NameNode机制和DataNode机制
首先我们看一下NAMENODE:
我们已经知道了NAMENODE作为DATANODE的管理者,其重要性不言而喻,那么NAMENODE是怎么管理数据的呢?

首先,我们看一下上面这张图,每次客户端读写数据都要先经过NAMENODE,其实就是先查询NAMENODE中的元数据,那么问题来了,NAMENODE中的元数据究竟是存在内存中还是存在硬盘中呢?如果存在内存中,一旦断电就意味着数据的丢失;但是存在硬盘中,读写速度必然下降。下面将对其细节进行详尽的阐述。

通过看以上这幅图,我们可以看到NAMENODE中的元数据既存在在内存中,也存在在硬盘中。我们先看一下元数据的存储细节:
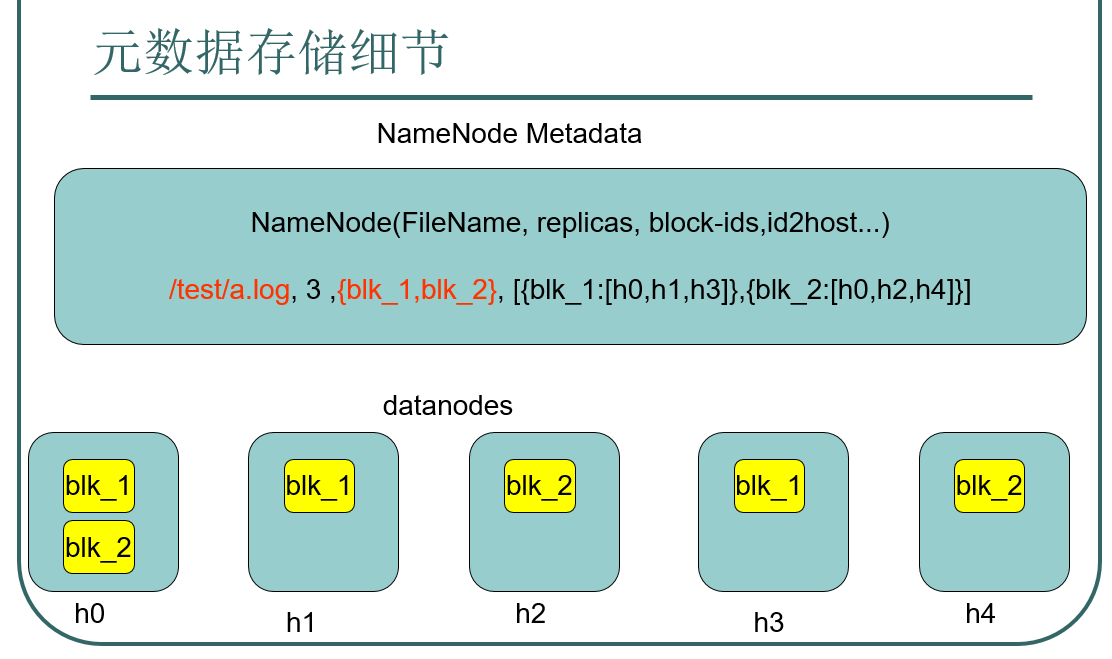
从左到右依次是存储路径,有哪些副本,每个副本在哪些主机上面存储。NAMENODE是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表,接受用户的操作请求。
文件包括:
1.fsimage:元数据镜像文件,存储某一时段NAMENODE内存元数据信息。
2.edits:操作日志文件。
3.fstime:保存最近一次checkpoint的时间。
现在我们回到上一幅图,
1.NAMENODE始终在内存中保存meta.data,用于处理“读请求”。
2.到有“写请求”到来时,NAMENODE会首先写edits到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回。
3.Hadoop会维护一个fsimage文件,也就是namenode中meta.data的镜像,但是fsimage不会随时与NAMENODE内存中的meta.data保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary NAMENODE就是用来合并fsimage和edits文件来更新NAMENODE的meta.data的。
这里就用到了Secondary NAMENODE,我们再来看一张图:
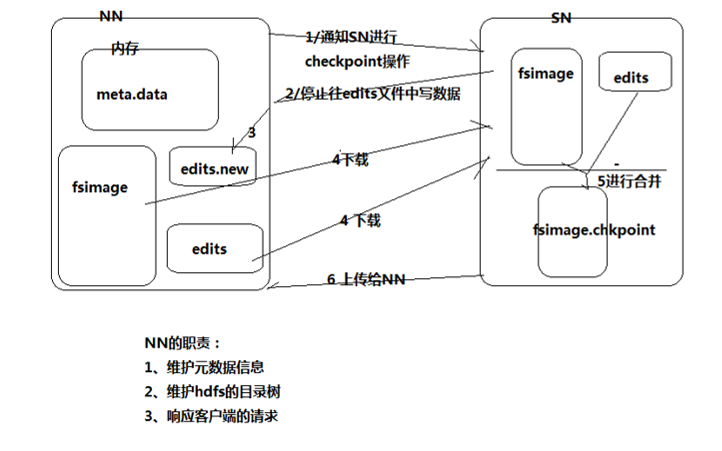
在这张图中,我们可以看到SN的一些作用,当NN通知SN要进行checkpoint操作的时候,NN就停止向edits日志中写数据了,但是写操作又不能停止,这时候就会向一个edits.new日志文件中写数据,而SN会把fsimage和edits里面的内容下载到SN中,在SN中进行合并,说白了,就是将日志格式转化成要存储的文件格式,产生fsimage.chkpoint文件,并将它上传给NN,替换fsimage,并且重命名成fsimage,同时edits.new替换edits,并且重命名成edits。详细过程就是:

那么什么时候checkpoint呢?有两种判别方式:
1.fs.checkpoint.period:指定两次checkpoint的最大时间间隔,默认是3600秒。
2.fs.checkpoint.size:规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否达到最大时间间隔。默认大小是64M。
两种判定方式先达到哪个判定条件,则先采用哪个。
我们再来看一下DATANODE:
DataNode
提供真实文件数据的存储服务
文件块:最基本的存储单位,对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移,按照固定的大小,顺序对文件进行划分并编号。划分好的每一块称为一个Block,默认Block的大小是128M。开始不同于普通文件系统的是HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。datanode与namenode保存心跳机制,当长时间未向namenode报告,则视为该datanode死机,namenode会重新备份该datanode上的数据块。
读程图:
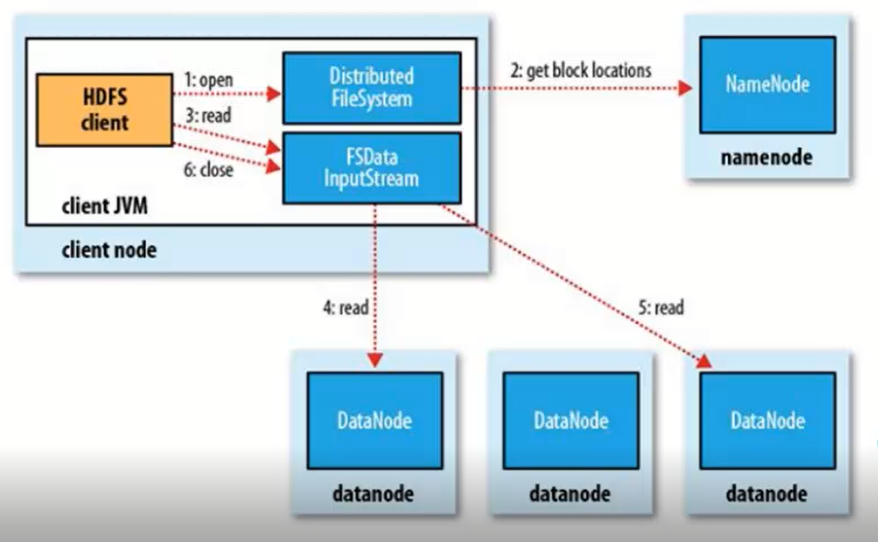
1、客户端发送请求,调用DistributedFileSystem API的open方法发送请求到Namenode,获得block的位置信息,因为真正的block是存在Datanode节点上的,而namenode里存放了block位置信息的元数据。
2、Namenode返回所有block的位置信息,并将这些信息返回给客户端。
3、客户端拿到block的位置信息后调用FSDataInputStream API的read方法并行的读取block信息,图中4和5流程是并发的,block默认有3个副本,所以每一个block只需要从一个副本读取就可以。
4、datanode返回给客户端。
写流程:

1、客户端发送请求,调用DistributedFileSystem API的create方法去请求namenode,并告诉namenode上传文件的文件名、文件大小、文件拥有者。
2、namenode根据以上信息算出文件需要切成多少块block,以及block要存放在哪个datanode上,并将这些信息返回给客户端。
3、客户端调用FSDataInputStream API的write方法首先将其中一个block写在datanode上,每一个block默认都有3个副本,并不是由客户端分别往3个datanode上写3份,而是由
已经上传了block的datanode产生新的线程,由这个namenode按照放置副本规则往其它datanode写副本,这样的优势就是快。
4、写完后返回给客户端一个信息,然后客户端在将信息反馈给namenode。
5、需要注意的是上传文件的拥有者就是客户端上传文件的用户名,举个例子用windows客户端上传文件,那么这个文件的拥有者就是administrator,和linux上的系统用户名不是一样的。
补充:
我们在文件系统写内容,其实也是先在日志中写,然后同步到内存,接着返回写入成功,内存中的内容会在达到阈值后写入到磁盘中。
推荐这篇文章:
NameNode机制和DataNode机制的更多相关文章
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- hadoop及NameNode和SecondaryNameNode工作机制
hadoop及NameNode和SecondaryNameNode工作机制 1.hadoop组成 Common MapReduce Yarn HDFS (1)HDFS namenode:存放目录,最重 ...
- 【Hadoop】HDFS笔记(二):HDFS的HA机制和Federation机制
HA解决了HDFS的NameNode的单点问题: Federation解决了整个HDFS集群中只有一个名字空间,并且只有单独的一个NameNode管理所有DataNode的问题. 一.HA机制(Hig ...
- Atitit.事件机制 与 消息机制的联系与区别
Atitit.事件机制 与 消息机制的联系与区别 1. 消息/事件机制是几乎所有开发语言都有的机制,在某些语言称之为消息(Event),有些地方称之为(Message).1 2. 发布/订阅模式1 3 ...
- cookie机制和session机制的原理和区别[转]
一.cookie机制和session机制的区别 具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案. 同时我们也看到,由于在服务器端保持状态的 ...
- Linux内核学习笔记3——分段机制和分页机制
一 分段机制 1.什么是分段机制 分段机制就是把虚拟地址空间中的虚拟内存组织成一些长度可变的称为段的内存块单元. 2.什么是段 每个段由三个参数定义:段基地址.段限长和段属性. 段的基地址.段限长以及 ...
- cookie机制和session机制的区别(面试题)
一.cookie机制和session机制的区别 具体来说cookie机制采用的是在客户端保持状态的方案,而session机制采用的是在服务器端保持状态的方案. 同时我们也看到,由于才服务器端保持状态的 ...
- ActiveMQ讯息传送机制以及ACK机制
http://blog.csdn.net/lulongzhou_llz/article/details/42270113 ActiveMQ消息传送机制以及ACK机制详解 AcitveMQ是作为一种消息 ...
- 浅谈java编译机制和运行机制
源文件和字节码的组成方式 源文件: 拓展名后跟java的文件即java的源文件. Java 源码编译由以下三个过程组成: 1.分析和输入到符号表 2.注解处理 3.语义分析和生成class文件 流程图 ...
随机推荐
- 河流Shader
原地址:http://www.unity蛮牛.com/blog-2321-336.html Shader "Custom/TextureEffect" { Properties { ...
- Codeforces Round #FF (Div. 1)-A,B,C
A:DZY Loves Sequences 一開始看错题了. .sad. 题目非常easy.做法也非常easy.DP一下就好了. dp[i][0]:到当前位置,没有不论什么数改变,得到的长度. dp[ ...
- mysql c语言 动态链接库
下载地址 https://dev.mysql.com/downloads/connector/c/ 使用libmysql.lib和libmysql.dll进行操作mysql
- TP框架中如何使用SESSION限制登录?
TP框架中如何使用SESSION限制登录? 之前总是被问题今天才明白,最高效的来做页面访问限制问题. OOP思想中的继承特性,实现验证,是否已经登录,不必每个页面都进行判断. 实现如下: 继承Cont ...
- 用记事本编写一个Servlet项目
第一步:建立目录 新建一个文件夹FirstServlet,然后在FirstServlet目录下面再建两个文件夹,分别为:WEB-INF和src.最后在WEB-INF下面建一个classes文件夹 第二 ...
- 滚动居中效果(frame版)
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Makefile之写demo时的通用Makefile写法
Makefile之写demo时的通用Makefile写法[日期:2013-05-22] 来源:CSDN 作者:gqb666 [字体:大 中 小] 前面的一篇文章Makefile之大型工程项目子目录M ...
- ubuntu 14.04为/检查磁盘时发生严重错误的解决方法
http://jingyan.baidu.com/article/0aa22375bbffbe88cc0d6419.html
- ubuntu 命令行下查看网页 w3m
w3m localhost/index.php
- android 实现代码混淆
对于使用签名的apk,经常使用的反编译之后还是能查看class文件的代码实现.对于反编译可查看个人的博客点击打开链接 使用代码混淆就能是这样的常规反编译失效.很多其它混淆机制见官网http://dev ...