Python中正则匹配使用findall时的注意事项
在使用正则搜索内容时遇到一个小坑,百度搜了一下,遇到这个坑的还不少,特此记录一下。
比如说有一个字符串 "123@qq.comaaa@163.combbb@126.comasdf111@asdfcom"
想匹配出里面所有的邮箱地址,该怎么实现呢?
写了个正则,测试一下:
>>> import re
>>> s = "123@qq.comaaa@163.combbb@126.comasdf111@asdfcom"
>>> pattern1 = "\w+@(qq|163|126)\.com"
>>> m1 = re.search(pattern1,s)
>>> m1.group()
'123@qq.com'
可以看到,能够正确搜索到第一个结果,正则写得没问题,如果我想得到所有结果,自然而然就想到了用findall()方法。来试试看:
>>> m2 = re.findall(pattern1,s)
>>> m2
['qq', '163', '126']
这时候估计很多人就觉得奇怪了,使用search方法能搜索到,说明正则写得没问题呀,为什么使用findall的时候结果是这个样子的?为什么结果不是整个邮箱字符串?
查了资料才清楚一个概念,叫做捕获分组。
简单说,就是正则表示式里出现括号的时候,括号里的内容匹配到的部分是会被作为结果输出的,而不是把整个正则表达式匹配到的内容作为结果输出。
所以,就出现了上面的结果了。
那怎么得到想要的结果呢?在Python里,当一个分组的头部出现"?:"时,表示这是一个非捕获分组,意思就是它只是正常参与匹配过程,但不作为独立的结果进行输出。
那么按这个写法来试试:
>>> pattern2 = "\w+@(?:qq|163|126)\.com"
>>> m2 = re.findall(pattern2,s)
>>> m2
['123@qq.com', 'aaa@163.com', 'bbb@126.com']
取消了这个捕获分组,那么就是把整个表达式作为一个结果输出,这样才是我们预期想要的效果。
这种情况在使用正则中的“或”匹配时是特别需要注意的,因为这时候通常会加括号,很多初学者很容易掉进这个坑,得到一个不知所谓的结果。
当然,捕获分组这个功能本来是正常有用的,只是要用对了才行。
比如,同样是刚才这个例子,如果只想要邮箱中的用户名部分,该怎么写正则表达式呢?
显然就是把用户名部分加括号作为一个捕获分组就可以了。
>>> pattern3 = "(\w+)@(?:qq|163|126)\.com"
>>> m3 = re.findall(pattern3,s)
>>> m3
['123', 'aaa', 'bbb']
对于findall()函数,其帮助是这么说明的:
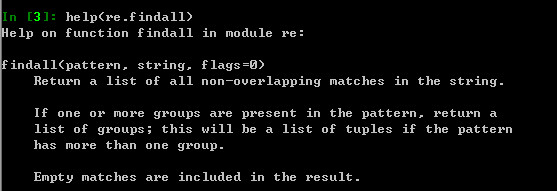
findall函数,就是说在正则匹配里,如果有分组,就仅仅匹配分组里面的内容,然后返回这个组的列表; 如果有多个分组,那就把每一个分组看成一个单位,组合为一个元组,然后返回一个含有多个元组的列表。
分组这个功能还是比较强大的,以后会继续学习更多的部分。
参考文章:https://blog.csdn.net/qq_42739440/article/details/81117919
Python中正则匹配使用findall时的注意事项的更多相关文章
- Python中正则匹配使用findall,捕获分组(xxx)和非捕获分组(?:xxx)的差异
转自:https://blog.csdn.net/qq_42739440/article/details/81117919 下面是我在用findall匹配字符串时遇到的一个坑,分享出来供大家跳坑. 例 ...
- python中正则匹配之re模块
Python中正则表达式 re:re是提供正则表达式匹配操作的模块 一.什么是正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某个模式匹配,Python 自1.5版本起 ...
- 在python中使用print()时,raw write()返回无效的长度:OSError: raw write() returned invalid length 254 (should have been between 0 and 127)
写出一个不是code的bug,很烦恼,解决了挺长时间,都翻到外文来看,不过还是解决了,只尝试了一种简单可观的方法,希望对大家有用 我正在使用Django与Keras(tensorflow)来训练一个模 ...
- python - 手机号正则匹配
Python 手机号正则匹配 # -*- coding:utf-8 -*- import re def is_phone(phone): phone_pat = re.compile('^(13\d| ...
- Python中正则模块re.compile、re.match及re.search函数用法
import rehelp(re.compile)'''输出结果为:Help on function compile in module re: compile(pattern, flags=0) C ...
- 关于php中正则匹配包括换行符在内的任意字符的问题总结
要使用正则匹配任意字符的话,通常有以下几种方法,这里我分别对每一种方法在使用的过程中做一个总结: 第一种方式:[.\n]*? 示例 ? PHP preg_match_all('/<div cla ...
- python re 正则匹配 split sub
import re 编译: motif='([ST])Q' seq="SQAAAATQ" regrex=re.compile(motif) #编译成正则对象 regrex=re.c ...
- html中正则匹配img
1.正则匹配html中的img标签,取出img的url并进行图片文件下载: /// <summary> /// 将image标签的src属性的url替换为base64 /// </s ...
- python - re正则匹配模块
re模块 re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. re ...
随机推荐
- 【Python】selenium调用IE11浏览器,报错“找不到元素”NoSuchWindowException: Message:Unable to find element on closed window
当编写自动化脚本,定位浏览器元素时,报如下错误: 代码: >>> # coding=utf-8 >>> from selenium import webdriver ...
- java eclipse使用不同jdk版本
因为开发需要,两个工程分别需要使用jdk1.6(elipse indigo)和jdk1.8(eclipse neon).因为两个eclipse对于jdk版本的要求不同,若只在环境变量中配置jdk版本, ...
- 018 nginx与第三模块整合[一致性哈希模块整合]
nginx第三方模块官网:http://wiki.nginx.org/HttpUpstreamConsistentHash nginx第三方模块下载地址:https://github.com/repl ...
- PowerBuilder -- Tab控件
在tab中关闭窗口 Close(tab_1.getparent()) 调整tab中的控件的tab oder 鼠标右键tabpage_1,选择 Tab Order菜单.
- MongoDB安装配置(Windows)
官网下载:https://www.mongodb.com/ 百度经验:https://jingyan.baidu.com/article/d5c4b52bef7268da560dc5f8.html 官 ...
- php如何在原来的时间上加一天?一小时?
<?php echo "今天:",date('Y-m-d H:i:s'),"<br>"; echo "明天:",date( ...
- 2017-2018-1 20179209《Linux内核原理与分析》第二周作业
本周课业主要通过分析汇编代码执行情况掌握栈的变化.本人本科时期学过intel 80X86汇编语言,所以有一定基础:在Linux中32位AT&T风格的汇编稍微熟悉就可以明白.所以我学习的重点放在 ...
- Oozie-1-安装、配置 让Hadoop流动起来
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/wl101yjx/article/details/27881739 写在前面一: 本文总结 基于Had ...
- Java for LeetCode 106 Construct Binary Tree from Inorder and Postorder Traversal
Construct Binary Tree from Inorder and Postorder Traversal Total Accepted: 31041 Total Submissions: ...
- VMware和Centos系统安装
1.Linux发行版的选择 2.vmware创建一个虚拟机(centos) 3.安装配置centos7 4.xshell配置连接虚拟机(centos) 选择性 pc可以选择 -纯系统 Linux/wi ...