PLSA主题模型
主题模型
主题模型这样理解一篇文章的生成过程:
1、 确定文章的K个主题。
2、 重复选择K个主题之一,按主题-词语概率生成词语。
3、 所有词语组成文章。
这里可以看到,主题模型仅仅考虑词语的数量,不考虑词语的顺序,所以主题模型是词袋模型。
主题模型有两个关键的过程:
1、 doc -> topic
2、 topic -> word
其中topic -> word是定值,doc -> topic是随机值。这是显而易见的,对于不同的文章,它的主题不尽相同,但是对于同一个主题,它的词语概率应该是一致的。好比记者写了一篇科技新闻和一篇金融新闻,两篇新闻的主题分布必然不同,但是这两篇文章都包含数学主题,那么对于数学主题出现的词语应该大致相同。
主题模型的关键就是要计算出topic -> word过程,也就是topic-word概率分布。对于一篇新的文章,我们已知它的词语数量分布,又训练出了topic-word概率分布,则可以使用最优化方法分析出文章对应的K个最大似然主题。
PLSA
PSLA主题模型正是上述思想的直接体现,文章生成过程如下

PLSA主题模型图形化过程如下
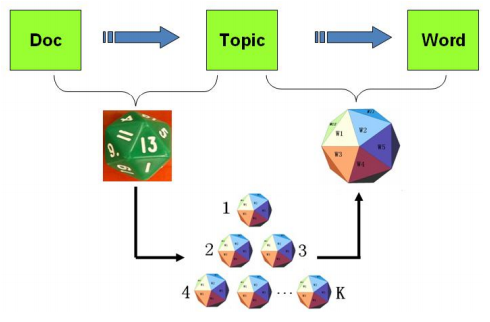
我们考虑第m篇文档的生成过程,其中涉及1个doc-topic骰子,K个topic-word骰子。记第m篇文档为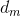 ,第m篇文章出现第z个主题的概率为
,第m篇文章出现第z个主题的概率为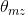 ,第z个主题生成词语w的概率为
,第z个主题生成词语w的概率为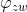 (这里与文档有关系,与文档没有关系)。对于某个词语的生成概率,即投掷一次doc-topic骰子与一次topic-word骰子生成词语w的概率为
(这里与文档有关系,与文档没有关系)。对于某个词语的生成概率,即投掷一次doc-topic骰子与一次topic-word骰子生成词语w的概率为
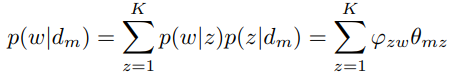
于是第m篇文档的n个词语生成概率为
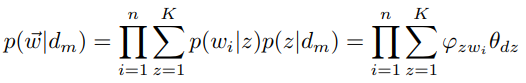
如果我们有M篇文档,考虑到文档之间独立,则所有词语生成的概率为M个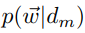 的乘积。
的乘积。
PLSA模型最优化包含两个参数求解,可以使用EM算法计算。读者有兴趣可以参考前面的文章。
参考:《LDA数学八卦》
PLSA主题模型的更多相关文章
- 主题模型(概率潜语义分析PLSA、隐含狄利克雷分布LDA)
一.pLSA模型 1.朴素贝叶斯的分析 (1)可以胜任许多文本分类问题.(2)无法解决语料中一词多义和多词一义的问题--它更像是词法分析,而非语义分析.(3)如果使用词向量作为文档的特征,一词多义和多 ...
- 【机器学习】主题模型(二):pLSA和LDA
-----pLSA概率潜在语义分析.LDA潜在狄瑞雷克模型 一.pLSA(概率潜在语义分析) pLSA: -------有过拟合问题,就是求D, Z, W pLSA由LSA发展过来,而早期L ...
- LDA( Latent Dirichlet Allocation)主题模型 学习报告
1 问题描述 LDA由Blei, David M..Ng, Andrew Y..Jordan于2003年提出,是一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一 ...
- [综] Latent Dirichlet Allocation(LDA)主题模型算法
多项分布 http://szjc.math168.com/book/ebookdetail.aspx?cateid=1&§ionid=983 二项分布和多项分布 http:// ...
- Latent Dirichlet Allocation 文本分类主题模型
文本提取特征常用的模型有:1.Bag-of-words:最原始的特征集,一个单词/分词就是一个特征.往往一个数据集就会有上万个特征:有一些简单的指标可以帮助筛选掉一些对分类没帮助的词语,例如去停词,计 ...
- 主题模型-LDA浅析
(一)LDA作用 传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似 ...
- LDA主题模型
(一)LDA作用 传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似 ...
- 文本主题模型之非负矩阵分解(NMF)
在文本主题模型之潜在语义索引(LSI)中,我们讲到LSI主题模型使用了奇异值分解,面临着高维度计算量太大的问题.这里我们就介绍另一种基于矩阵分解的主题模型:非负矩阵分解(NMF),它同样使用了矩阵分解 ...
- 文本主题模型之潜在语义索引(LSI)
在文本挖掘中,主题模型是比较特殊的一块,它的思想不同于我们常用的机器学习算法,因此这里我们需要专门来总结文本主题模型的算法.本文关注于潜在语义索引算法(LSI)的原理. 1. 文本主题模型的问题特点 ...
随机推荐
- Matlab中导入文本文件中的数据 矩阵合并 以及C++中删除文件操作
今天用到了Matlab读取文本文件中按照一定格式存储好的数据,然后进行后续的分析计算等,因此涉及到Matlab的文件读取,记录在这里,供以后查阅: fid = fopen('train.set', ' ...
- 27-4-DMA2D图形加速器
在实际使用 LTDC 控制器控制液晶屏时,使 LTDC 正常工作后,往配置好的显存地址写入要显示的像素数据, LTDC 就会把这些数据从显存搬运到液晶面板进行显示,而显示数据的容量非常大,所以我们希望 ...
- ReentrantLock可重入锁的原理及使用场景
摘要 从使用场景的角度出发来介绍对ReentrantLock的使用,相对来说容易理解一些. 场景1:如果已加锁,则不再重复加锁 a.忽略重复加锁.b.用在界面交互时点击执行较长时间请求操作时,防止多次 ...
- 前端 HTML 常用标签 head标签相关内容 link标签
link标签 引入CSS样式文件 href="./index.css" CSS文件的路径 <!-- 引入CSS样式文件 --> <link rel="s ...
- vs2015智能提示英文改为中文
vs2015智能提示英文改为中文 C:\Program Files (x86)\Reference Assemblies\Microsoft\Framework\.NETFramework 进入 \v ...
- dedecms批量修改文章为待审核稿件怎么操作
dedecms批量修改文章为待审核稿件要怎么操作呢?因为我们有时会出于某些原因要把文章暂时先隐藏掉,dedecms有一个比较好的功能是将文件状态设为未审核前台就可以看不到了,那要怎么批量设置呢?到后台 ...
- Python日期与字符串互转
import datetime #str -> date detester = '2017-01-01' date = datetime.datetime.strptime(detester,' ...
- 萌新接触前端的第三课——JavaScript
JavaScript概述 一.JavaScript的历史 1992年Nombas开发出C-minus-minus(C--)的嵌入式脚本语言(最初绑定在CEnvi软件中).后将其改名ScriptEase ...
- kafka5 编写简单生产者
一 客户端 1.打开eclipse,新建maven项目(new-->other-->Maven Project-->Artifact Id设为mykafka). 2.配置Build ...
- 008-spring cache-缓存实现-03-springboot redis实现
1.window下redis安装 https://www.cnblogs.com/bjlhx/p/7429811.html 2.pom <!-- 缓存 --> <dependency ...