BlockCanary原理解析
一、背景
为了解决应卡顿,分析耗时。
二、原理
Looper中的loop方法:
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
可以看到在执行消息的时候,如果有设置logging,那么它会在消息开始与结束的时候打印出相关信息。如果主线程卡住了,就是在dispatchMessage这里卡住,所以我们可以通过计算这两条log的时间差来判断消息的执行时间。
我们可以通过这个方法来设置Printer。
Looper.getMainLooper().setMessageLogging(mainLooperPrinter);
三、源码解析
application中调用初始化:
BlockCanary.install(this, AppBlockCanaryContext()).start()
最终会执行到:
private BlockCanary() {
BlockCanaryInternals.setContext(BlockCanaryContext.get());
mBlockCanaryCore = BlockCanaryInternals.getInstance();
mBlockCanaryCore.addBlockInterceptor(BlockCanaryContext.get());
if (!BlockCanaryContext.get().displayNotification()) {
return;
}
mBlockCanaryCore.addBlockInterceptor(new DisplayService());
}
核心就是mBlockCanaryCore = BlockCanaryInternals.getInstance();它会对BlockCanaryInternals进行初始化。
public BlockCanaryInternals() {
stackSampler = new StackSampler(
Looper.getMainLooper().getThread(),
sContext.provideDumpInterval());
cpuSampler = new CpuSampler(sContext.provideDumpInterval());
setMonitor(new LooperMonitor(new LooperMonitor.BlockListener() {
@Override
public void onBlockEvent(long realTimeStart, long realTimeEnd,
long threadTimeStart, long threadTimeEnd) {
// Get recent thread-stack entries and cpu usage
ArrayList<String> threadStackEntries = stackSampler
.getThreadStackEntries(realTimeStart, realTimeEnd);
if (!threadStackEntries.isEmpty()) {
BlockInfo blockInfo = BlockInfo.newInstance()
.setMainThreadTimeCost(realTimeStart, realTimeEnd, threadTimeStart, threadTimeEnd)
.setCpuBusyFlag(cpuSampler.isCpuBusy(realTimeStart, realTimeEnd))
.setRecentCpuRate(cpuSampler.getCpuRateInfo())
.setThreadStackEntries(threadStackEntries)
.flushString();
LogWriter.save(blockInfo.toString());
if (mInterceptorChain.size() != 0) {
for (BlockInterceptor interceptor : mInterceptorChain) {
interceptor.onBlock(getContext().provideContext(), blockInfo);
}
}
}
}
}, getContext().provideBlockThreshold(), getContext().stopWhenDebugging()));
LogWriter.cleanObsolete();
}
- stackSampler:记录栈相关信息
- cpuSampler:记录CPU相关信息
- LooperMonitor:继承Printer
private void setMonitor(LooperMonitor looperPrinter) {
monitor = looperPrinter;
}
当我们调用BlockCanary的start方法的时候,便将其设给了Looper的printer,然后我们便可以在LooperMonitor的print方法里面去记录打印的log的时间。
public void start() {
if (!mMonitorStarted) {
mMonitorStarted = true;
Looper.getMainLooper().setMessageLogging(mBlockCanaryCore.monitor);
}
}
核心代码:
@Override
public void println(String x) {
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump();
}
}
在开始执行消息的时候去记录相关信息,结束消息的时候停止记录相关信息,并且判断消息执行的时间是否超过了我们设置的阈值,超过了的话便执行notifyBlockEvent(endTime);取出记录的相关消息提示用户。
说到此处,想到是不是可以用mainLooperPrinter来做更多事情呢?既然主线程都在这里,那只要parse出app包名的第一行,每次打印出来,是不是就不需要打点也能记录出用户操作路径? 再者,比如想做onClick到页面创建后的耗时统计,是不是也能用这个原理呢? 之后可以试试看这个思路(目前存在问题是获取线程堆栈是定时3秒取一次的,很可能一些比较快的方法操作一下子完成了没法在stacktrace里面反映出来)。
我们看一下怎么记录栈以及cpu的消息的。
private void startDump() {
if (null != BlockCanaryInternals.getInstance().stackSampler) {
BlockCanaryInternals.getInstance().stackSampler.start();
}
if (null != BlockCanaryInternals.getInstance().cpuSampler) {
BlockCanaryInternals.getInstance().cpuSampler.start();
}
}
StackSampler与CpuSampler都继承与AbstractSampler:
AbstractSampler里面的start方法:
public void start() {
if (mShouldSample.get()) {
return;
}
mShouldSample.set(true);
HandlerThreadFactory.getTimerThreadHandler().removeCallbacks(mRunnable);
HandlerThreadFactory.getTimerThreadHandler().postDelayed(mRunnable,
BlockCanaryInternals.getInstance().getSampleDelay());
}
private Runnable mRunnable = new Runnable() {
@Override
public void run() {
doSample();
if (mShouldSample.get()) {
HandlerThreadFactory.getTimerThreadHandler()
.postDelayed(mRunnable, mSampleInterval);
}
}
};
long getSampleDelay() {
return (long) (BlockCanaryInternals.getContext().provideBlockThreshold() * 0.8f);
}
它其实是开了一个子线程每隔一定的时间就去记录。
四、流程图
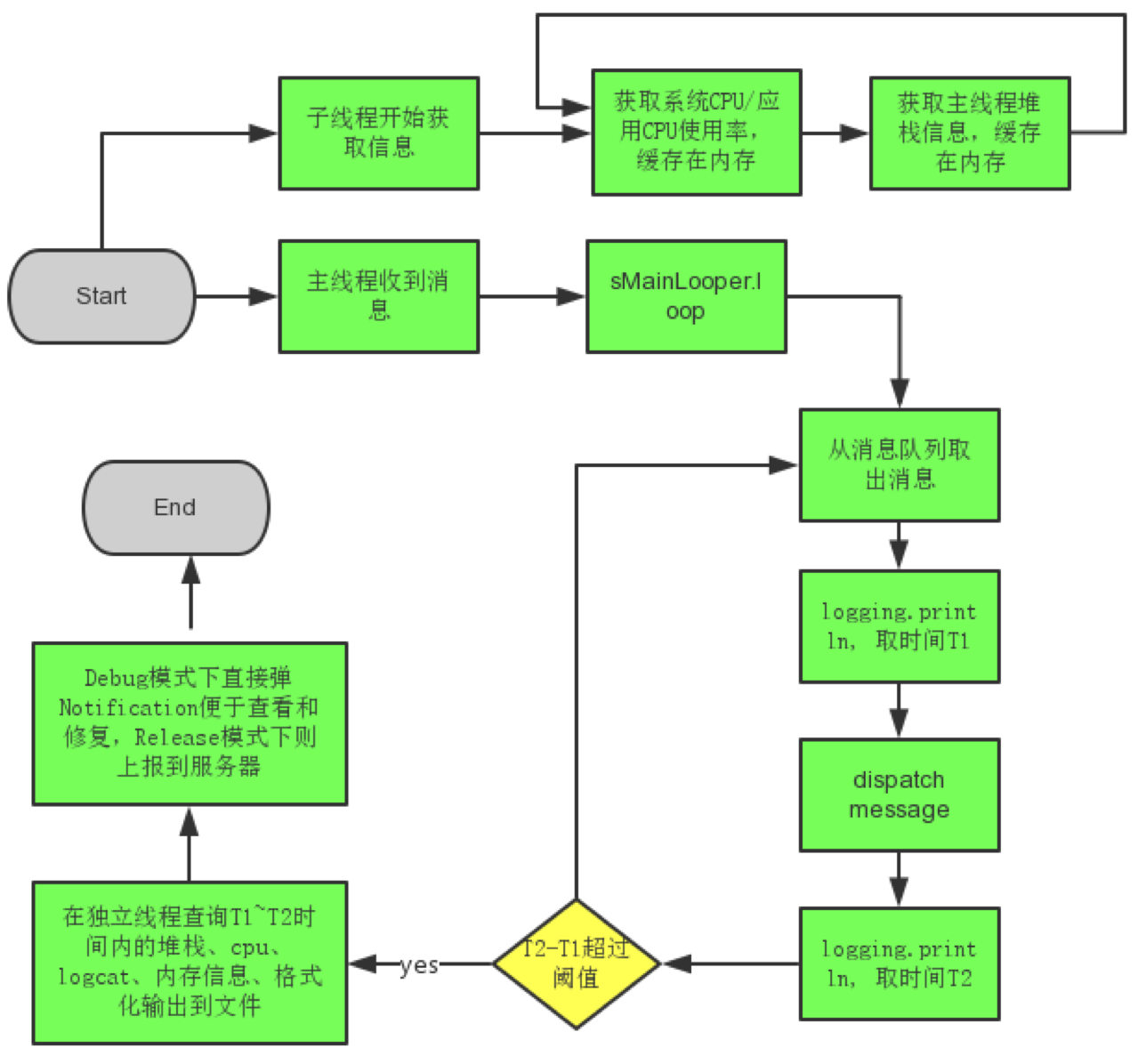
五、总结
BlockCanary作为一个Android组件,目前还有局限性,因为其在一个完整的监控系统中只是一个生产者,还需要对应的消费者去分析日志,比如归类排序,以便看出哪些卡慢更有修复价值,需要优先处理;又比如需要过滤机型,有些奇葩机型的问题造成的卡慢,到底要不要去修复是要斟酌的。扯远一点的话,像是埋点除了统计外,完全还能用来做链路监控,比如一个完整的流程是A -> B -> D -> E, 但是某个时间节点突然A -> B -> D后没有到达E,这时候监控平台就可以发出预警,让开发人员及时定位。很多监控方案都需要C/S两端的配合。
BlockCanary原理解析的更多相关文章
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- Web APi之过滤器创建过程原理解析【一】(十)
前言 Web API的简单流程就是从请求到执行到Action并最终作出响应,但是在这个过程有一把[筛子],那就是过滤器Filter,在从请求到Action这整个流程中使用Filter来进行相应的处理从 ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- alibaba-dexposed 原理解析
alibaba-dexposed 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49821413 原理参考地址: htt ...
- 支付宝Andfix 原理解析
支付宝Andfix 原理解析 使用参考地址: http://blog.csdn.net/qxs965266509/article/details/49802429 原理参考地址: http://blo ...
- JavaScript 模板引擎实现原理解析
1.入门实例 首先我们来看一个简单模板: <script type="template" id="template"> <h2> < ...
- Request 接收参数乱码原理解析三:实例分析
通过前面两篇<Request 接收参数乱码原理解析一:服务器端解码原理>和<Request 接收参数乱码原理解析二:浏览器端编码原理>,了解了服务器和浏览器编码解码的原理,接下 ...
- Request 接收参数乱码原理解析二:浏览器端编码原理
上一篇<Request 接收参数乱码原理解析一:服务器端解码原理>,分析了服务器端解码的过程,那么浏览器是根据什么编码的呢? 1. 浏览器解码 浏览器根据服务器页面响应Header中的“C ...
随机推荐
- 运行在容器中Postgres数据库数据损坏后如何恢复?
前言 在使用 K8S 部署 RSS 全套自托管解决方案- RssHub + Tiny Tiny Rss, 我介绍了将 RssHub + Tiny Tiny RSS 部署到 K8s 集群中的方案. 其中 ...
- 文心一言 VS 讯飞星火 VS chatgpt (110)-- 算法导论10.2 1题
一.用go语言,单链表上的动态集合操作 INSERT 能否在 O(1)时间内实现?DELETE 操作呢? 文心一言: 在单链表中,INSERT 和 DELETE 操作的时间复杂度通常是 O(n),其中 ...
- 2020/5/8—cf,我裂开来
呜呜呜我爆零了呜呜呜ljll 嗯T1T2防爆零的没了呜呜呜在此纪念可怜的yjz大佬21发AC 太惨了(逃 先来说说我们都有些啥题目吧... T1 嗯,裂开了,当场裂开我一看!桶排!然后实现,嗯?嗯!嗯 ...
- 【源码解读(一)】EFCORE源码解读之创建DBContext查询拦截
引言 在网上很少看到有关于系统讲解EFCore源码的,可能大概也许是因为EFCore的源码总体是没有asp.net web的源码流程清晰,正如群友所说,EFCore的源码大致看起来有点凌乱,与其说凌乱 ...
- Java-全网最详细反射
Java-反射 前言 Java的反射(reflection)机制是指在程序的运行状态中,可以构造任意一个类的对象,可以了解任意一个对象所属的类,可以了解任意一个类的成员变量和方法,可以调用任意一个对象 ...
- 2D物理引擎 Box2D for javascript Games 第五章 碰撞处理
2D物理引擎 Box2D for javascript Games 第五章 碰撞处理 碰撞处理 考虑到 Box2D 世界和在世界中移动的刚体之间迟早会发生碰撞. 而物理游戏的大多数功能则依赖于碰撞.在 ...
- 探索CPU的黑盒子:解密指令执行的秘密
引言 在我们之前的章节中,我们着重讲解了CPU内部的处理过程,以及与之密切相关的数据总线知识.在这个基础上,我们今天将继续深入探讨CPU执行指令的相关知识,这对于我们理解计算机的工作原理至关重要. C ...
- jenkins 原理篇——pipeline流水线 声明式语法详解
大家好,我是蓝胖子,相信大家平时项目中或多或少都有用到jenkins,它的piepeline模式能够对项目的发布流程进行编排,优化部署效率,减少错误的发生,如何去写一个pipeline脚本呢,今天我们 ...
- HarmonyOS UI 开发
引言 HarmonyOS 提供了强大的 UI 开发工具和组件,使开发者能够创建吸引人的用户界面.本章将详细介绍在 HarmonyOS 中应用 JS.CSS.HTML,HarmonyOS 的 UI 组件 ...
- Java代码审计之目录穿越(任意文件下载/读取)
一.目录穿越漏洞 1.什么是目录穿越 所谓的目录穿越指利用操作系统中的文件系统对目录的表示.在文件系统路径中,".."表示上一级目录,当你使用"../"时,你正 ...