SSD-实现
一、制作voc数据集
1、数据集文件夹
新建一个文件夹,用来存放整个数据集,或者和voc2007一样的名字:VOC2007
然后像voc2007一样,在文件夹里面新建如下文件夹:
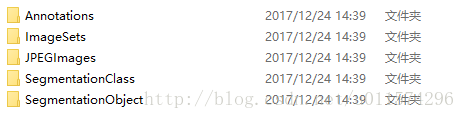
2、将训练图片放到JPEGImages
将所有的训练图片放到该文件夹里,然后将图片重命名为VOC2007的“000005.jpg”形式
图片重命名的代码(c++,python,matlab),参考:http://blog.csdn.net/u011574296/article/details/72956446
3、标注图片,标注文件保存到Annotations
使用labelIImg 标注自己的图片

每个图片和标注得到的xml文件,JPEGImages文件夹里面的一个训练图片,对应Annotations里面的一个同名XML文件,一 一 对应,命名一致
标注自己的图片的时候,类别名称请用小写字母,比如汽车使用car,不要用Car
pascal.py中读取.xml文件的类别标签的代码:
cls = self._class_to_ind[obj.find('name').text.lower().strip()]
写的只识别小写字母,如果你的标签含有大写字母,可能会出现KeyError的错误。
4、ImageSets\Main里的四个txt文件
在ImageSets里再新建文件夹,命名为Main,在Main文件夹中生成四个txt文件,即:

test.txt是测试集
train.txt是训练集
val.txt是验证集
trainval.txt是训练和验证集
VOC2007中,trainval大概是整个数据集的50%,test也大概是整个数据集的50%;train大概是trainval的50%,val大概是trainval的50%。
txt文件中的内容为样本图片的名字(不带后缀),格式如下:

根据已生成的xml,制作VOC2007数据集中的trainval.txt ; train.txt ; test.txt ; val.txt
trainval占总数据集的50%,test占总数据集的50%;train占trainval的50%,val占trainval的50%;
上面所占百分比可根据自己的数据集修改,如果数据集比较少,test和val可少一些
二、实现
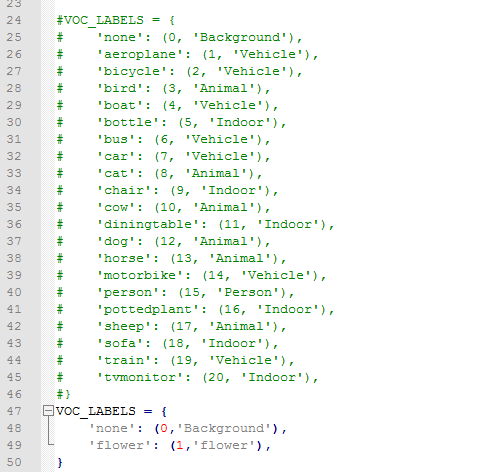
1、修改datasets文件夹中pascalvoc_common.py文件,将训练类修改别成自己的
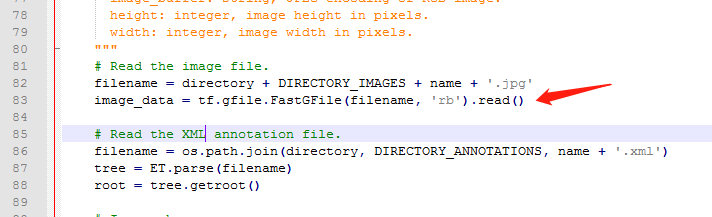
2、将图像数据转换为tfrecods格式,修改datasets文件夹中的pascalvoc_to_tfrecords.py文件,然后更改文件的83行读取方式为’rb‘,如果你的文件不是.jpg格式,也可以修改图片的类型。
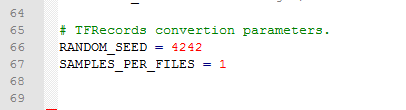
此外, 修改67行,可以修改几张图片转为一个tfrecords
3、运行tf_convert_data.py文件,但是需要传给它一些参数:
linux:
在SSD-Tensorflow-master文件夹下创建tf_conver_data.sh,文件写入内容如下:

windows+pycharm:
配置pycharm-->run-->Edit Configuration
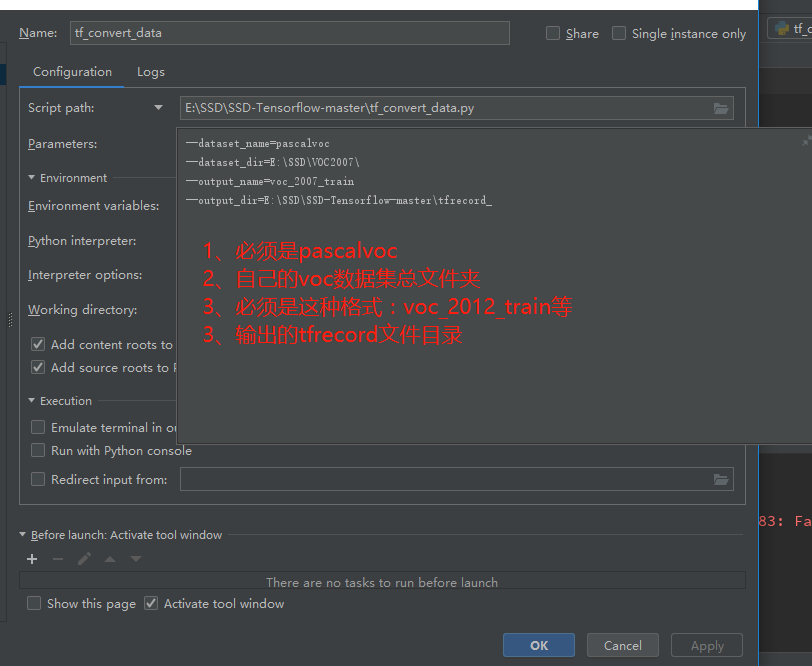
遇见的问题:
其他py文件import datasets文件时导入不了模块,导致读取不了,解决方法:设为source root

然后运行tf_convert_data.py
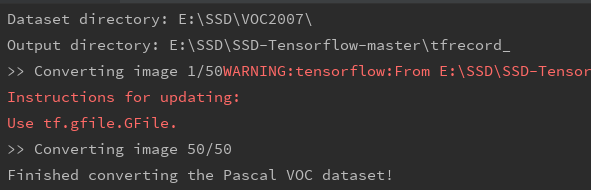
4、训练模型train_ssd_network.py文件中修改

train_ssd_network.py文件中网络参数配置,若需要改,在此文件中进行修改,如:

其他需要修改的地方
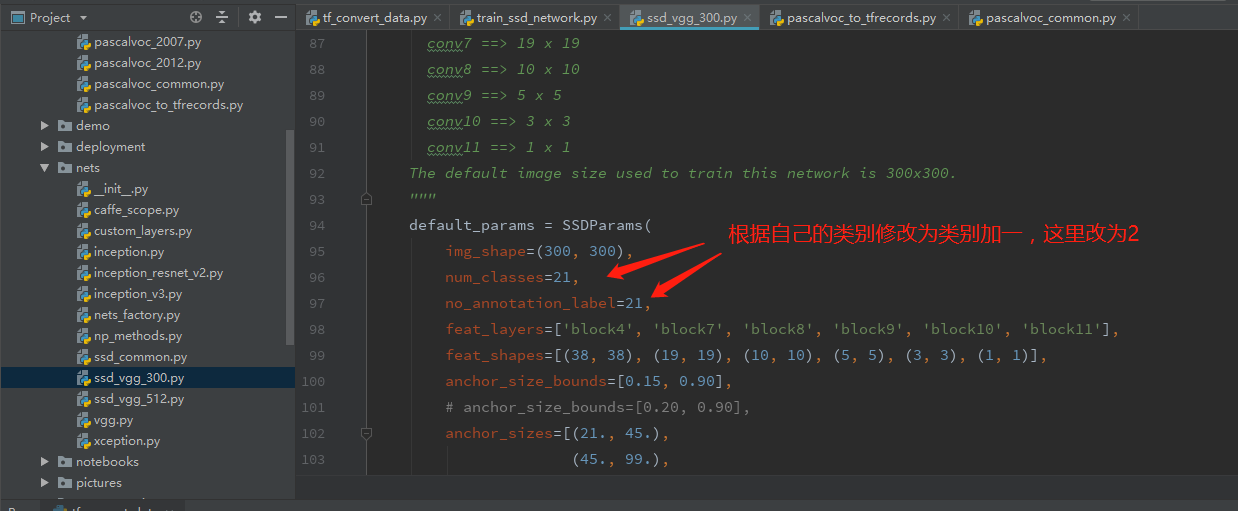
5、nets/ssd_vgg_300.py ,(因为使用此网络结构) ,修改96 和97行的类别
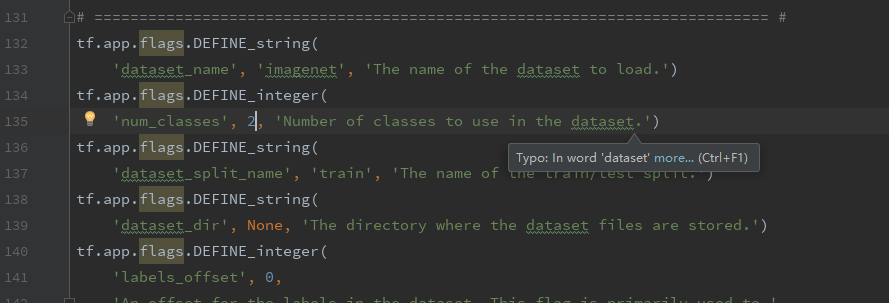
6、train_ssd_network.py
修改类别为2
7、 eval_ssd_network.py

8、datasets/pascalvoc_2007.py 根据自己的训练数据修改整个文件
SSD-Tensorflow-master/datasets/pascalvoc_2007.py文件中,none类不要动,其他类修改为自己数据集的类,其中括号内的第一个数为图片数,第二个数为目标数(bounding box的数目,total是所有类的总和)
# (Images, Objects) statistics on every class.
# TRAIN_STATISTICS = {
# 'none': (0, 0),
# 'aeroplane': (238, 306),
# 'bicycle': (243, 353),
# 'bird': (330, 486),
# 'boat': (181, 290),
# 'bottle': (244, 505),
# 'bus': (186, 229),
# 'car': (713, 1250),
# 'cat': (337, 376),
# 'chair': (445, 798),
# 'cow': (141, 259),
# 'diningtable': (200, 215),
# 'dog': (421, 510),
# 'horse': (287, 362),
# 'motorbike': (245, 339),
# 'person': (2008, 4690),
# 'pottedplant': (245, 514),
# 'sheep': (96, 257),
# 'sofa': (229, 248),
# 'train': (261, 297),
# 'tvmonitor': (256, 324),
# 'total': (5011, 12608),
# }
# TEST_STATISTICS = {
# 'none': (0, 0),
# 'aeroplane': (1, 1),
# 'bicycle': (1, 1),
# 'bird': (1, 1),
# 'boat': (1, 1),
# 'bottle': (1, 1),
# 'bus': (1, 1),
# 'car': (1, 1),
# 'cat': (1, 1),
# 'chair': (1, 1),
# 'cow': (1, 1),
# 'diningtable': (1, 1),
# 'dog': (1, 1),
# 'horse': (1, 1),
# 'motorbike': (1, 1),
# 'person': (1, 1),
# 'pottedplant': (1, 1),
# 'sheep': (1, 1),
# 'sofa': (1, 1),
# 'train': (1, 1),
# 'tvmonitor': (1, 1),
# 'total': (20, 20),
# }
# SPLITS_TO_SIZES = {
# 'train': 5011,
# 'test': 4952,
# }
# SPLITS_TO_STATISTICS = {
# 'train': TRAIN_STATISTICS,
# 'test': TEST_STATISTICS,
# }
# NUM_CLASSES = 20
TRAIN_STATISTICS = {
'none': (0, 0),
'flower': (40, 40),
'total': (40, 40),
}
TEST_STATISTICS = {
'none': (0, 0),
'flower': (10, 10),
'total': (10, 10)
}
SPLITS_TO_SIZES = {
'train': 40,
'test': 10,
}
SPLITS_TO_STATISTICS = {
'train': TRAIN_STATISTICS,
'test': TEST_STATISTICS,
}
NUM_CLASSES = 1 #不用加一
按照之前的方式,同样,如果你是linux用户,你可以新建一个.sh文件,文件里写入
DATASET_DIR=./tfrecords_/
TRAIN_DIR=./train_model/
CHECKPOINT_PATH=./checkpoints/vgg_16.ckpt python3 ./train_ssd_network.py \
--train_dir=./train_model/ \ #训练生成模型的存放路径
--dataset_dir=./tfrecords_/ \ #数据存放路径
--dataset_name=pascalvoc_2007 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=./checkpoints/vgg_16.ckpt \ #所加载模型的路径
--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=24 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
如果你是windows+pycharm中运行,除了在上述的run中Edit Configuration配置,你还可以打开Terminal,在这里运行代码,输入即可
python ./train_ssd_network.py --train_dir=./train_model/ --dataset_dir=./tfrecords_/ --dataset_name=pascalvoc_2007 --dataset_split_name=train --model_name=ssd_300_vgg --checkpoint_path=./checkpoints/vgg_16.ckpt --checkpoint_model_scope=vgg_16 --checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box --save_summaries_secs=60 --save_interval_secs=600 --weight_decay=0.0005 --optimizer=adam --learning_rate=0.001 --learning_rate_decay_factor=0.94 --batch_size=24 --gpu_memory_fraction=0.9
SSD-实现的更多相关文章
- SSD框架训练自己的数据集
SSD demo中详细介绍了如何在VOC数据集上使用SSD进行物体检测的训练和验证.本文介绍如何使用SSD实现对自己数据集的训练和验证过程,内容包括: 1 数据集的标注2 数据集的转换3 使用SSD如 ...
- 光驱SSD安装Win7+ubuntu系统双系统
准备条件: U盘,32GB,三星品牌 SSD,120GB,三星品牌 win7旗舰版,Ghost系统(安装简单嘛),Ylmf_Ghost_Win7_SP1_x64_2016_1011.iso ubunt ...
- 创建Azure DS 虚拟机并附加SSD硬盘
$subscriptionName = "Windows Azure Enterprise Trial" #订阅名称 $location = "China East&qu ...
- 关闭电脑SSD的磁盘碎片整理
小白往往会把机械硬盘时代的习惯带进固态硬盘时代,比如碎片整理.机械硬盘时代砖家最喜欢告诉小白:“系统慢了吧?赶紧碎片整理撒.”小白屁颠屁颠地整理去了.殊不知碎片整理对于SSD来说完全就是种折磨.这种“ ...
- SQL Server 2014新特性探秘(2)-SSD Buffer Pool Extension
简介 SQL Server 2014中另一个非常好的功能是,可以将SSD虚拟成内存的一部分,来供SQL Server数据页缓冲区使用.通过使用SSD来扩展Buffer-Pool,可以使得大量随 ...
- Macbook SSD硬盘空间不够用了?来个Xcode大瘦身吧!
原文转自:http://www.jianshu.com/p/03fed9a5fc63 日期:2016-04-22 最近突然发现我的128G SSD硬盘只剩下可怜的8G多,剩下这么少的一点空间连X ...
- 搭把手教美工妹妹如何通过升级SSD提升电脑性能
-----by LinHan 不单单适用于妹子,我这名的意思的妹子也能看懂. 以下教程依据实践和部分互联网资料总结得出,向博客园, CSDN的前辈们致谢:同时,如有说的不正确或有不到位的地方,麻烦指出 ...
- [archlinux][hardware] ThankPad T450自带SSD做bcache之后的使用寿命分析
这个分析的起因,是由于我之前干了这两个事: [troubleshoot][archlinux][bcache] 修改linux文件系统 / 分区方案 / 做混合硬盘 / 系统转生大!手!术!(调整底层 ...
- SSD Trim Support -- 保护 SSD
今天同事告诉我,换了 ssd 之后需要做以下配置能使 ssd 寿命更长.原理是配置系统定期清理和回收 ssd 的资源. 最终效果: 步骤: 1.下载 trim enabler: https://gis ...
- 目标检测方法——SSD
SSD论文阅读(Wei Liu--[ECCV2016]SSD Single Shot MultiBox Detector) 目录 作者及相关链接 文章的选择原因 方法概括 方法细节 相关背景补充 实验 ...
随机推荐
- 服务器共享session的方式
服务器共享session的方式 简介 1. 基于NFS的Session共享 NFS是Net FileSystem的简称,最早由Sun公司为解决Unix网络主机间的目录共享而研发.这个方案实现最为简单, ...
- CNN tflearn处理mnist图像识别代码解说——conv_2d参数解释,整个网络的训练,主要就是为了学那个卷积核啊。
官方参数解释: Convolution 2D tflearn.layers.conv.conv_2d (incoming, nb_filter, filter_size, strides=1, pad ...
- 去除iframe滚动条1
主页面的IFRAME中添加:scrolling="yes" 子页面程序代码: 让竖条消失: <body style='overflow:scroll;overflow-x:a ...
- HTTP报文头解析
HTTP报文头解析 本篇博客我们就来详细的聊一下HTTP协议的常用头部字段,当然我们将其分为请求头和响应头进行阐述.下方是报文头每个字段的格式,首先是头部字段的名称,如Accept,冒号后方紧跟的是该 ...
- C# 比较两个数据的不同
string[] arrRate = new string[] { "op1010", "op1020", "op1030", " ...
- 如何用一个app操作另外一个app.比如微信群控那样的
如何实现一个app.控制另外的app,比如市面上群控微信的,是用测试工具的原理?还是什么模拟点击的原理? 如何用一个app操作另外一个app.比如微信群控那样的 >> android这个答 ...
- SpringCloud学习笔记(12)----Spring Cloud Netflix之Hystrix断路器的流程和原理
工作流程(参考:https://github.com/Netflix/Hystrix/wiki/How-it-Works) 1. 创建一个HystrixCommand或HystrixObservabl ...
- SpringBoot学习笔记(1)----环境搭建与Hello World
简介: Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程.该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配 ...
- jquery 遍历 table 下所有得tr td
$("#middle").contents().find("tbody tr").each(function(i,n){ var child = $(this) ...
- keepalive安装配置
安装 Centos7.4 yum install keepalived 配置 Master服务器配置 [root@wsjy-proxy01 keepalived]# cat keepalived.co ...