MQ之Kafka
现代的互联网分布式系统,只要稍微大一些,就一定逃不开3类中间件:远程调用(RPC)框架、消息队列、数据库访问中间件。Kafka 是消息队列中间件的代表产品,用 Scala 语言实现;
基本概念
首先,Kafka 中有一些基本的概念需要熟悉。
- Topic,指消息的类别,每个消息都必须有;
- Producer,指消息的产生者,或者,消息的写端;
- Consumer,指消息的消费者,或者,消息的读端;
- Producer Group,指产生者组,组内的生产者产生同一类消息;
- Consumer Group,指消费者组,组内的消费者消费同一类消息;
- Broker,指消息服务器,Producer 产生的消息都是写到这里,Consumer 读消息也是从这里读;
- Zookeeper,是 Kafka 的注册中心,Broker 和 Consumer 之间的协调器,包含状态信息、配置信息和一些 Topic 的信息;
- Partition,指消息的水平分区,一个 Topic 可以有多个分区;
- Replica,指消息的副本,为了提高可用性,将消息副本保存在其他 Broker 上。
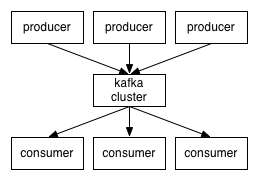
特别说明,Broker 是指单个消息服务进程,一般情况下,Kafka 是集群运行的,Broker 只是集群中的一个服务进程,而非代指整个 Kafka 服务,可以简单将 Broker 理解成服务器(Server)。Kafka 引入的术语都比较常见,从字面上理解相对直观。Kafka 的大致结构图是这样:
(Kafka 是 Pull 模式的消息队列,即 Consumer 连到消息队列服务上,主动请求新消息,如果要做到实时性,需要采用长轮询,Kafka 在0.8的时候已经支持长轮询模式。上图中 Consumer 的连接箭头方向可能会让读者误以为是 Push 模式,特此注明)
关于顺序和分区
Kafka 是一个力求保持消息顺序性的消息队列,但不是完全保证,其保证的是 Partition 级别的顺序性,如下图:

此图是 Topic 的分区 log 的示意图,可见,每个分区上的 log 都是一个有序的队列,所以,Kafka 是分区级别有序的。如果,某个 Topic 只有一个分区,那么这个 Topic 下的消息就都是有序的。
分区是为了提升消息处理的吞吐率而产生的,将一个 Topic 中的消息分成几份,分别给不同的 Broker 处理。如下图:

此图中有2个 Broker,Server 1 和 Server 2,每个 Broker 上有2个分区,总共4个分区,P0 ~ P3;有2个 Consumer Group,Consumer Group A 有2个 Consumer,Consumer Group B 有4个 Consumer。Kafka 的实现是,在稳定的情况下,维持固定的连接,每个 Consumer 稳定的消费其中某几个分区的消息,以上图举例,Consumer Group A 中的 C1 稳定消费 P0、P3,C2 稳定消费 P1、P2。这样的连接分配可能会导致消息消费的不均匀分布,但好处是比较容易保证顺序性。
维持完全的顺序性在分布式系统看来几乎是无意义的。因为,如果需要维持顺序性,那么就只能有一条线程阻塞的处理顺序消息,即,Producer -> MQ -> Consumer 必须线程上一一对应。这与分布式系统的初衷是相违背的。但是局部的有序性,是可以维持的。比如,有30000条消息,每3条之间有关联,1->2->3,4->5->6,……,但是全局范围来看,并不需要保证 1->4->7,可以 7->4->1 的顺序来执行,这样可以达到最大并行度10000,而这通常是现实中我们面对的情况。通常应用中,将有先后关系的消息发送到相同的分区上,即可解决大部分问题。
关于副本
副本是高可用 Kafka 集群的实现方式。假设集群中有3个 Broker,那么可以指定3个副本,这3个副本是对等的,对于某个 Topic 的分区来说,其中一个是 Leader,即主节点,另外2个副本是 Follower,即从节点,每个副本在一个 Broker 上。当 Leader 收到消息的时候,会将消息写一份到副本中,通常情况,只有 Leader 处于工作状态。在 Leader 发生故障宕机的时候,Follwer 会取代 Leader 继续传送消息,而不会发生消息丢失。Kafka 的副本是以分区为单位的,也就是说,即使是同一个 Topic,其不同分区的 Leader 节点也不同。甚至,Kafka 倾向于用不同的 Broker 来做分区的 Leader,因为这样能做到更好的负载均衡。
在副本间的消息同步,实际上是复制消息的 log,复制可以是同步复制,也可以是异步复制。同步复制是说,当 Leader 收到消息后,将消息写入从副本,只有在收到从副本写入成功的确认后才返回成功给 Producer;异步复制是说,Leader 将消息写入从副本,但是不等待从副本的成功确认,直接返回成功给 Producer。同步复制效率较低,但是消息不会丢;异步复制效率高,但是在 Broker 宕机的时候,可能会出现消息丢失。
关于丢消息和重复收到消息
任何一个 MQ 都需要处理丢消息和重复收到消息的,正常情况下,Kafka 可以保证:1. 不丢消息;2. 不重复发消息;3. 消息读且只读一次。当然这都是正常情况,极端情况,如 Broker 宕机,断电,这类情况下,Kafka 只能保证 1 或者 2,无法保证 3。
在有副本的情况下,Kafka 是可以保证消息不丢的,其前提是设置了同步复制,这也是 Kafka 的默认设置,但是可能出现重复发送消息,这个交给上层应用解决;在生产者中使用异步提交,可以保证不重复发送消息,但是有丢消息的可能,如果应用可以容忍,也可以接受。如果需要实现读且只读一次,就比较麻烦,需要更底层的 API 4。
MQ之Kafka的更多相关文章
- 物联网架构成长之路(28)-Docker练习之MQ中间件(Kafka)
0. 前言 消息队列MQ,这个在一般的系统上都是会用到的一个中间件,我选择Kafka作为练手的一个中间件,Kafka依赖Zookeeper.Zookeeper安装上一篇博客已经介绍过了. 1. Kaf ...
- 高并发系列之——MQ消息中间件Kafka
1.前言 1.1 包路径和源码 下载链接 基于发布订阅的分布式消息系统,使用scala语言编写. 特点:采用分区机制,每个分区可以放到不同的服务器上,提高了吞吐率,同时基于磁盘存储,以及副本机制可以确 ...
- 高性能消息队列(MQ)Kafka 简单由来介绍(1)
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据. 这种动作(网页浏 ...
- Kafka,Mq,Redis作为消息队列使用时的差异?
redis 消息推送(基于分布式 pub/sub)多用于实时性较高的消息推送,并不保证可靠.其他的mq和kafka保证可靠但有一些延迟(非实时系统没有保证延迟).redis-pub/sub断电就清空, ...
- Kafka,Mq,Redis作为消息队列有何差异?
Kafka作为新一代的消息系统,mq是比较成熟消息系统,而redis也可以发布订阅,那么这三者有何异同? RabbitMQ 是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,X ...
- RabbitMq、ActiveMq、Kafka和Redis做Mq对比
转载自:https://blog.csdn.net/qiqizhiyun/article/details/79848834 一.RabbitMq RabbitMQ是一个Advanced Message ...
- kafka与传统的消息中间件对比
RabbitMQ和kafka从几个角度简单的对比 业界对于消息的传递有多种方案和产品,本文就比较有代表性的两个MQ(rabbitMQ,kafka)进行阐述和做简单的对比, 在应用场景方面, Rabbi ...
- 升级tomcat7的运行日志框架到log4j2,可以打进kafka
为了让web application能随意使用logging组件而不受web容器自身的影响,从tomcat 6.0开始,tomact默认使用的是java.util.logging framework来 ...
- RabbitMQ和kafka从几个角度简单的对比--转
业界对于消息的传递有多种方案和产品,本文就比较有代表性的两个MQ(rabbitMQ,kafka)进行阐述和做简单的对比, 在应用场景方面, RabbitMQ,遵循AMQP协议,由内在高并发的erlan ...
随机推荐
- scp - 安全复制(远程文件复制程序)
总览 SYNOPSIS scp -words [-pqrvBC1246 ] [-F ssh_config ] [-S program ] [-P port ] [-c cipher ] [-i ide ...
- java解析xml(使用jdom解析xml)
第一步: 装入jar包:下载地址:http://www.jdom.org/downloads/index.html 第二步: 在项目中加入jar包 jdom-2.06.jar 放入lib中 第三步: ...
- chrome插件研发手册
chrome插件研发手册 一:需求前景 对于研发的小伙伴来说,总会遇到这样的需求,想要通过代码操作已有网站的行为动作,如:自动填充表格内容(表单内容太多,想一键将表单内容填充):自动登录网站(网站登录 ...
- Jmeter --Json Extractor (后置处理器)
一.使用场景 Json Extractor 后置处理器用在返回格式为json的HTTP请求中, 用来获取返回的json中的某个值.并保存成变量供后面的请求进行调用或者断言等. 二.使用方法 1.创建H ...
- 数据库与缓存:2.Redis数据库的基本知识
1.属于什么类型的数据库 not only sql 非关系型数据库,与传统的关系型数据库不同,存储形式都是kv形式. 2.特点 几乎不支持事务,key-value形式存储,支持队列和缓存(可以设置数 ...
- java中switch的用法以及判断的类型有哪些(String\byte\short\int\char\枚举类型)
switch关键字对于多数java学习者来说并不陌生,由于笔试和面试经常会问到它的用法,这里做了一个简单的总结: 能用于switch判断的类型有:byte.short.int.char(JDK1.6) ...
- Ubuntu新建用户组
新建用户组 sudo addgroup groupname 把现有用户加入新建的用户组 sudo adduser username groupname
- loadRunner函数之web_add_header
web_add_header 功能:用于添加指定的报文头到下一次HTTP请求 格式:web_add_header( const char *Header, const char *Content ), ...
- CSD编码----数字信号处理--006
有符号数(Signed Digit Number , SD) SD编码 1.有三重值 {0,1,-1} 2.应用在不用进位的加法器或乘法器中能够降低复杂性 因为通常可以通过非零元素的数来估计乘法的工作 ...
- Python中的时间模块和日期模块
Python 日期和时间 Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能. Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间. 时间间 ...