solr配置中文分词器
配置IK分词器
- 在
/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib目录中加入IK分词器的jar包 - 在
/opt/solr-7.7.1/server/solr/article_core/conf文件夹下的 managed-schema文件中配置IK中文分词器- 在managed-schema文件中配置ik分词器的配置
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
<analyzer type="query" class="org.wltea.analyzer.lucene.IKAnalyzer" useSmart="false"/>
</fieldType>
*测试分词效果
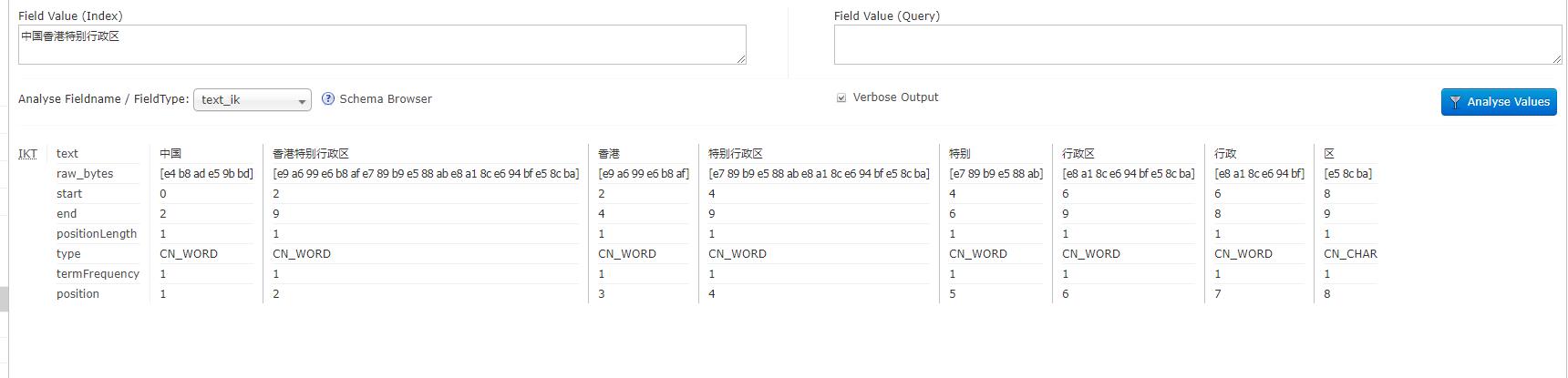
* 配置停用词 扩展词 同义词
停止词 的功能是过滤,把“啊”加入到停止词的字典里,比如搜索“你好啊”,solr会过滤掉“啊”,以“你好”去搜索。应该叫过滤词才好。
扩展词 的功能是强制让扩展词字典里的词不被中文分词器分开,叫它自定义词也好理解。
同义词:搜索结果里出现的同义词。如我们输入”还行”,得到的结果包括同义词”还可以”(需修改IK源码,IK同义词暂没实现)。
在`/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/`文件夹下创建classes文件夹
加入
`IKAnalyzer.cfg.xml`
`ext.dic`
` stopword.dic`
三个文件,在stopword.dic中配置你的停用词 ext.dic中配置自定义扩展词
* 在ext.dic中定义小米手机自定义扩展词后 对`小米手机`四个字分词的对比
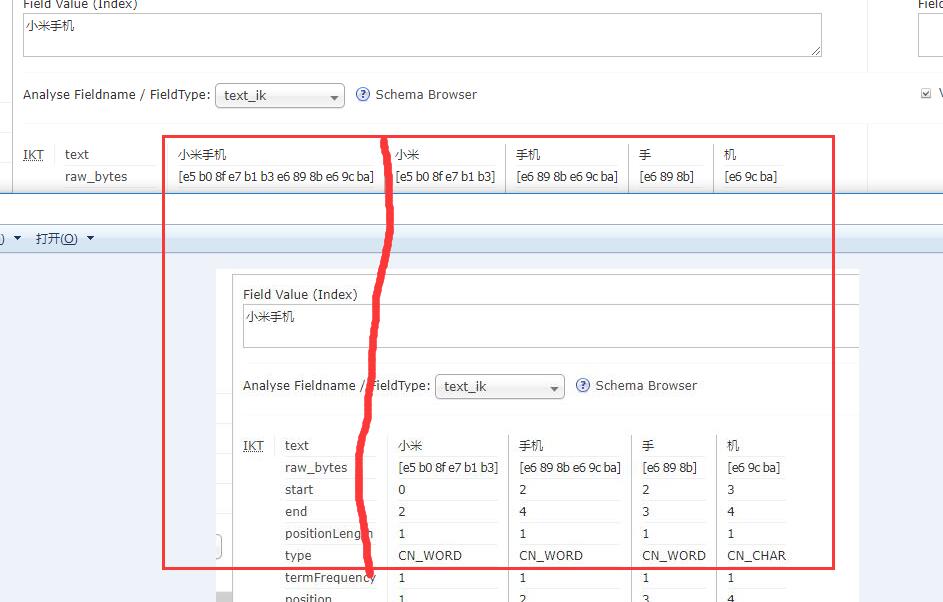
上面为自定义`小米手机`扩展词的分词效果,下面为没有定义扩展词的效果
配置smartcn中文分词器
复制
/opt/solr-7.7.1/contrib/analysis-extras/lucene-libs中的lucene-analyzers-smartcn-7.7.1.jar
至/opt/solr-7.7.1/server/solr-webapp/webapp/WEB-INF/lib中编辑managed-schema文件加入
<!-- 配置smartcn分词器 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
- 测试分词效果
不推荐使用该分词器
solr配置中文分词器的更多相关文章
- Solr 配置中文分词器 IK
1. 下载或者编译 IK 分词器的 jar 包文件,然后放入 ...\apache-tomcat-8.5.16\webapps\solr\WEB-INF\lib\ 这个 lib 文件目录下: IK 分 ...
- 给Solr配置中文分词器
第一步下载分词器https://pan.baidu.com/s/1X8v65YZ4gIkNQXsXfSULBw 第二歩打开已经解压的ik分词器文件夹 将ik-analyzer-solr5-5.x.ja ...
- solr配置中文分词器——(十二)
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAqcAAAGzCAIAAACdKClDAAAgAElEQVR4nOydd5gUxdbGx5xASZKXLB
- Solr6.5配置中文分词器
Solr作为搜索应用服务器,我们在使用过程中,不可避免的要使用中文搜索.以下介绍solr自带的中文分词器和第三方分词器IKAnalyzer. 注:下面操作在Linux下执行,所添加的配置在windo ...
- 5.Solr4.10.3中配置中文分词器
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 1.下载IK Analyzer 2012FF_hf1.zip并上传到/home/test 2.按照如下命令安装 ...
- solr8.2 环境搭建 配置中文分词器 ik-analyzer-solr8 详细步骤
一.下载安装Apache Solr 8.2.0 下载地址:http://lucene.apache.org/solr/downloads.html 因为是部署部署在windows系统上,所以下载zip ...
- ElasticSearch搜索引擎安装配置中文分词器IK插件
近几篇ElasticSearch系列: 1.阿里云服务器Linux系统安装配置ElasticSearch搜索引擎 2.Linux系统中ElasticSearch搜索引擎安装配置Head插件 3.Ela ...
- 我与solr(六)--solr6.0配置中文分词器IK Analyzer
转自:http://blog.csdn.net/linzhiqiang0316/article/details/51554217,表示感谢. 由于前面没有设置分词器,以至于查询的结果出入比较大,并且无 ...
- 转:solr6.0配置中文分词器IK Analyzer
solr6.0中进行中文分词器IK Analyzer的配置和solr低版本中最大不同点在于IK Analyzer中jar包的引用.一般的IK分词jar包都是不能用的,因为IK分词中传统的jar不支持s ...
随机推荐
- 使用CSS3的translate和transition功能,控制一个两个div块的联动
之前的工作有接触到一些css3的新特性.div块的移动和回到初始位置,可以利用在开发中的很多地方.这里记录下来,下次就不用辛苦的灾区百度了. <html> <head> < ...
- spring boot 事务
spring事务:默认自动提交只读:@Transactional(readOnly = true)读写:@Transactional(),因为等同于@Transactional(readOnly = ...
- NET Core:部署项目到Ubuntu Server
NET Core:部署项目到Ubuntu Server 概述 基于上一篇成功安装Ubuntu Server 16.10的基础上,接下来继续我们ASP.NET Core项目的部署之旅! 只是对于这些年整 ...
- memcache和iptables开启11211端口
linux下安装完memcached后,netstat -ant | grep LISTEN 看到memcache用的11211端口已在监听状态,但建立php文件连接测试发现没有输出结果,iptabl ...
- nodejs 实践:express 最佳实践(八) egg.js 框架的优缺点
nodejs 实践:express 最佳实践(八) egg.js 框架的优缺点 优点 所有的 web开发的点都考虑到了 agent 很有特色 文件夹规划到位 扩展能力优秀 缺点 最大的问题在于: 使用 ...
- vue-cli3脚手架的配置以及使用
Vue CLI 是一个基于 Vue.js 进行快速开发的完整系统,提供: 通过 @vue/cli 搭建交互式的项目脚手架. 通过 @vue/cli + @vue/cli-service-global ...
- iOS VIPER架构(二)
第一篇文章对VIPER进行了简单的介绍,这篇文章将从VIPER的源头开始,比较现有的几种VIPER实现,对VIPER进行进一步的职责剖析,并对各种细节实现问题进行挖掘和探讨.最后给出两个完整的VIPE ...
- Uncaught exception 'PDOException' with message 'SQLSTATE[HY000] [2002] No such file or directory解决方法
今天用pdo连接mysql遇到一个奇怪的问题,host设为127.0.0.1可以连接成功,设为localhost就会报如下的错误: PHP Fatal error: Uncaught excepti ...
- C#解析 json格式
C# 解析 json JSON(全称为JavaScript Object Notation) 是一种轻量级的数据交换格式.它是基于JavaScript语法标准的一个子集. JSON采用完全独立于语言的 ...
- UWP开发:存储容器设置&复合设置数据
有时候为了将应用设置进行分类,需要创建新的容器进行存储应用设置的信息. 1,容器的创建:在一个根容器里嵌套一个新容器 1)首先获取根容器. 2)调用ApplicationDataContainer.C ...