大数据是什么?它和Hadoop又有什么联系?
随着近几年计算机技术和互联网的发展,“大数据”这个名词越来越多进入我们的视野。大数据的快速发展也在无时无刻影响着我们的生活。
那大数据究竟是什么呢?
首先,看看专家是怎么解释大数据的:
大数据就是多,就是多。原来的设备存不下、算不动。 ——啪菠萝·毕加索
大数据,不是随机样本,而是所有数据;不是精确性,而是混杂性;不是因果关系,而是相关关系。—— Schönberger
顾名思义“大数据”,从字面意思来理解就是“大量的数据”。
从技术的的角度来解释,大数据就是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
IBM提出大数据具有5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
我们所谈论的大数据实际上更多是从应用的层面,比如某公司搜集、整理了大量的用户行为信息,然后通过数据分析手段对这些信息进行分析从而得出对公司有利用价值的结果。
比如:头条的推荐机制,就是建立在对海量用户的阅读信息的搜集、分析之上。这就是大数据在现实中具体体现。
那Hadoop又是什么?它和大数据又有什么联系呢?
Hadoop是一个对海量数据进行处理的分布式系统架构,可以理解为Hadoop就是一个对大量的数据进行分析的工具,和其他组件搭配使用,来完成对大量数据的收集、存储和计算。
Hadoop框架最核心的设计就是:HDFS 和 MapReduce。
HDFS为海量的数据提供了存储;MapReduce为海量的数据提供了计算。
一套完整的Hadoop大数据生态系统基本包含这些组件。
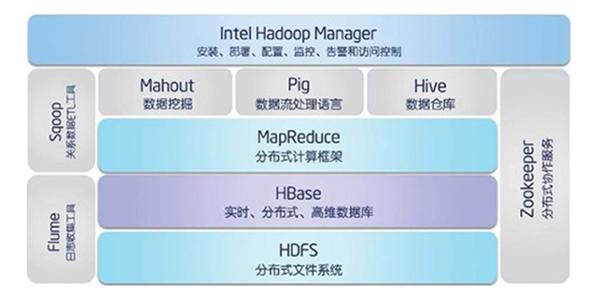
HDFS:Hadoop分布式文件系统,专门存储超大数据文件,为整个Hadoop生态圈提供了基础的存储服务。
MapReduce:分布式离线计算框架,用来处理大量的已经存储在本地的离线数据。
Storm:分布式实时计算,主要特点是实时性,用来处理实时产生的数据。
ZooKeeper:用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
HBase:是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。
Hive:基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表。
Sqoop:是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。
Pig:它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
--------------------- 本文来自 扑满心 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/sinat_38648491/article/details/78915306?utm_source=copy
大数据是什么?它和Hadoop又有什么联系?的更多相关文章
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了
一文看懂大数据的技术生态圈,Hadoop,hive,spark都有了 转载: 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你可以把它 ...
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 大数据系列(1)——Hadoop集群坏境搭建配置
前言 关于时下最热的技术潮流,无疑大数据是首当其中最热的一个技术点,关于大数据的概念和方法论铺天盖地的到处宣扬,但其实很多公司或者技术人员也不能详细的讲解其真正的含义或者就没找到能被落地实施的可行性方 ...
- 【大数据】Summingbird(Storm + Hadoop)的demo运行
一.前言 为了运行summingbird demo,笔者走了很多的弯路,并且在国内基本上是查阅不到任何的资料,耗时很久才搞定了demo的运行.真的是一把辛酸泪,有兴趣想要研究summingbird的园 ...
- 【ZZ】大数据架构师基础:hadoop家族,Cloudera系列产品介绍
http://www.36dsj.com/archives/17192 大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为 ...
- 大数据架构师基础:hadoop家族,Cloudera产品系列等各种技术
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师选 ...
随机推荐
- JavaScript indexOf() 方法
定义和用法 indexOf() 方法可返回某个指定的字符串值在字符串中首次出现的位置. 语法 stringObject.indexOf(searchvalue,fromindex) 说明 该方法将从头 ...
- SpringBoot-@value自定义参数
自定义参数 配置文件值 name=itmayiedu.com 代码: @Value("${name}") private String name; @Res ...
- python操作rabbitMQ小结
1.安装rabbitMQ(与python无关) https://www.cnblogs.com/libra0920/p/7920698.html 2.python+rabbitMQ实现生产者和消费者模 ...
- echart 设计宽度为百分比时,div撑不开
解决思路:将百分比换算成px 一句话搞定 ("#chart").css( 'width', $("#chart").width() );$("#cha ...
- Redis缓存机制一为什么要用Redis
1.持久化数据库的缺点 1)存储在部署数据库的硬盘上 平时我们使用的关系型数据库有MySql,Oracle以及SqlServer等,通常通过数据驱动来链接数据库进行增删改查. 那么 ...
- 如何把Composer镜像迁移到Laravel China 维护的镜像?
今天在更新Laravel-admin:1.6.0提示没有对应的包,后面才发现需要使用官方或者 Laravel-China 的 composer 镜像,phpcomposer 镜像已经停止维护了.怎么从 ...
- docker+Nexus Repository Manager 搭建私有docker仓库
使用容器安装Nexus3 1.下载nexus3的镜像: docker pull sonatype/nexus3 2.使用镜像启动一个容器: docker run -d -p 8081:8081 -p ...
- NginxI/O模型理论基础
I/O模型介绍 同步IO 关注的是消息通信机制 调用者需要等待被调用者先执行完毕才能往下继续执行 被调用者在执行完自己的任务后并不会同之调用者执行结果需要调用者自己去获取被调用者的执行状态 异步 ...
- eos 空投列表网址 及 工具网站列表
https://eosdrops.io https://www.shensi.com/#/eos eos 区块链浏览器: https://eostracker.io/ https://eospark. ...
- cmd项目目录结构以及配置文件的升级编写
一.项目的目录结构: bin:执行文件夹 config:自定义配置文件 lib:公共的模块或者类文件 src:核心业务逻辑代码 二.配置文件的编写 1)config代码如下 from lib.conf ...