storm集群安装配置
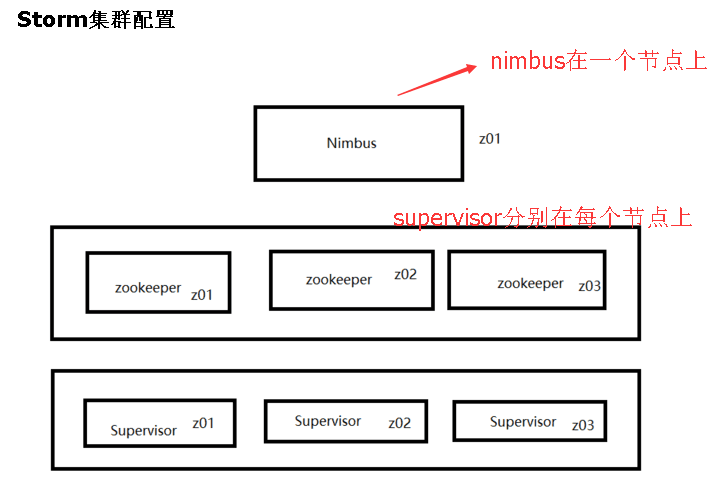
1.上传解压
2.进入到storm的conf目录

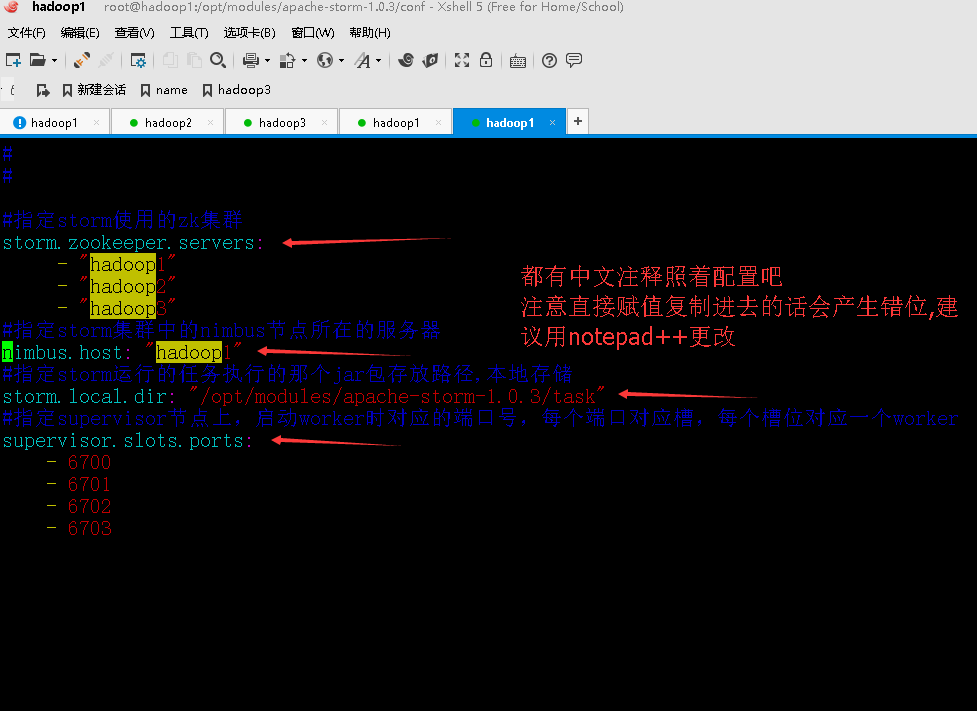
接上图
启动三台节点的zookeeper集群
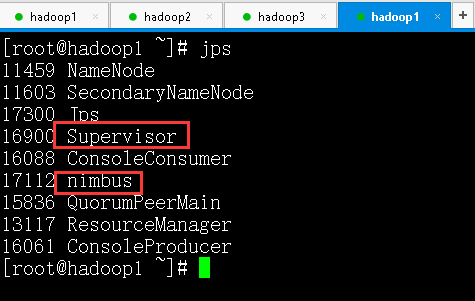
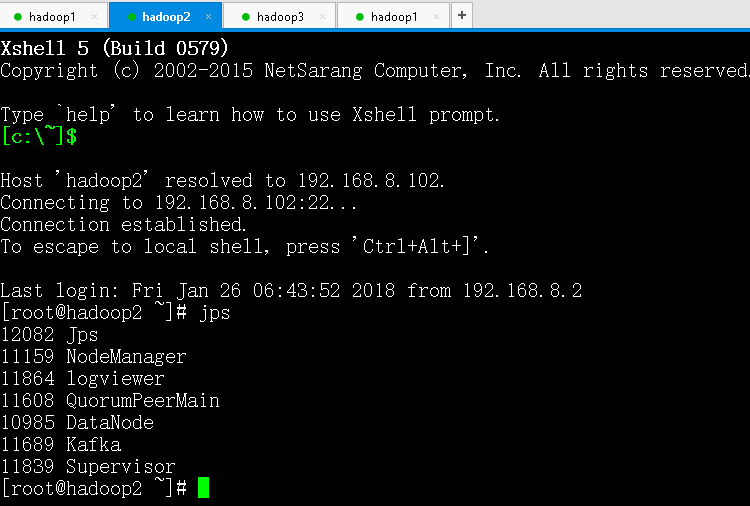
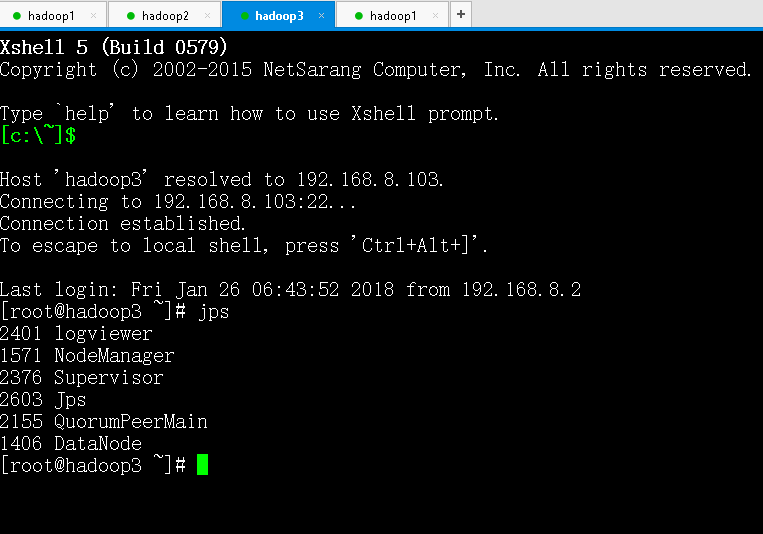
启动和查看 Storm
在 nimbus.host 所属的机器上启动 nimbus 服务和 logviewer 服务
storm nimbus &
storm logviewer &
在 nimbus.host 所属的机器上启动 ui 服务
storm ui &
在其它个点击上启动 supervisor 服务和 logviewer 服务
storm supervisor &
storm logviewer &
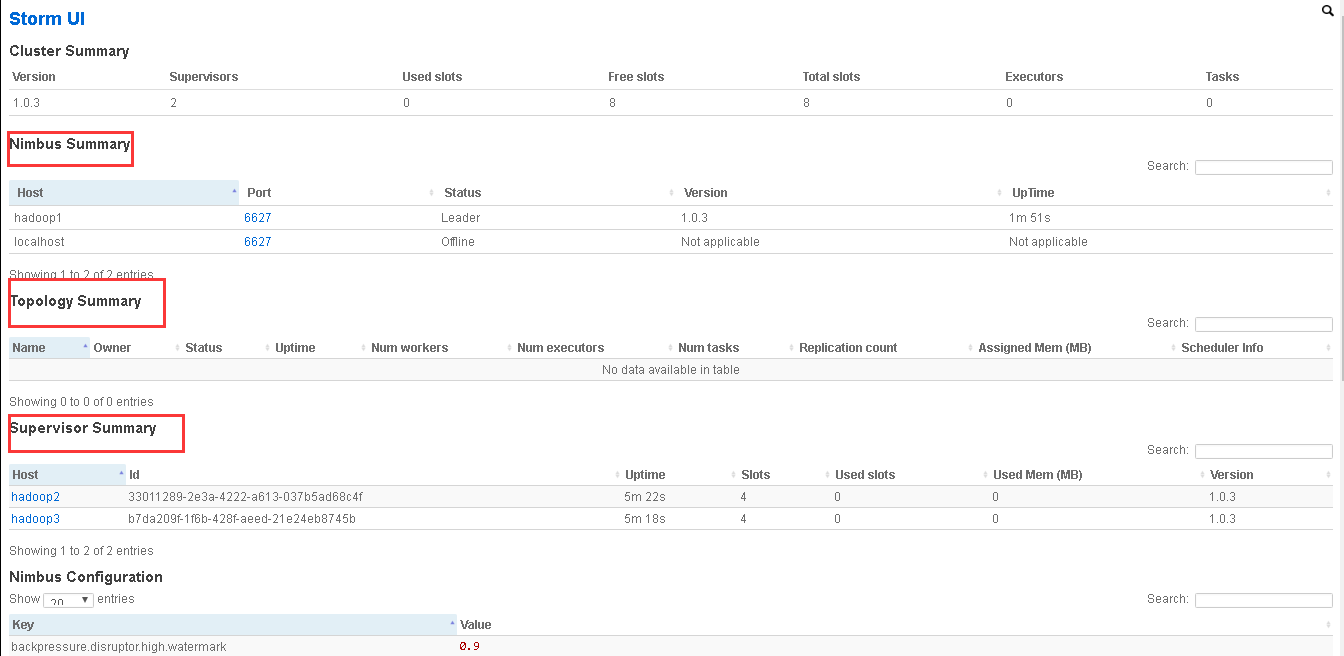
查看 storm 集群:访问 nimbus.host:/8081,即可看到 storm 的 ui 界面(好像默认端口是8080,我这里配置的8081)
Storm 的常用命令
有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡
拓扑。
1 提交任务命令格式:storm jar 【jar 路径】 【拓扑包名.拓扑类名】 【拓扑名称】
2 杀死任务命令格式:storm kill 【拓扑名称】 -w 10
(执行 kill 命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
3 停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
4 启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
5 重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的
集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,
并重启拓扑
运行个官方案例,测试一下吧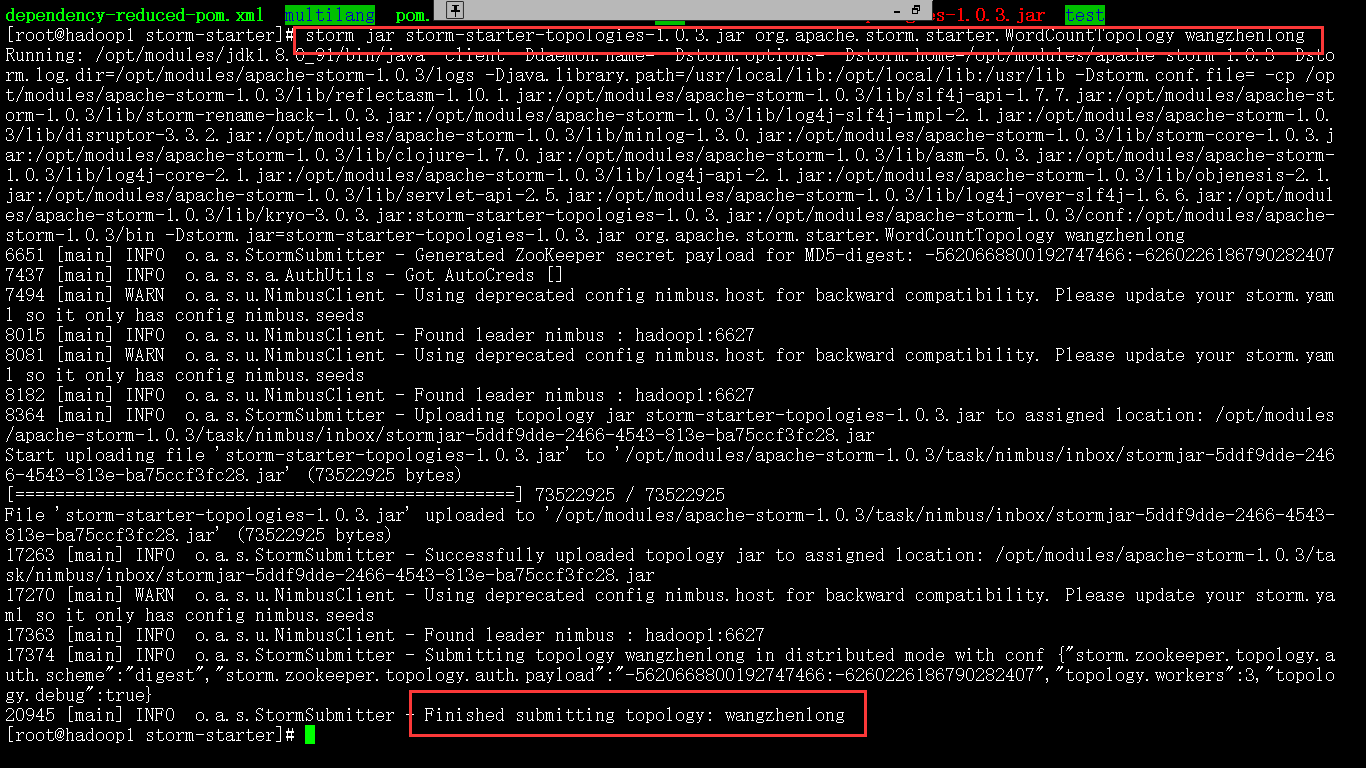
storm集群安装配置的更多相关文章
- Storm 集群安装配置
本文详细介绍了 Storm 集群的安装配置方法.如果需要在 AWS 上安装 Storm,你应该看一下 storm-deploy 项目.storm-deploy 可以自动完成 E2 上 Storm 集群 ...
- Storm集群安装详解
storm有两种操作模式: 本地模式和远程模式. 本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来; 远端模式:你提交的topology会在一个集群的机器 ...
- (Linux环境Kafka集群安装配置及常用命令
Linux环境Kafka集群安装配置及常用命令 Kafka 消息队列内部实现原理 Kafka架构 一.下载Kafka安装包 二.Kafka安装包的解压 三.设置环境变量 四.配置kafka文件 4.1 ...
- Storm集群安装Version1.0.1开启Kerberos
Storm集群安装,基于版本1.0.1, 同时开启Kerberos安全认证, 使用apache-storm-1.0.1.tar.gz安装包. 1.安装规划 角色规划 IP/机器名 安装软件 运行进程 ...
- Storm集群安装Version1.0.1
Storm集群安装,基于版本1.0.1, 使用apache-storm-1.0.1.tar.gz安装包. 1.安装规划 角色规划 IP/机器名 安装软件 运行进程 nimbus zdh-237 sto ...
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- hive集群安装配置
hive 是JAVA写的的一个数据仓库,依赖hadoop.没有安装hadoop的,请参考http://blog.csdn.net/lovemelovemycode/article/details/91 ...
- 集群安装配置Hadoop具体图解
集群安装配置Hadoop 集群节点:node4.node5.node6.node7.node8. 详细架构: node4 Namenode,secondnamenode,jobtracker node ...
随机推荐
- HDOJ 1874 畅通project续
畅通project续 Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- Codeforces 13C Sequence dp
题目链接:http://codeforces.com/problemset/problem/13/C 题意: 给定n长的序列 每次操作能够给每一个数++或-- 问最少须要几步操作使得序列变为非递减序列 ...
- 唯品会API网关设计与实践--转
原文地址:https://609518.kuaizhan.com/86/70/p4108366952248f 刘璟宇Leo 唯品会资深研发工程师,在大型高性能分布式系统设计和开发方面有丰富的经验.目前 ...
- (Spring+IBatis+Struts1+Struts2+Hibernate+Java EE+Oracle)
原文出处:http://space.itpub.net/6517/viewspace-609654 1.Spring架构图 Spring是一个开源框架,是为了解决企业应用程序开发复杂性而创建的.框架的 ...
- 3Ds Max制作克劳族少女教程
作者:Andrius Balciunas 使用软件:3ds Max, ZBrush 3ds Max下载:http://www.xy3dsmax.com/xiazai.html ZBrush下载:htt ...
- 优动漫PAINT简简单单绘画绣球花
本文分享使用优动漫PAINT简简单单绘画绣球花教程: 相关资讯还可以关注http://www.dongmansoft.com 最后告诉你绣球花的花语,还是很和谐美好的呢! 绣球花没有茉莉花的芳香四溢, ...
- CDR X6低价还能持续多久?官方回应18年元旦过后要涨价
目前,CDR X6特价活动,从双十二的到18年的元旦,火热程度一直屡刷新高,究其原因,其实不是大家不需要,只是这个平面设计软件价格实在太高(CDR X8/8200:CDR 2017/9500一套),尤 ...
- canvas图片滚动
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...
- iOS面试总结(待完善)
闲的没事总结一下面试资料,先列个大纲,然后慢慢填充,一步步完善,反正也不急. 1.基本属性 2.KVC与KVO 3.代理与block 4.多线程:NSThread,GCD,NSOperation 5. ...
- [HEOI2012]采花(树状数组+离线)
听说这题的所发和HH的项链很像. 然而那道题我使用莫队写的... 这是一个套路,pre数组加升维(在线). 记录一个\(pre\)数组,\(pre[i]\)代表上一个和i颜色相同的下标. 我们把询问离 ...