solr配置中文分词器
配置IK分词器
- 在
/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib目录中加入IK分词器的jar包 - 在
/opt/solr-7.7.1/server/solr/article_core/conf文件夹下的 managed-schema文件中配置IK中文分词器- 在managed-schema文件中配置ik分词器的配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
</fieldType>
*测试分词效果
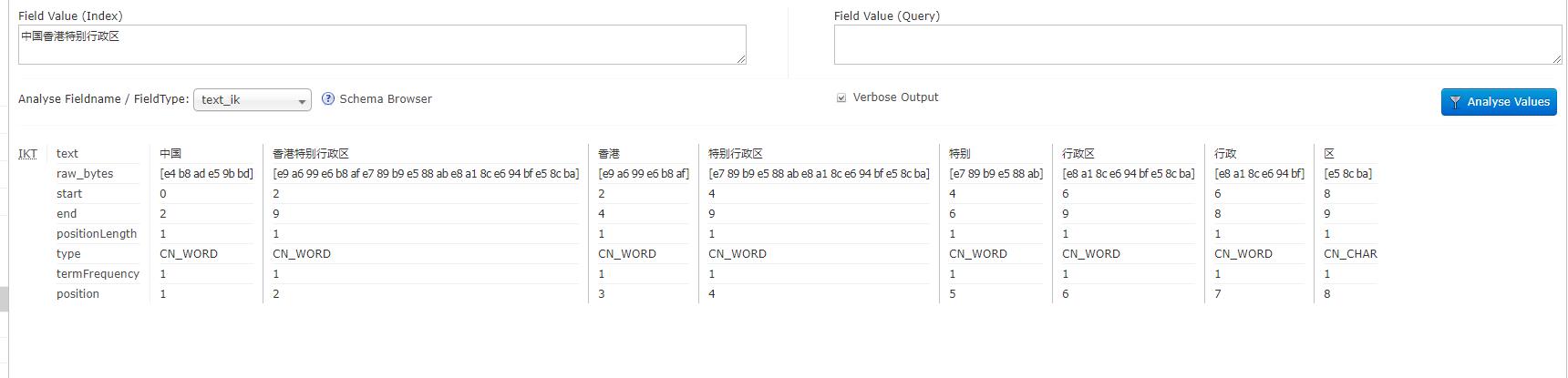
* 配置停用词 扩展词 同义词
停止词 的功能是过滤,把“啊”加入到停止词的字典里,比如搜索“你好啊”,solr会过滤掉“啊”,以“你好”去搜索。应该叫过滤词才好。
扩展词 的功能是强制让扩展词字典里的词不被中文分词器分开,叫它自定义词也好理解。
同义词:搜索结果里出现的同义词。如我们输入”还行”,得到的结果包括同义词”还可以”(需修改IK源码,IK同义词暂没实现)。
在`/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/`文件夹下创建classes文件夹
加入
`IKAnalyzer.cfg.xml`
`ext.dic`
` stopword.dic`
三个文件,在stopword.dic中配置你的停用词 ext.dic中配置自定义扩展词
* 在ext.dic中定义小米手机自定义扩展词后 对`小米手机`四个字分词的对比
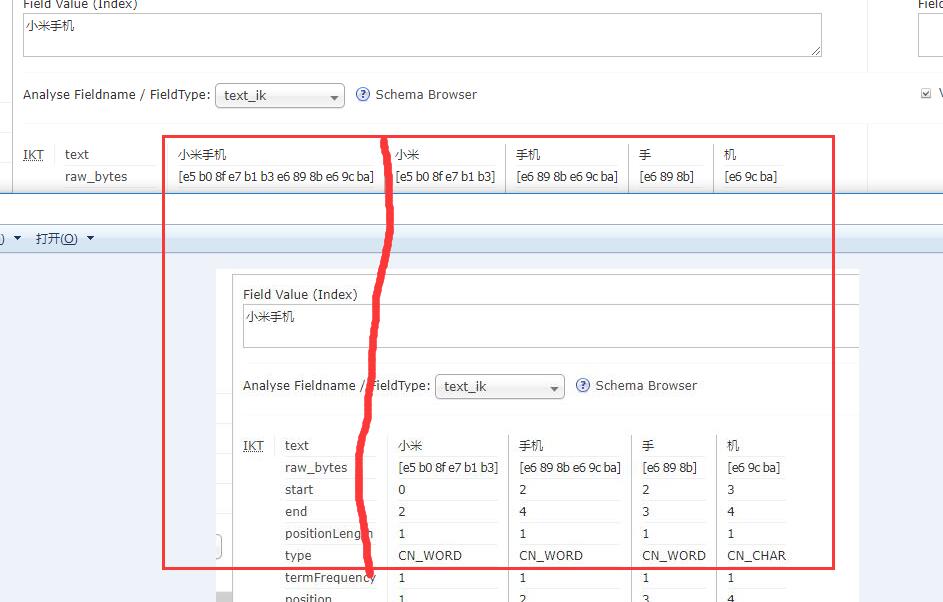
上面为自定义`小米手机`扩展词的分词效果,下面为没有定义扩展词的效果
配置smartcn中文分词器
复制
/opt/solr-7.7.1/contrib/analysis-extras/lucene-libs中的lucene-analyzers-smartcn-7.7.1.jar
至/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib中编辑managed-schema文件加入
<!-- 配置smartcn分词器 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
- 测试分词效果
不推荐使用该分词器
solr配置中文分词器的更多相关文章
- Solr 配置中文分词器 IK
1. 下载或者编译 IK 分词器的 jar 包文件,然后放入 ...\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib\ 这个 lib 文件目录下: IK 分 ...
- 给Solr配置中文分词器
第一步下载分词器https://pan.baidu.com/s/1X8v65YZ4gIkNQXsXfSULBw 第二歩打开已经解压的ik分词器文件夹 将ik-analyzer-solr5-5.x.ja ...
- solr配置中文分词器——(十二)
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAqcAAAGzCAIAAACdKClDAAAgAElEQVR4nOydd5gUxdbGx5xASZKXLB
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- 5.Solr4.10.3中配置中文分词器
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.下载IK Analyzer 2012FF_hf1.zip并上传到/home/test 2.按照如下命令安装 ...
- solr8.2 环境搭建 配置中文分词器 ik-analyzer-solr8 详细步骤
一.下载安装Apache Solr 8.2.0 下载地址:http://lucene.apache.org/solr/downloads.html 因为是部署部署在windows系统上,所以下载zip ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
随机推荐
- P4878 道路修建-美国
http://www.tyvj.cn/p/4878道路修建 我想我经大神点拨后终于明白了...回学校再写吧 时间限制:1s 内存限制:256MB [问题描述] A国是一个商业高度发达的国家.它包含了n ...
- Mybatis 使用注解和Provider类实现动态条件查询
1.注解内拼写 Mybatis SQL 脚本 @Repository public interface CustomerFeedMapper extends BaseCrudMapper<Cus ...
- spring boot Filter过滤器的简单使用
springboot使用Filter过滤器有两种方式: 一种是实现Filter接口然后通过@Component注解向项目加入过滤器 另一种是通过配置类来配置过滤器 @Component public ...
- 基于名称的虚拟主机-Apache
基于名称的虚拟主机和基于IP的虚拟主机的对比 基于IP的虚拟主机使用连接的IP地址来识别(区分)正确的虚拟主机,所以对于每一个虚拟主机,你都需要有独立的IP地址. 基于名称的虚拟主机,服务器依赖于客户 ...
- 零基础逆向工程22_PE结构06_导入表
导入表结构 typedef struct _IMAGE_IMPORT_DESCRIPTOR { union { DWORD Characteristics; DWORD OriginalFirstTh ...
- keil下JLINK在线调试仿真设置,SWD连接
keil下JLINK在线调试仿真设置,以下三个步骤搞定: 有时我们编译时会遇到空间不足的情况,首先我们应该把 flash和RAM的size 设置为当前所用芯片的大小,如下我使用了一个片上flash 2 ...
- c/c++的const和static区别
C语言中的const和static用来修饰变量或者函数,用const修饰表示不可改变,用static修饰表示变量或者函数是静态的,作用域控制在函数内. const定义的常量在超出其作用域之后其空间会被 ...
- Python3中requests库学习01(常见请求示例)
1.请求携带参数的方式1.带数据的post data=字典对象2.带header的post headers=字典对象3.带json的post json=json对象4.带参数的post params= ...
- GWTDesigner_v5.1.0破解码
GWTDesigner_v5.1.0_win32_x86.exe破解码,双击运行keygeno.jar,然后输入用户名.网卡MAC,然后单击Generate,将生成的文件放在C:\Documents ...
- UVA 1149 Bin Packing 装箱(贪心)
每次选最大的物品和最小的物品放一起,如果放不下,大物体孤独终生,否则相伴而行... 答案变得更优是因为两个物品一起放了,最大的物品是最难匹配的,如果和最小的都放不下的话,和其它匹配也一定放不下了. # ...