Python爬虫:HTTP协议、Requests库(爬虫学习第一天)
HTTP协议:
HTTP(Hypertext Transfer Protocol):即超文本传输协议。URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源。
HTTP协议对资源的操作:

Requests库提供了HTTP所有的基本请求方式。官方介绍:http://www.python-requests.org/en/master
Requests库的6个主要方法:
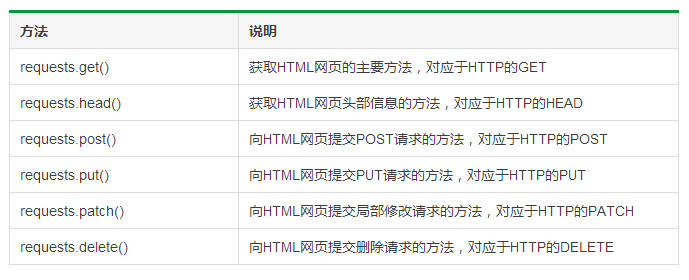
Requests库的异常:
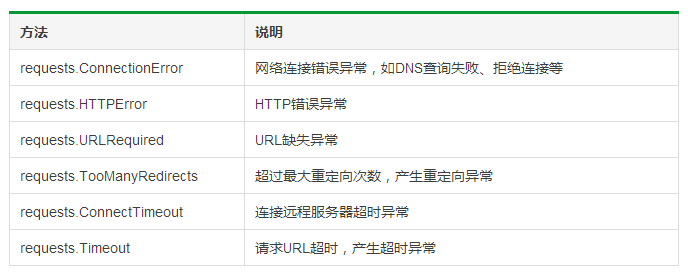
Requests库的两个重要对象:Request(请求)、Response(相应)。Request对象支持多种请求方法;Response对象包含服务器返回的所有信息,也包含请求的Request信息。
Response对象的属性:

其中,r.encoding指:如果header中不存在charset,则认为编码为ISO‐8859‐1。
r.raise_for_status()可以直接知道r.status_code是否等于200。
HTTP协议与Requests库对比:
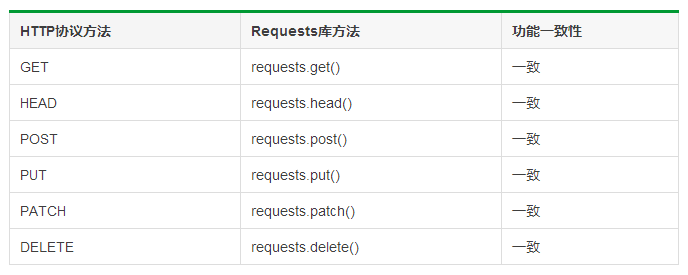
爬取网页的通用代码框架:
1 try:
2 r = requests.get(url,timeout = 30)
3 r.raise_for_status()
4 # 如果状态不是200,引发HTTPError异常
5 r.encoding = r.apparent_encoding
6 return r.text
7 except:
8 return '产生异常'
例如,获取PMCAFF首页的信息:
1 import requests
2
3 def getHtmlText(url):
4 try:
5 r = requests.get(url,timeout = 30)
6 r.raise_for_status()
7 r.encoding = r.apparent_encoding
8 return r.text
9 except:
10 return '产生异常'
11
12 if __name__ == '__main__':
13 url = 'https://www.pmcaff.com/'
14 print(getHtmlText(url))
爬取网页的通用代码框架:操作环境:win,Python 3.6
参考资料:中国大学MOOC课程《Python网络爬虫与信息提取》
Python爬虫:HTTP协议、Requests库(爬虫学习第一天)的更多相关文章
- 从0开始学爬虫9之requests库的学习之环境搭建
从0开始学爬虫9之requests库的学习之环境搭建 Requests库的环境搭建 环境:python2.7.9版本 参考文档:http://2.python-requests.org/zh_CN/l ...
- 网络爬虫入门:你的第一个爬虫项目(requests库)
0.采用requests库 虽然urllib库应用也很广泛,而且作为Python自带的库无需安装,但是大部分的现在python爬虫都应用requests库来处理复杂的http请求.requests库语 ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- python 操作excle 之第三方库 openpyxl学习
目录 python 操作excle 之第三方库 openpyxl学习 安装 pip install openpyxl 英文文档链接 : 点击这里~ 1,定位excel 2,读取excle中的内容 3, ...
- python爬虫之一:requests库
目录 安装requtests requests库的连接异常 HTTP协议 HTTP协议对资源的操作 requests库的7个主要方法 request方法 get方法 网络爬虫引发的问题 robots协 ...
- PYTHON 爬虫笔记三:Requests库的基本使用
知识点一:Requests的详解及其基本使用方法 什么是requests库 Requests库是用Python编写的,基于urllib,采用Apache2 Licensed开源协议的HTTP库,相比u ...
随机推荐
- N天学习一个Linux命令之dmesg
用途 显示系统自检信息和设备信息 用法 dmesg [-c] [-r] [-n level] [-s bufsize] 常用选项 选项 含义 说明 -c 输出ring buffer内容并且清空ring ...
- Openfire:访问Servlet时绕开Openfire的身份验证
假设有如下的场景,当我们开发一个允许Servlet访问的OF插件时,如果不需要身份验证的话,或者有其它的安全机制的话,我们会不希望每次都做一次OF的身份验证,而是能够直接访问Servlet.绕开身份验 ...
- jQuery和CSS3炫酷button点击波特效
这是一款效果很炫酷的jQuery和CSS3炫酷button点击波特效.该特效当用户在菜单button上点击的时候.从鼠标点击的点開始,会有一道光波以改点为原点向外辐射的动画效果,很绚丽. 在线演示:h ...
- 使用Memcached改进Java企业级应用性能:架构和设置
Memcached由Danga Interactive开发.用来提升LiveJournal.com站点性能. Memcached分布式架构支持众多的社交网络应用,Twitter.Facebook还有W ...
- ios 得用代理反向传值
应用场景:有时时候从界面A跳转到界面B,界面B在返回的时候须要将处理的结果传递给A. 实现思路:1,定义一个负责传值的协义,界面A拥有该协义属性,并实现该协义中的方法 2.界面B也拥有该协义属性(代理 ...
- winrar
winrar 破解方法 1.安装winrar试用版: 2.在winrar安装文件夹下新建一个文本文件,文件名为rarreg.key: 3.用记事本打开该文件,将下面内容复制到文件中,并存盘,搞定! R ...
- C# ListBox 左移、右移、上移、下移
C# ListBox 左移.右移.上移.下移 2012-11-17 22:53:45| 分类: 技术研讨 | 标签:listbox |字号 订阅 /// <summary> ...
- bzoj1699
st表 我还不会st表 f[i][j]表示[i,i+2^j)区间的最值 构造就像lca一样f[i][j]=f[i][j-1] f[i][j]=max(f[i][j-1],f[i+(1<<( ...
- word2vec改进之Hierarchical Softmax
首先Hierarchical Softmax是word2vec的一种改进方式,因为传统的word2vec需要巨大的计算量,所以该方法主要有两个改进点: 1. 对于从输入层到隐藏层的映射,没有采取神经网 ...
- 有关于dict(字典)的特性与操作方法
有关于dict(字典)的特性与操作方法 1.字典的特性 语法: dic = {key1 : value1,key2 : value2,key3 : value3............} 注:字典中k ...