In other words, for queues the topics are simple and the messages rich while systems like etcd are the opposite.
The common pattern is for clients to mirror a subset of the database in memory and then react to changes of that database. Watches are used as an efficient mechanism to keep that cache up to date. If the watch fails for some reason, the client can fall back to polling at the cost of increased load, network traffic and latency.
Policy Layer: API Server
The heart of Kubernetes is a component that is, creatively, called the API Server. This is the only component in the system that talks to etcd. In fact, etcd is really an implementation detail of the API Server and it is theoretically possible to back Kubernetes with some other storage system.
The API Server is a policy component that provides filtered access to etcd. Its responsibilities are relatively generic in nature and it is currently being broken out so that it can be used as a control plane nexus for other types of systems.
The main currency of the API Server is a resource. These are exposed via a simple REST API. There is a standard structure to most of these resources that enables some expanded features. The nature and reasoning for that API structure is left as a topic for a future post. Regardless, the API Server allows various components to create, read, write, update and watch for changes of resources.
Let’s detail the responsibilities of the API Server:
- Authentication and authorization. Kubernetes has a pluggable auth system. There are some built in mechanisms for both authentication users and authorizing those users to access resources. In addition there are methods to call out to external services (potentially self-hosted on Kubernetes) to provide these services. This type of extensiblity is core to how Kubernetes is built.
- Next, the API Server runs a set of admission controllers that can reject or modify requests. These allow policy to be applied and default values to be set. This is a critical place for making sure that the data entering the system is valid while the API Server client is still waiting for request confirmation. While these admission controllers are currently compiled in to the API Server, there is ongoing work to make this be another extensibility mechanism.
- The API server helps with API versioning. A critical problem when versioning APIs is to allow for the representation of the resources to evolve. Fields will be added, deprecated, re-organized and in other ways transformed. The API Server stores a “true” representation of a resource in etcd and converts/renders that resource depending on the version of the API being satisfied. Planning for versioning and the evolution of APIs has been a key effort for Kubernetes since early in the project. This is part of what allows Kubernetes to offer a decent deprecation policy relatively early in its lifecycle.
A critical feature of the API Server is that it also supports the idea of watch. This means that clients of the API Server can employ the same coordination patterns as with etcd. Most coordination in Kubernetes consists of a component writing to an API Server resource that another component is watching. The second component will then react to changes almost immediately.
Business Logic: Controller Manager and Scheduler
The last piece of the puzzle is the code that actually makes the thing work! These are the components that coordinate through the API Server. These are bundled into separate servers called the Controller Manager and the Scheduler. The choice to break these out was so they couldn’t “cheat”. If the core parts of the system had to talk to the API Server like every other component it would help ensure that we were building an extensible system from the start. The fact that there are just two of these is an accident of history. They could conceivably be combined into one big binary or broken out into a dozen+ separate servers.
The components here do all sorts of things to make the system work. The scheduler, specifically, (a) looks for Pods that aren’t assigned to a node (unbound Pods), (b) examines the state of the cluster (cached in memory), (c) picks a node that has free space and meets other constraints, and (d) binds that Pod to a node.
Similarly, there is code (“controller”) in the Controller Manager to implement the behavior of a ReplicaSet. (As a reminder, the ReplicaSet ensures that there are a set number of replicas of a Pod Template running at any one time) This controller will watch both the ReplicaSet resource and a set of Pods based on the selector in that resource. It then takes action to create/destroy Pods in order to maintain a stable set of Pods as described in the ReplicaSet. Most controllers follow this type of pattern.
Node Agent: Kubelet
Finally, there is the agent that sits on the node. This also authenticates to the API Server like any other component. It is responsible for watching the set of Pods that are bound to its node and making sure those Pods are running. It then reports back status as things change with respect to those Pods.
A Typical Flow
To help understand how this works, let’s work through an example of how things get done in Kubernetes.
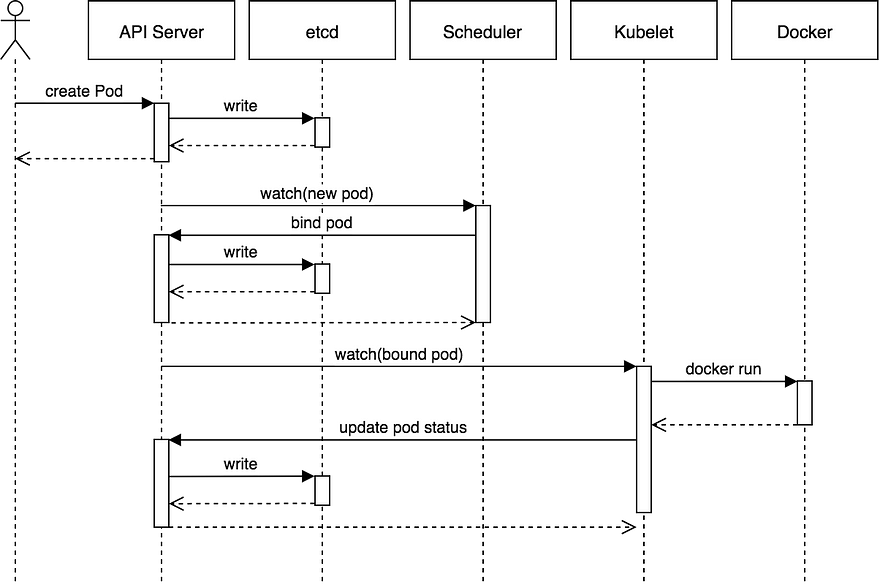
This sequence diagram shows how a typical flow works for scheduling a Pod. This shows the (somewhat rare) case where a user is creating a Pod directly. More typically, the user will create something like a ReplicaSet and it will be the ReplicaSet that creates the Pod.
The basic flow:
- The user creates a Pod via the API Server and the API server writes it to etcd.
- The scheduler notices an “unbound” Pod and decides which node to run that Pod on. It writes that binding back to the API Server.
- The Kubelet notices a change in the set of Pods that are bound to its node. It, in turn, runs the container via the container runtime (i.e. Docker).
- The Kubelet monitors the status of the Pod via the container runtime. As things change, the Kubelet will reflect the current status back to the API Server.
Summing Up
By using the API Server as a central coordination point, Kubernetes is able to have a set of components interact with each other in a loosely coupled manner. Hopefully this gives you an idea of how Kubernetes is more jazz improv than orchestration.
Please give us feedback on this article and suggestions for future “under the covers” type pieces. Hit me up on twitter at @jbeda or @heptio.
(原文地址:https://blog.heptio.com/core-kubernetes-jazz-improv-over-orchestration-a7903ea92ca)
[转]Core Kubernetes: Jazz Improv over Orchestration的更多相关文章
- kubernetes实践之一:kubernetes二进制包安装
kubernetes二进制部署 1.环境规划 软件 版本 Linux操作系统 CentOS Linux release 7.6.1810 (Core) Kubernetes 1.9 Docker 18 ...
- kubernetes 1.14安装部署metrics-server插件
简单介绍: 如果使用kubernetes的自动扩容功能的话,那首先得有一个插件,然后该插件将收集到的信息(cpu.memory..)与自动扩容的设置的值进行比对,自动调整pod数量.关于该插件,在ku ...
- Announcing HashiCorp Consul + Kubernetes
转自:https://www.hashicorp.com/blog/consul-plus-kubernetes We're excited to announce multiple features ...
- 基于TLS证书手动部署kubernetes集群(上)
一.简介 Kubernetes是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernetes也叫K8S. K8S是Google内部一个叫Borg的容器集群管理系统衍生 ...
- Kubernetes - Getting Started With Kubeadm
In this scenario you'll learn how to bootstrap a Kubernetes cluster using Kubeadm. Kubeadm solves th ...
- kubernetes 1.15.1 高可用部署 -- 从零开始
这是一本书!!! 一本写我在容器生态圈的所学!!! 重点先知: 1. centos 7.6安装优化 2. k8s 1.15.1 高可用部署 3. 网络插件calico 4. dashboard 插件 ...
- 一份关于.NET Core云原生采用情况调查
调查背景 Kubernetes 越来越多地在生产环境中使用,围绕 Kubernetes 的整个生态系统在不断演进,新的工具和解决方案也在持续发布.云原生计算的发展驱动着各个企业转向遵循云原生原则(启动 ...
- 二进制方式安装Kubernetes 1.14.2高可用详细步骤
00.组件版本和配置策略 组件版本 Kubernetes 1.14.2 Docker 18.09.6-ce Etcd 3.3.13 Flanneld 0.11.0 插件: Coredns Dashbo ...
- (转)基于TLS证书手动部署kubernetes集群(上)
转:https://www.cnblogs.com/wdliu/archive/2018/06/06/9147346.html 一.简介 Kubernetes是Google在2014年6月开源的一个容 ...
随机推荐
- 【AtCoder】ARC082
C - Together 用一个数组记一下一个数给它本身,左右贡献都是1,看看哪个数的总贡献最大 #include <bits/stdc++.h> #define fi first #de ...
- BZOJ1260 [CQOI2007]涂色paint 动态规划
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1260 题意概括 假设你有一条长度为5的木版,初始时没有涂过任何颜色.你希望把它的5个单位长度分别涂 ...
- java作业第三次作业
(一)作业总结 1.阅读下面程序,分析是否能编译通过?如果不能,说明原因.应该如何修改?程序的运行结果是什么? 为什么子类的构造方法在运行之前,必须调用父 类的构造方法?能不能反过来? class G ...
- STL容器底层数据结构的实现
C++ STL 的实现: 1.vector 底层数据结构为数组 ,支持快速随机访问 2.list 底层数据结构为双向链表,支持快速增删 3.deque ...
- vs2017下发现解决python运行出现‘No module named "XXX""的解决办法
对于使用vs2017开发python程序无疑发现,在解决方案资源管理器中设置把两个xxx.py,yyy.py文件都设置为启动文件,然后分别在vs2017这个IDE下运行这个两个文件在项目工程中运行,发 ...
- HDU 2639 骨头收集者 II【01背包 】+【第K优决策】
题目链接:https://vjudge.net/contest/103424#problem/H 题目大意:与01背包模板题类似,只不过要我们求第K个最大的总价值. 解题分析: 其基本思想是将每个状态 ...
- 大数据系列博客之 --- 深入简出 Shell 脚本语言(提升篇)
首先声明,此系列shell系列博客分为四篇发布,分别是: 基础篇:https://www.cnblogs.com/lsy131479/p/9914747.html 提升篇:https://www.cn ...
- Java 泛型优点之编译时类型检查
Java 泛型优点之编译时类型检查 使用泛型代码要比非泛型代码更有优势,下面是 Java 官方教程对泛型其中一个优点的介绍: "Stronger type checks at compile ...
- 蓝牙扫描工具btscanner修复暴力扫描模式
蓝牙扫描工具btscanner修复暴力扫描模式 在btscanner 2.1-5版本中,当用户按下快捷键b,执行暴力扫描模式,会出现程序奔溃问题.该问题现在已经修复.用户只需要更新系统,将btsc ...
- HDU.1529.Cashier Employment(差分约束 最长路SPFA)
题目链接 \(Description\) 给定一天24h 每小时需要的员工数量Ri,有n个员工,已知每个员工开始工作的时间ti(ti∈[0,23]),每个员工会连续工作8h. 问能否满足一天的需求.若 ...