Spring Cloud 各组件调优参数
Spring Cloud整合了各种组件,每个组件往往还有各种参数。本文来详细探讨Spring Cloud各组件的调优参数。
Tomcat配置参数
1 server:
2 tomcat:
3 max-connections: 0 # 默认值
4 max-threads: 0 # 默认值
Hystrix配置参数
- 如隔离策略是THREAD:
1 hystrix.threadpool.default.coreSize: 10
2 hystrix.threadpool.default.maximumSize: 10
3 hystrix.threadpool.default.maxQueueSize: -1 # 如该值为-1,那么使用的是SynchronousQueue,
4 否则使用的是LinkedBlockingQueue。
5 注意,修改MQ的类型需要重启。例如从-1修改为100,需要重启,因为使用的Queue类型发生了变化
如果想对特定的HystrixThreadPoolKey 进行配置,则将default 改为 HystrixThreadPoolKey 即可。
- 如果隔离策略是SEMAPHORE:
1 hystrix.command.default.execution.isolation.strategy: SEMAPHORE
2 hystrix.command.default.execution.isolation.semaphore.maxConcurrentRequests: 10 # 默认值
如果想对指定的HystrixCommandKey 进行配置,则将default 改为HystrixCommandKey 即可。
Feign配置参数
Feign默认没有线程池。
当使用HttpClient时,可如下设置:
1 feign:
2 httpclient:
3 enabled: true
4 max-connections: 200 # 默认值
5 max-connections-per-route: 50 # 默认值
代码详见:
org.springframework.cloud.netflix.feign.FeignAutoConfiguration.
HttpClientFeignConfiguration#connectionManager
org.springframework.cloud.netflix.feign.ribbon.
HttpClientFeignLoadBalancedConfiguration.HttpClientFeignConfiguration#connectionManager
当使用OKHttp时,可如下设置:
1 feign:
2 okhttp:
3 enabled: true
4 httpclient:
5 max-connections: 200 # 默认值
6 max-connections-per-route: 50 # 默认值
代码详见:
org.springframework.cloud.netflix.feign.FeignAutoConfiguration.
OkHttpFeignConfiguration#httpClientConnectionPool 。
org.springframework.cloud.netflix.feign.ribbon.OkHttpFeignLoadBalancedConfiguration.
OkHttpFeignConfiguration#httpClientConnectionPool
Zuul配置参数
我们知道Hystrix有隔离策略:THREAD 以及SEMAPHORE ,默认是 SEMAPHORE 。
隔离策略
1 zuul:
2 ribbon-isolation-strategy: thread
最大信号
当Zuul的隔离策略为SEMAPHORE时:
设置默认最大信号量:
1 zuul:
2 semaphore:
3 max-semaphores: 100 # 默认值
设置指定服务的最大信号量:
1 zuul:
2 eureka:
3 <commandKey>:
4 semaphore:
5 max-semaphores: 100 # 默认值
参考:
- https://github.com/spring-cloud/spring-cloud-netflix/issues/1130
- https://github.com/spring-cloud/spring-cloud-netflix/issues/1362 ,非常重要,里面指出,不同版本配置略有差异。
<commandKey>在Brixton.SR5及更早版本中,是<serviceId>RibbonCommand,从Brixton.SR6开始,<commandKey>只需写<serviceId>即可,即:服务注册到Eureka Server上的名称。
Zuul参数
- Hystrix并发参数
Edgware及之后的版本中,当Zuul的隔离策略为THREAD时,可为Hystrix配置独立线程池:
参考:http://www.itmuch.com/spring-cloud/edgware-new-zuul-hystrix-thread-pool/
如果不设置独立线程池,那么HystrixThreadPoolKey 是 RibbonCommand 。
Hystrix并发配置参数请参考《Hystrix并发配置参数一节》
- Zuul并发参数:
Zuul内置的Filterhttp://www.itmuch.com/%2Fspring-cloud%2Fzuul%2Fzuul-filter-in-spring-cloud%2F
对于形如:
1 zuul:
2 routes:
3 user-route: # 该配置方式中,user-route只是给路由一个名称,可以任意起名。
4 url: http://localhost:8000/ # 指定的url
5 path: /user/** # url对应的路径。
的路由,可使用如下方式配置并发参数:
1 zuul:
2 host:
3 max-total-connections: 200 # 默认值
4 max-per-route-connections: 20 # 默认值
- 当Zuul底层使用的是Apache HttpClient时,对于使用Ribbon的路由,可使用如下方式配置并发参数:
1 serviceId:
2 ribbon:
3 MaxTotalConnections: 0 # 默认值
4 MaxConnectionsPerHost: 0 # 默认值
相关代码:org.springframework.cloud.netflix.ribbon.support.AbstractLoadBalancingClient 子类的createDelegate 方法。
springcloud之Feign、ribbon设置超时时间和重试机制的总结
因为测试 Feign + Hystrix 搭配模式下的降级(fallback)超时时间自定义问题,这里的不同组件的超时时间设置问题。
一、 Feign设置超时时间
使用Feign调用接口分两层,ribbon的调用和hystrix的调用,所以ribbon的超时时间和Hystrix的超时时间的结合就是Feign的超时时间
#hystrix的超时时间
hystrix:
command:
default:
execution:
timeout:
enabled: true
isolation:
thread:
timeoutInMilliseconds: 9000
#ribbon的超时时间
ribbon:
ReadTimeout: 3000
ConnectTimeout: 3000
一般情况下 都是 ribbon 的超时时间(<)hystrix的超时时间(因为涉及到ribbon的重试机制)
Feign中,默认使用的Retryer是NEVER_RETRY,
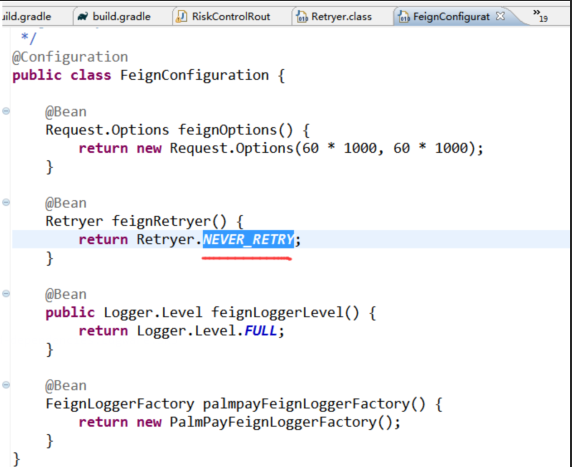
因为ribbon的重试机制和Feign的重试机制有冲突,所以NEVER_RETRY源码中默认关闭Feign的重试机制,源码如下:

要开启Feign的重试机制如下:(Feign默认重试五次 源码中有)
@Bean
Retryer feignRetryer() {
return new Retryer.Default();
}
Feign的default的retryer源码如下:
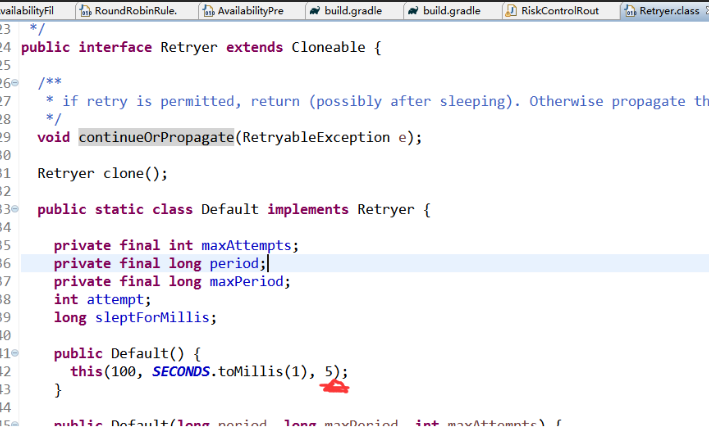
二、ribbon的重试机制
设置重试次数:
ribbon:
ReadTimeout: 3000
ConnectTimeout: 3000
MaxAutoRetries: 1 #同一台实例最大重试次数,不包括首次调用
MaxAutoRetriesNextServer: 1 #重试负载均衡其他的实例最大重试次数,不包括首次调用
OkToRetryOnAllOperations: false #是否所有操作都重试
根据上面的参数计算重试的次数:MaxAutoRetries+MaxAutoRetriesNextServer+(MaxAutoRetries *MaxAutoRetriesNextServer) 即重试3次 则一共产生4次调用
设置超时ribbon的超时时间
如果在重试期间,时间超过了hystrix的超时时间,便会立即执行熔断,fallback。所以要根据上面配置的参数计算hystrix的超时时间,使得在重试期间不能达到hystrix的超时时间,不然重试机制就会没有意义
hystrix超时时间的计算: (1 + MaxAutoRetries + MaxAutoRetriesNextServer) * ReadTimeout 即按照以上的配置 hystrix的超时时间应该配置为 (1+1+1)*3=9秒
当ribbon超时后且hystrix没有超时,便会采取重试机制。当OkToRetryOnAllOperations设置为false时,只会对get请求进行重试。如果设置为true,便会对所有的请求进行重试,如果是put或post等写操作,如果服务器接口没做幂等性,会产生不好的结果,所以OkToRetryOnAllOperations慎用。
如果不配置ribbon的重试次数,默认会重试一次
注意:
默认情况下,GET方式请求无论是连接异常还是读取异常,都会进行重试
非GET方式请求,只有连接异常时,才会进行重试
断路器超时与Ribbon超时关系
背景
springCloud:Finchley.RELEASE
官方建议
当Ribbon客户端和hystrix同时使用时,您需要确保您的hystrix超时时间配置比Ribbon超时时间更长,包括可能进行的重试。例如,如果您的Ribbon连接超时为1秒,而Ribbon客户端可能会重试该请求3次,则hystrix超时应该略大于3秒。
三、如何设置Hystrix线程池大小
Hystrix线程池大小默认为10hystrix:
threadpool:
default:
coreSize: 10
每秒请求数 = 1/响应时长(单位s) * 线程数 = 线程数 / 响应时长(单位s)
也就是
线程数 = 每秒请求数 * 响应时长(单位s) + (缓冲线程数)
标准一点的公式就是QPS * 99% cost + redundancy count
比如一台服务, 平均每秒大概收到20个请求,每个请求平均响应时长估计在500ms,
线程数 = 20 * 500 / 1000 = 10
为了应对峰值高并发,加上缓冲线程,比如这里为了好计算设为5,就是 10 + 5 = 15个线程
Spring Cloud 各组件调优参数的更多相关文章
- Dubbo性能调优参数及原理
本文是针对 Dubbo 协议调用的调优指导,详细说明常用调优参数的作用域及源码. Dubbo调用模型 常用性能调优参数 参数名 作用范围 默认值 说明 备注 threads provider 200 ...
- Spring Cloud各个组件的配套使用
我们从整体上来看一下Spring Cloud各个组件如何来配套使用: 从上图可以看出Spring Cloud各个组件相互配合,合作支持了一套完整的微服务架构. 其中Eureka负责服务的注册与发现, ...
- Linux TCP/IP调优参数 /proc/sys/net/目录
所有的TCP/IP调优参数都位于/proc/sys/net/目录. 例如, 下面是最重要的一些调优参数,后面是它们的含义: /proc/sys/net/core/rmem_default " ...
- hadoop作业调优参数整理及原理
hadoop作业调优参数整理及原理 10/22. 2013 1 Map side tuning参数 1.1 MapTask运行内部原理 当map task开始运算,并产生中间数据时,其产生的中间结果并 ...
- Spring Cloud 各个组件介绍
从上图可以看出 Spring Cloud 各个组件相互配合,合作支持了一套完整的微服务架构: Eureka 负责服务的注册与发现,很好地将各服务连接起来. Hystrix 负责监控服务之间的调用情况, ...
- JVM性能调优的6大步骤,及关键调优参数详解
JVM性能调优方法和步骤1.监控GC的状态2.生成堆的dump文件3.分析dump文件4.分析结果,判断是否需要优化5.调整GC类型和内存分配6.不断分析和调整JVM调优参数参考 对JVM内存的系统级 ...
- Spring Cloud常用组件及各组件版本对应关系图
Spring Cloud常用组件: 架构图: 版本对应关系:
- 直通BAT必考题系列:JVM性能调优的6大步骤,及关键调优参数详解
JVM内存调优 对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数. 1.Full GC 会对整个堆进行整理,包括Young.Tenured和Perm.Full GC因为需要对 ...
- JVM调优参数、方法、工具以及案例总结
这种文章挺难写的,一是JVM参数巨多,二是内容枯燥乏味,但是想理解JVM调优又是没法避开的环节,本文主要用来总结梳理便于以后翻阅,主要围绕四个大的方面展开,分别是JVM调优参数.JVM调优方法(流程) ...
随机推荐
- alpha冲刺(1/10)(作废)
前言 队名:旅法师 作业链接 队长博客 燃尽图 会议 站立式会议照片 会议内容 陈晓彬(组长) 昨日进展: 召开会议 安排任务 博客撰写 问题困扰: 没有做项目经理的经验,在沟通方面专业知识不够. 心 ...
- 【状压DP】【HDOJ1074】
http://acm.hdu.edu.cn/showproblem.php?pid=1074 Doing Homework Time Limit: 2000/1000 MS (Java/Others) ...
- 【HDOJ1384】【差分约束+SPFA】
http://acm.hdu.edu.cn/showproblem.php?pid=1384 Intervals Time Limit: 10000/5000 MS (Java/Others) ...
- Java中类的构造方法
constructor:构造函数. 在创建对象的时候,对象成员可以由构造函数方法进行初始化. new对象时,都是用构造方法进行实例化的: 例如:Test test = new Test("a ...
- java super的用法
通过用static来定义方法或成员,从某种程度上可以说它类似于C语言中的全局函数和全局变量. this&super这两个关键字的意义和用法. 在Java中,this通常指当前对象,super则 ...
- 【HAOI2012】外星人
又犯sb错了QAQ 原题: 艾莉欧在她的被子上发现了一个数字 ,她觉得只要找出最小的x使得,.根据这个 她就能找到曾经绑架她的外星人的线索了.当然,她是不会去算,请你帮助她算出最小的x. test&l ...
- Js判断字符的种类
Js判断字符的种类:unicode范围: 48-57:0-9 数字字符 65-90:A-Z 大写字母 97-122: a-z 小写字母 19968-40869:汉字 其他字符 实例:输出 ...
- nginx负载均衡算法
配置方式 NGINX配置负载均衡主要是在nginx.conf文件中里upstream模块 1.upstream模块应放于nginx.conf配置的http{}标签内2.upstream模块默认算法是w ...
- Scala方法定义,方法和函数的区别,将方法转换成函数
1. 定义方法和函数 1.1. 定义方法 方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归函数,必须指定返回类型 1.2. 定义函数 1.3.方法和函数的区别 在函数式编程语言中,函数是 ...
- encrypt and decrypt data
https://www.cyberciti.biz/tips/linux-how-to-encrypt-and-decrypt-files-with-a-password.html Encryptin ...