tensorflowxun训练自己的数据集之从tfrecords读取数据
当训练数据量较小时,采用直接读取文件的方式,当训练数据量非常大时,直接读取文件的方式太耗内存,这时应采用高效的读取方法,读取tfrecords文件,这其实是一种二进制文件。tensorflow为其内置了各种存储和读取的函数,方便调用。
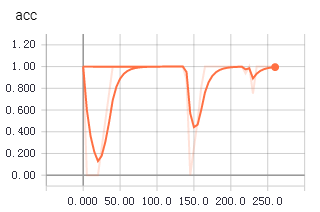
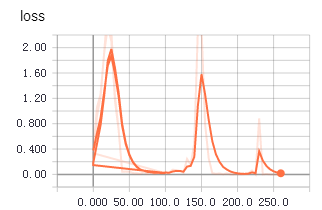
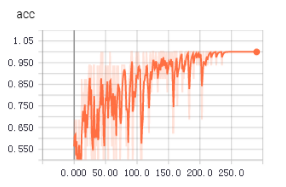
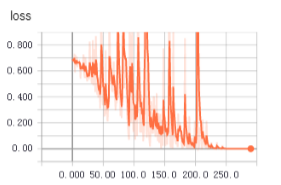
不知道为啥,从tfrecords中读取数据用于训练时,收敛得更快,更平稳。上面两个图是使用tfrecords的准确率和loss值变化,下面是直接读取文件的准确率和loss值变化。
1 生成记录样本的记录文件
root_dir = os.getcwd() def getTrianList():
with open("train.txt","w") as f:
for file in os.listdir(root_dir+'\\dataSet'):
for picFile in os.listdir(root_dir+"\\dataSet\\"+file):
f.write("dataSet/"+file+"/"+picFile+" "+file+"\n")
print(picFile)
if __name__=="__main__":
getTrianList()
将样本文件路径和标签统一记录到一个txt中,后面生成tfrecords文件就是通过读取这些信息。
注意文件路径和标签之间采用空格,不要使用制表符。
2 读取txt存于数组中
def load_file(example_list_file):
lines = np.genfromtxt(example_list_file,delimiter=" ",dtype=[('col1', 'S120'), ('col2', 'i8')])
examples = []
labels = []
for example,label in lines:
examples.append(example)
labels.append(label)
#convert to numpy array
return np.asarray(examples),np.asarray(labels),len(lines)
这段代码主要用来读取第1步生成的txt,将文件路径和标签存于数组中
3 读取图片
def extract_image(filename,height,width):
print(filename)
image = cv2.imread(filename)
image = cv2.resize(image,(height,width))
b,g,r = cv2.split(image)
rgb_image = cv2.merge([r,g,b])
return rgb_image
使用cv2读取图片文件
4 转化为tfrecords文件
def trans2tfRecord(trainFile,name,output_dir,height,width):
if not os.path.exists(output_dir) or os.path.isfile(output_dir):
os.makedirs(output_dir)
_examples,_labels,examples_num = load_file(train_file)
filename = name + '.tfrecords'
writer = tf.python_io.TFRecordWriter(filename)
for i,[example,label] in enumerate(zip(_examples,_labels)):
print("NO{}".format(i))
#need to convert the example(bytes) to utf-8
example = example.decode("UTF-8")
image = extract_image(example,height,width)
image_raw = image.tostring()
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw':_bytes_feature(image_raw),
'height':_int64_feature(image.shape[0]),
'width': _int64_feature(32),
'depth': _int64_feature(32),
'label': _int64_feature(label)
}))
writer.write(example.SerializeToString())
writer.close()
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value])) def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
5 从tfrecords中读取训练数据
def read_tfRecord(file_tfRecord):
queue = tf.train.string_input_producer([file_tfRecord])
reader = tf.TFRecordReader()
_,serialized_example = reader.read(queue)
features = tf.parse_single_example(
serialized_example,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'height': tf.FixedLenFeature([], tf.int64),
'width':tf.FixedLenFeature([], tf.int64),
'depth': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64)
}
)
image = tf.decode_raw(features['image_raw'],tf.uint8)
#height = tf.cast(features['height'], tf.int64)
#width = tf.cast(features['width'], tf.int64)
image = tf.reshape(image,[32,32,3])
image = tf.cast(image, tf.float32)
image = tf.image.per_image_standardization(image)
label = tf.cast(features['label'], tf.int64)
print(image,label)
return image,label
从tfrecords文件中读取image和label,训练的时候,直接使用tf.train.batch函数生成用于训练的batch即可。
image_batches,label_batches = tf.train.batch([image, label], batch_size=16, capacity=20)
其余的部分跟之前的训练步骤一样。
tensorflowxun训练自己的数据集之从tfrecords读取数据的更多相关文章
- TensorFlow学习笔记——LeNet-5(训练自己的数据集)
在之前的TensorFlow学习笔记——图像识别与卷积神经网络(链接:请点击我)中了解了一下经典的卷积神经网络模型LeNet模型.那其实之前学习了别人的代码实现了LeNet网络对MNIST数据集的训练 ...
- Fast RCNN 训练自己的数据集(3训练和检测)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https://github.com/YihangLou/fas ...
- 【faster-rcnn】训练自己的数据集时的坑
既然faster-rcnn原版发表时候是matlab版代码,那就用matlab版代码吧!不过遇到的坑挺多的,不知道python版会不会好一点. ======= update ========= 总体上 ...
- 【Tensorflow系列】使用Inception_resnet_v2训练自己的数据集并用Tensorboard监控
[写在前面] 用Tensorflow(TF)已实现好的卷积神经网络(CNN)模型来训练自己的数据集,验证目前较成熟模型在不同数据集上的准确度,如Inception_V3, VGG16,Inceptio ...
- 目标检测算法SSD之训练自己的数据集
目标检测算法SSD之训练自己的数据集 prerequesties 预备知识/前提条件 下载和配置了最新SSD代码 git clone https://github.com/weiliu89/caffe ...
- 可变卷积Deforable ConvNet 迁移训练自己的数据集 MXNet框架 GPU版
[引言] 最近在用可变卷积的rfcn 模型迁移训练自己的数据集, MSRA官方使用的MXNet框架 环境搭建及配置:http://www.cnblogs.com/andre-ma/p/8867031. ...
- caffe训练自己的数据集
默认caffe已经编译好了,并且编译好了pycaffe 1 数据准备 首先准备训练和测试数据集,这里准备两类数据,分别放在文件夹0和文件夹1中(之所以使用0和1命名数据类别,是因为方便标注数据类别,直 ...
- 使用yolo3模型训练自己的数据集
使用yolo3模型训练自己的数据集 本项目地址:https://github.com/Cw-zero/Retrain-yolo3 一.运行环境 1. Ubuntu16.04. 2. TensorFlo ...
- 【tf.keras】在 cifar 上训练 AlexNet,数据集过大导致 OOM
cifar-10 每张图片的大小为 32×32,而 AlexNet 要求图片的输入是 224×224(也有说 227×227 的,这是 224×224 的图片进行大小为 2 的 zero paddin ...
随机推荐
- Woody的Python学习笔记3
Python运算符 Python逻辑运算符 and布尔与-假设x为false.x and y返回false,否则它返回y的计算值. or 布尔或-假设x是true,它返回true.否则它返回y的计算值 ...
- 论坛模块_版块管理_增删改查&实现上下移动
论坛模块_版块管理1_增删改查 设计实体Forum.java public class Forum { private Long id; private String name; private St ...
- ios开发之 -- 5分钟集成融云的客服功能
最近项目中遇到了客服的功能,首先想到的就是使用融云的功能,因为以前做的即时通讯的项目,用的都是融云的sdk,花了点时间研究了下,希望能帮到大家! 废话不多说,步骤如下: 一.申请融云账号 二.创建应用 ...
- [Go语言]从Docker源码学习Go——Interfaces
Interface定义: type Namer interface { Method1(param_list) return_type Method2(param_list) return_type ...
- JZOJ.5289【NOIP2017模拟8.17】偷笑
Description berber走进机房,边敲门边喊:“我是哔哔”CRAZY转过头:“我警告你,哔哔刚刚来过!”“呵呵呵呵……”这时,哔哔站了起来,环顾四周:“你们笑什么?……”巧了,发出笑声的人 ...
- Django学习笔记第三篇--关于响应返回
一.返回简单类型: #1.返回简单字符串 #from django.http import HttpResponse return HttpResponse("return string&q ...
- 『AngularJS』一点小小的理解
AngularJS 是一个前端的以Javascript为主的MVC框架.与AngularJS相类似的还有EmberJS. 随着时代在进步,各种各样的开发理念与开发框架不断的提出与发展,而就目前来说,除 ...
- Markdown安装与简单使用
早就听过Markdown的大名了,说是最适合程序员的编辑器,一点也不为过.平时写文章,写博客.除了内容以外,还要被一堆繁琐的样式困扰,毕竟样式太难看,既是自己的文章,也会懒得看的.今天正好看到博客上面 ...
- node jar sh
https://nodejs.org/api/child_process.html Node.js v11.1.0 Documentation Index View on single page Vi ...
- nodejs(三)上之express
express 简介 Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具. 使用 Express 可以快速 ...