minos 2.3 中断虚拟化——GICv2 管理
- 首发公号:Rand_cs
硬件肯定需要软件配合,这一节就来实战 GICv2
首先准备好 GICv2 手册:https://developer.arm.com/documentation/ihi0048/bb/?lang=en,对于硬件的管理,最底层的操作就是读写硬件的寄存器,所以这里准备好手册,随时查阅手册
// gicv2.c
static void *gicv2_dbase;
static void *gicv2_cbase;
首先定义了两个变量,gicc(cpu interface) 和 gicd(distributor)基地值,这个值是在设备树文件中定义,然后 gic 初始化函数中映射到 hyp 虚拟地址
static inline void writeb_gicd(uint8_t val, unsigned int offset)
{
writeb_relaxed(val, gicv2_dbase + offset);
}
static inline void writel_gicd(uint32_t val, unsigned int offset)
{
writel_relaxed(val, gicv2_dbase + offset);
}
static inline uint32_t readl_gicd(unsigned int offset)
{
return readl_relaxed(gicv2_dbase + offset);
}
static inline void writel_gicc(uint32_t val, unsigned int offset)
{
writel_relaxed(val, gicv2_cbase + offset);
}
static inline uint32_t readl_gicc(unsigned int offset)
{
return readl_relaxed(gicv2_cbase + offset);
}
随后定义了一系列读写寄存器的函数,就是相对 (gicc/gicd) 不同的偏移上进行读写,下面我们来看看主要需要操作哪些寄存器
GICD
GICD_ISENABLERn、 GICD_ICENABLERn
一个 GICD_ISENABLER 寄存器 32 bit,每一位控制一个中断的使能情况,n 表示第几个 GICD_ISENABLER 寄存器。向某位写 1 表示使能该中断,写 0 无效。
一个 GICD_ICENABLER 寄存器 32 bit,每一位控制一个中断的屏蔽情况,n 表示第几个 GICD_ICENABLER 寄存器。向某位写 1 表示屏蔽该中断,写 0 无效。
在 ARM 平台,使能和屏蔽一个中断是通过不同的寄存器来控制的,而不是一个寄存器使用 0 1 来分别表示屏蔽使能。这么做的好处之前有了解过是为了操作可以并行,比如说现在有操作使能第一号中断和屏蔽第二号中断,如果只使用0、1的方式来控制中断的屏蔽使能情况,第一号中断和第二号中断位于同一个寄存器,那么想要实现此操作,需要串行执行,但是如果使用 GICD_ISENABLER 来控制使能,GICD_ICENABLER 控制屏蔽,那么两个步骤就可以并行。另外因为写 0 无效,所以想要执行写操作的时候,不用先读后写(一般操作:read a,a |= x,write a,现在直接 write x)
// 屏蔽中断号为 irq 的中断
static void gicv2_mask_irq(uint32_t irq)
{
unsigned long flags;
spin_lock_irqsave(&gicv2_lock, flags);
// 写 0 无效,所以可以直接写入值 1UL << (irq % 32)
// irq / 32 表示第几个 GICD_ICENABLER 寄存器
// (irq / 32) * 4,按字节算偏移,乘以 4
writel_gicd(1UL << (irq % 32), GICD_ICENABLER + (irq / 32) * 4);
dsb();
spin_unlock_irqrestore(&gicv2_lock, flags);
}
// 使能中断号为 irq 的中断
static void gicv2_unmask_irq(uint32_t irq)
{
unsigned long flags;
spin_lock_irqsave(&gicv2_lock, flags);
writel_gicd(1UL << (irq % 32), GICD_ISENABLER + (irq / 32) * 4);
dsb();
spin_unlock_irqrestore(&gicv2_lock, flags);
}
GICD_ICFGRn
Interrupt Configuration Registers,用来配置中断的类型
中断类型:边沿触发、电平触发
中断模型:
- 1-N 模型,只有一个 cpu 能够处理该中断,这指的是一个中断发送给多个 cpu,当此中断被某个 cpu 响应之后,gic 会清除掉此中断在其他所有 cpu 上的 pending 状态。
- 这是专门用来描述 SPI 类型中断的。试想,磁盘数据好了,发送磁盘中断信号给 cpu,每个 cpu 都可以处理,但是肯定只能有一个 cpu 处理,否则数据紊乱
- 当 CPU 从 GICC_IAR 读取中断号的时候,可能会读取到正确的中断号,这是响应 cpu。其他 cpu 会读取到 1023,这表示一个伪中断。
- N-N 模型,所有 cpu 都会独立的收到该中断信号,当一个 cpu 相响应中断后,只是为该 cpu 清除掉此中断的 pending 状态。此中断对于其他 cpu 来说仍然是 pending 状态,其他 cpu 仍然需要响应处理此中断
GICD_ICFGR 寄存器就是用来配置一个中断的类型和模型
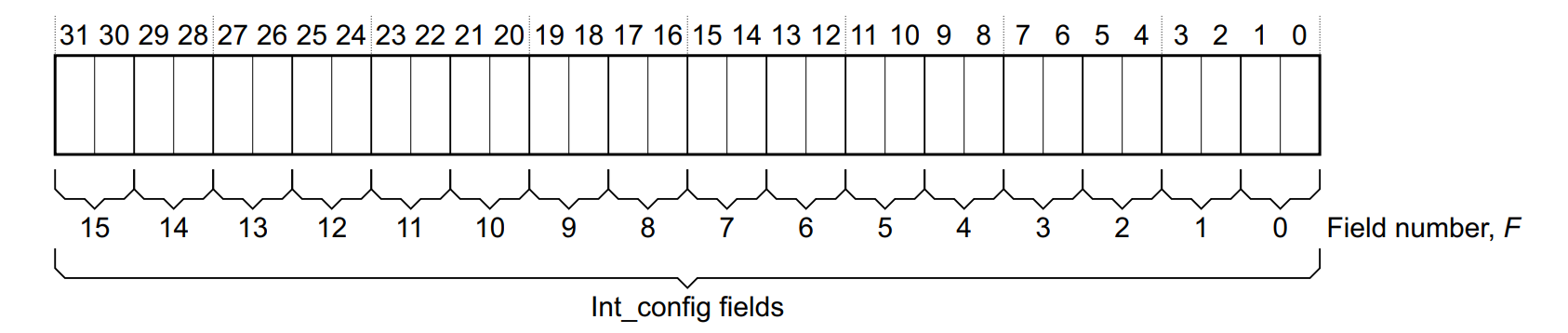
一个 GICD_ICFGR 寄存器 32bits,一个中断占 2bits
bit[0] 表示中断模型,为 0 表示 N-N 模型,为 1 表示 1-N 模型
bit[1] 表示中断类型,为 0 表示电平触发,为 1 表示边沿触发
static int gicv2_set_irq_type(uint32_t irq, uint32_t type)
{
uint32_t cfg, edgebit;
if (irq < 16)
return 0;
spin_lock(&gicv2_lock);
/* Set edge / level */
cfg = readl_gicd(GICD_ICFGR + (irq / 16) * 4);
edgebit = 2u << (2 * (irq % 16)); // 边沿触发
if ( type & IRQ_FLAGS_LEVEL_BOTH)
cfg &= ~edgebit;
else if (type & IRQ_FLAGS_EDGE_BOTH)
cfg |= edgebit;
writel_gicd(cfg, GICD_ICFGR + (irq / 16) * 4);
spin_unlock(&gicv2_lock);
return 0;
}
GICD_IPRIORITYR
Interrupt Priority Registers,设置每个中断的优先级

一个 GICD_IPRIORITYR 寄存器 32 bits,分为 4 组,每 8 bits 表示一个中断的优先级
static int gicv2_set_irq_affinity(uint32_t irq, uint32_t pcpu)
{
if (pcpu > NR_GIC_CPU_IF || irq < 32)
return -EINVAL;
spin_lock(&gicv2_lock);
/* Set target CPU mask (RAZ/WI on uniprocessor) */
writeb_gicd(1 << pcpu, GICD_ITARGETSR + irq);
spin_unlock(&gicv2_lock);
return 0;
}
GICD_ITARGETSR
Interrupt Processor Targets Registers,设置中断亲和性

一个 GICD_ITARGETSR 寄存器 32 bits,分为 4 组,每 8 bits 表示一个中断的亲和性。举个例子,如果某个中断的亲和性设置 3(0b11),那么这个中断将会被 distributor 转发给 0、1 号 cpu interface。
另外,前面提到过,SPI 的中断号从 32 开始,所以 GICD_ITARGETSR0~GICD_ITARGETSR7 "无用",读取GICD_ITARGETSR0~GICD_ITARGETSR7会返回执行读取操作 cpu 的 id 值
static int gicv2_set_irq_affinity(uint32_t irq, uint32_t pcpu)
{
if (pcpu > NR_GIC_CPU_IF || irq < 32)
return -EINVAL;
spin_lock(&gicv2_lock);
/* Set target CPU mask (RAZ/WI on uniprocessor) */
writeb_gicd(1 << pcpu, GICD_ITARGETSR + irq);
spin_unlock(&gicv2_lock);
return 0;
}
GICD_SGIR
Software Generated Interrupt Register,写这个寄存器来产生 SGI 中断
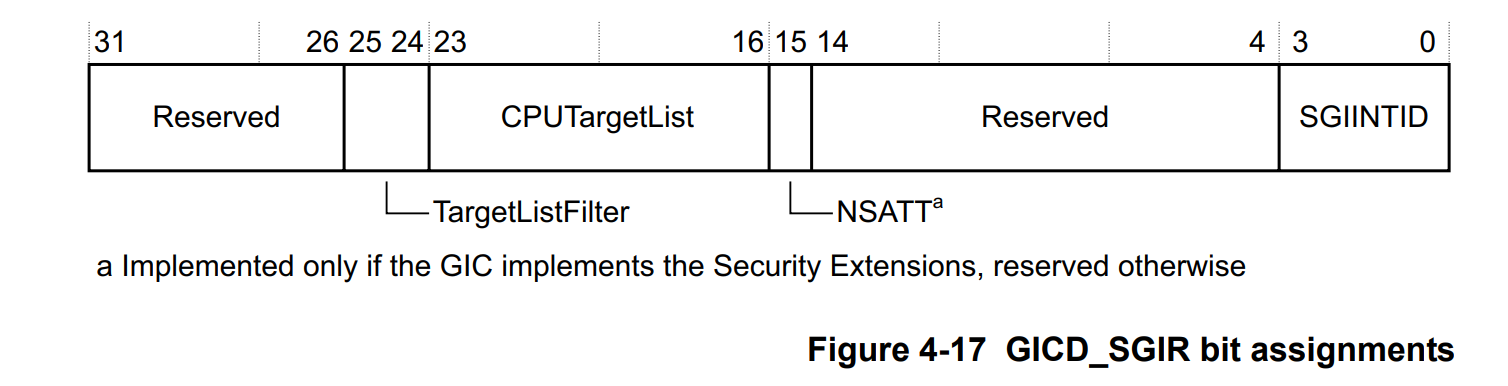
关注两个字段:
- TargetListFilter
- 0b00,表示向位于 CPUTargetList 位图中的 CPU Interface集合发送 SGI
- 0b01,表示向所有 CPU Interface发送一个 SGI 中断
- 0b10,表示向自己发送一个 SGI
- 0b11,reserved
- CPUTargetList,一个 CPU 位图,某一位为 1 表示要向该 CPU Interface 发送一个 SGI(TargetListFilter=0b00 的情况下)
static void gicv2_send_sgi(uint32_t sgi, enum sgi_mode mode, cpumask_t *mask)
{
unsigned int cpu;
unsigned int value = 0;
switch (mode) {
// 发送一个 SGI 给所有 CPU
case SGI_TO_OTHERS:
writel_gicd(GICD_SGI_TARGET_OTHERS | sgi, GICD_SGIR);
break;
// 给自己发送一个 SGI
case SGI_TO_SELF:
writel_gicd(GICD_SGI_TARGET_SELF | sgi, GICD_SGIR);
break;
// 发送一个 SGI 给目标 CPU 组
case SGI_TO_LIST:
for_each_cpu(cpu, mask)
value |= gic_cpu_mask[cpu];
// 填写目标 CPU 位图集合
writel_gicd(GICD_SGI_TARGET_LIST |
(value << GICD_SGI_TARGET_SHIFT) | sgi,
GICD_SGIR);
isb();
break;
default:
break;;
}
}
NOTE,Distributor 只会向 CPU Interface 转发中断请求,CPU Interface 才会向 CPU 发送中断信号
GICD_TYPER
Interrupt Controller Type Register,有关 GICD 的一些信息
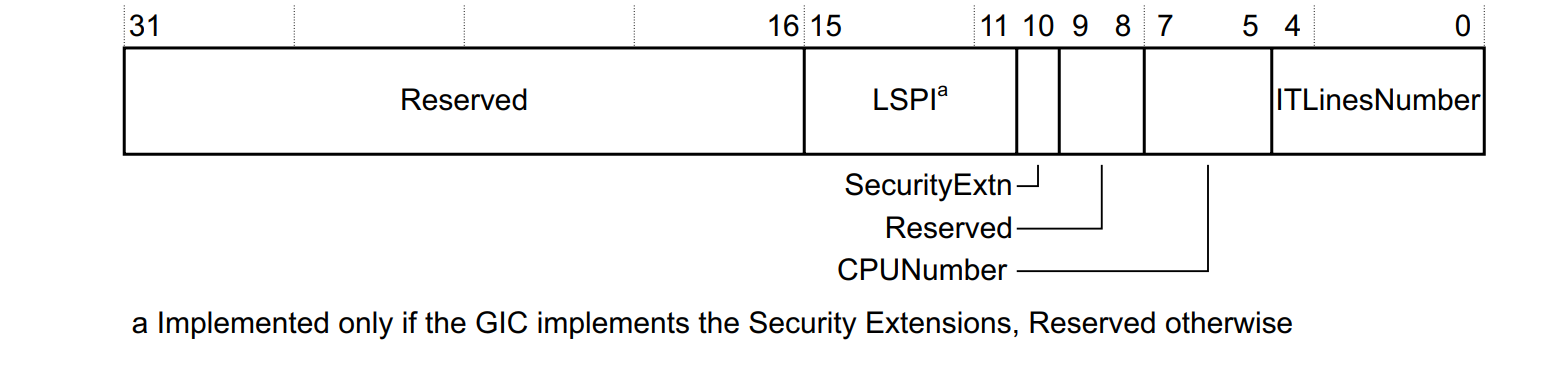
ITLinesNumber:支持的中断个数
CPUNumber:CPU 个数
GICC
GICC_EOIR、GICC_DIR
当一个中断完成的时候,CPU 必须发送一个 “complete” 信号给 GIC,“complete” 步骤分为两步:
- Priority drop,优先级降低。中断状态并未改变,仍然是 active。优先级降低指的是当前 CPU 上 "running priority",降低之后 cpu interface 可以继续发送优先级较低的中断给 cpu。
- Interrupt deactivation,真正改变中断状态了。可以从 active->inactive,active and pending->pending
这涉及到了 3 个寄存器,GICC_EOIR(End of Interrupt Register),GICC_DIR(Deactivate Interrupt Register),GICC_CTLR(CPU Interface Control Register)
当 GICC_CTLR.EOImode = 1 时,Priority drop 和 Interrupt deactivation 两个步骤是分开的,也就是说写 GICC_EOIR 会 Priority drop,写 GICC_DIR 会 Interrupt deactivation
当 GICC_CTLR.EOImode = 0 是,Priority drop 和 Interrupt deactivation 两个步骤是在一起的,写 GICC_EOIR 寄存器就表示完成两个步骤
GICC_DIR 和 GICC_EOIR 格式都如下所示:

static void gicv2_eoi_irq(uint32_t irq)
{
writel_gicc(irq, GICC_EOIR);
dsb();
}
static void gicv2_dir_irq(uint32_t irq)
{
writel_gicc(irq, GICC_DIR);
dsb();
}
用法也很简单,写入相应的中断号就行
GICC_IAR
Interrupt Acknowledge Register,CPU 读取此寄存器来获取中断号,并且也是一个 ACK 操作

static uint32_t gicv2_read_irq(void)
{
uint32_t irq;
irq = readl_gicc(GICC_IAR);
isb();
irq = irq & GICC_IA_IRQ;
return irq;
}
格式同前 EOIR,操作也是很简单, 从低 10 bits 获取中断号
GICC_PMR
Interrupt Priority Mask Register,只有优先级比 GICC_PMR 里面设置的高,才会将该中断信号发送给 cpu

格式如上,一般我们写 0xff,表示不屏蔽任何中断(值越大,优先级越低)
GIC INIT
gicv2_dist_init
static void __init_text gicv2_dist_init(void)
{
uint32_t type;
uint32_t cpumask;
uint32_t gic_cpus;
unsigned int nr_lines;
int i;
// 所有中断都往 pcpu0 发送
cpumask = readl_gicd(GICD_ITARGETSR) & 0xff;
cpumask = (cpumask == 0) ? (1 << 0) : cpumask;
cpumask |= cpumask << 8;
cpumask |= cpumask << 16;
/* Disable the distributor */
writel_gicd(0, GICD_CTLR);
// 从 GICD_TYPER 寄存器里面获取 cpu 数量和支持的中断数
type = readl_gicd(GICD_TYPER);
nr_lines = 32 * ((type & GICD_TYPE_LINES) + 1);
gic_cpus = 1 + ((type & GICD_TYPE_CPUS) >> 5);
pr_notice("GICv2: %d lines, %d cpu%s%s (IID %x).\n",
nr_lines, gic_cpus, (gic_cpus == 1) ? "" : "s",
(type & GICD_TYPE_SEC) ? ", secure" : "",
readl_gicd(GICD_IIDR));
/* Default all global IRQs to level, active low */
// 配置所有 irq 为边沿触发
for ( i = 32; i < nr_lines; i += 16 )
writel_gicd(0x0, GICD_ICFGR + (i / 16) * 4);
/* Route all global IRQs to this CPU */
// 配置所有中断的亲和性为 cpu0
for ( i = 32; i < nr_lines; i += 4 )
writel_gicd(cpumask, GICD_ITARGETSR + (i / 4) * 4);
/* Default priority for global interrupts */
for ( i = 32; i < nr_lines; i += 4 )
writel_gicd(GIC_PRI_IRQ << 24 | GIC_PRI_IRQ << 16 |
GIC_PRI_IRQ << 8 | GIC_PRI_IRQ,
GICD_IPRIORITYR + (i / 4) * 4);
/* Disable all global interrupts */
// 屏蔽所有中断
for ( i = 32; i < nr_lines; i += 32 )
writel_gicd(~0x0, GICD_ICENABLER + (i / 32) * 4);
/* Only 1020 interrupts are supported */
// 从支持的中断数和 1020 之中选一个小的
gicv2_nr_lines = min(1020U, nr_lines);
/* Turn on the distributor */
// 使能所有中断
writel_gicd(GICD_CTL_ENABLE, GICD_CTLR);
dsb();
}
gicv2_cpu_init
static void __init_text gicv2_cpu_init(void)
{
int i;
int cpuid = smp_processor_id();
// 读取 GICD_ITARGETSR0 会返回当前 cpuid
gic_cpu_mask[cpuid] = readl_gicd(GICD_ITARGETSR) & 0xff;
pr_debug("gicv2 gic mask of cpu%d: 0x%x\n", cpuid, gic_cpu_mask[cpuid]);
if (gic_cpu_mask[cpuid] == 0)
gic_cpu_mask[cpuid] = 1 << cpuid;
/* The first 32 interrupts (PPI and SGI) are banked per-cpu, so
* even though they are controlled with GICD registers, they must
* be set up here with the other per-cpu state. */
// TODO ???
writel_gicd(0xffff0000, GICD_ICENABLER); /* Disable all PPI */
writel_gicd(0x0000ffff, GICD_ISENABLER); /* Enable all SGI */
/* Set SGI priorities */
// 设置 SGI 的优先级,IPIs must preempt normal interrupts
for ( i = 0; i < 16; i += 4 )
writel_gicd(GIC_PRI_IPI << 24 | GIC_PRI_IPI << 16 |
GIC_PRI_IPI << 8 | GIC_PRI_IPI,
GICD_IPRIORITYR + (i / 4) * 4);
/* Set PPI priorities */
// 设置 PPI 的优先级
for ( i = 16; i < 32; i += 4 )
writel_gicd(GIC_PRI_IRQ << 24 | GIC_PRI_IRQ << 16 |
GIC_PRI_IRQ << 8 | GIC_PRI_IRQ,
GICD_IPRIORITYR + (i / 4) * 4);
/* Local settings: interface controller */
/* Don't mask by priority */
writel_gicc(0xff, GICC_PMR);
/* Finest granularity of priority */
writel_gicc(0x0, GICC_BPR);
/* Turn on delivery */
// GICC_CTL_ENABLE 允许 group1(非安全中断,目前minos里面都是)中断发送给 cpu
// GICC_CTL_EOI drop priority 和 deactivate interrupt 分开
writel_gicc(GICC_CTL_ENABLE|GICC_CTL_EOI, GICC_CTLR);
dsb();
}
gicv2_init
static struct irq_chip gicv2_chip = {
.irq_mask = gicv2_mask_irq,
.irq_mask_cpu = gicv2_mask_irq_cpu,
.irq_unmask = gicv2_unmask_irq,
.irq_unmask_cpu = gicv2_unmask_irq_cpu,
.irq_eoi = gicv2_eoi_irq,
.irq_dir = gicv2_dir_irq,
.irq_set_type = gicv2_set_irq_type,
.irq_set_affinity = gicv2_set_irq_affinity,
.send_sgi = gicv2_send_sgi,
.get_pending_irq = gicv2_read_irq,
.irq_set_priority = gicv2_set_irq_priority,
.irq_xlate = gic_xlate_irq,
.init = gicv2_init,
.secondary_init = gicv2_secondary_init,
};
irq_chip 是一个 gic 芯片抽象,对于 gicv2 的抽象定义在了 gicv2_chip,大多操作我们都讲述了
gicv2_init 涉及设备树操作以以及虚拟化的初始化,后面讲述。gicv2_secondary_init 这是级联相关(一个 gic 芯片不够,多个 gic 芯片连接起来共同工作)目前不涉及
- 首发公号:Rand_cs
minos 2.3 中断虚拟化——GICv2 管理的更多相关文章
- 【原创】Linux虚拟化KVM-Qemu分析(六)之中断虚拟化
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: KVM版本:5.9 ...
- KVM中断虚拟化浅析
2017-08-24 今天咱们聊聊KVM中断虚拟化,虚拟机的中断源大致有两种方式,来自于用户空间qemu和来自于KVM内部. 中断虚拟化起始关键在于对中断控制器的虚拟化,中断控制器目前主要有APIC, ...
- KVM虚拟化储存管理(3)
一.KVM 存储虚拟化介绍 KVM 的存储虚拟化是通过存储池(Storage Pool)和卷(Volume)来管理的. Storage Pool 是宿主机上可以看到的一片存储空间,可以是多种型: Vo ...
- KVM虚拟化网卡管理
brctl常用命令 查看当前虚拟网桥状态 brctl show 添加一个网桥 addbr 删除一个网桥 delbr 添加网口 addif 删除网口 delif VALN LAN 表示 Local Ar ...
- ESXI 虚拟化误删除管理端口Management Network (vmk0),导致无法访问后台解决方案
按F2开启控制台shell,启用后返回.按Alt+F1打开终端. 输入 esxcfg-vmknic -a -i 192.168.1.10 -n 255.255.255.0 "Manageme ...
- Linux中断管理 (1)Linux中断管理机制
目录: <Linux中断管理> <Linux中断管理 (1)Linux中断管理机制> <Linux中断管理 (2)软中断和tasklet> <Linux中断管 ...
- Linux中断管理 (1)Linux中断管理机制【转】
转自:https://www.cnblogs.com/arnoldlu/p/8659981.html 目录: <Linux中断管理> <Linux中断管理 (1)Linux中断管理机 ...
- stm32中断优先级管理与外部中断编程
stm32中断优先级管理与外部中断编程 中断优先级管理 外部中断编程 官方示例程序 exti.h #ifndef __EXTI_H #define __EXIT_H #include "sy ...
- kvm虚拟化管理平台WebVirtMgr部署-完整记录(0)
打算部署kvm虚拟机环境,下面是虚拟化部署前的一些准备工作: 操作系统环境安装1)修改内核模式为兼容内核启动[root@ops ~]# uname -aLinux openstack 2.6.32-4 ...
- 【原创】Linux中断子系统(一)-中断控制器及驱动分析
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
随机推荐
- 【hibernate】使用HQL对页面进行时间校验操作(预约)
[hibernate]使用HQL对页面进行时间校验操作(预约) 预约系统中的时间校验 正好接了一个预约的需求,还需要用java 7和hibernate 1.时间冲突,时间段不能重复,在保存前对数据库进 ...
- 教你如何进行Prometheus 分片自动缩放
本文分享自华为云社区<使用 Prometheus-Operator 进行 Prometheus + Keda 分片自动缩放>,作者: Kubeservice@董江. 垂直缩放与水平缩放 P ...
- 力扣430(java)-扁平化多级双向链表(中等)
题目: 你会得到一个双链表,其中包含的节点有一个下一个指针.一个前一个指针和一个额外的 子指针 .这个子指针可能指向一个单独的双向链表,也包含这些特殊的节点.这些子列表可以有一个或多个自己的子列表,以 ...
- P9562 [SDCPC2023] G-Matching 题解
题目描述 给定长度为 \(n\) 的整数序列 \(a_1, a_2, \cdots, a_n\),我们将从该序列中构造出一张无向图 \(G\).具体来说,对于所有 \(1 \le i < j \ ...
- 使用Databricks+Mlflow进行机器学习模型的训练和部署【Databricks 数据洞察公开课】
简介: 介绍如何使用Databricks和MLflow搭建机器学习生命周期管理平台,实现从数据准备.模型训练.参数和性能指标追踪.以及模型部署的全流程. 作者:李锦桂 阿里云开源大数据平台开发工程 ...
- 剪贴板被占用导致应用使用剪贴板拷贝内容失败抛出 COMException 0x800401D0 错误
本文记录某些软件,例如 向日葵远程控制 软件占用剪贴板,导致 WPF 应用使用剪贴板拷贝内容和设置剪贴板时,抛出 System.Runtime.InteropServices.COMException ...
- 集群监管-USDP(智能大数据平台)
UCloud Smart Data Platform(简称 USDP),是 UCloud 推出的智能化.轻量级.适用于私有化部署至客户本地的大数据基础服务平台,通过自研的 USDP Manager 管 ...
- JS实现跟随鼠标移动的div,和一串跟随鼠标的div,鼠标移入移出实现图片的颜色淡入淡出
1.一直跟着鼠标移动的div:原理是div的left和top值有oEvent.clientX+scrollLeft鼠标指针向对于浏览器页面(或客户区)的水平坐标+元素中滚动条的水平偏移 <!DO ...
- 关于小说阅读前端翻页插件推荐turn.js
http://www.turnjs.com
- P3193 [HNOI2008] GT考试 题解
之前学矩阵乘的时候做的题,当时因为不会\(kmp\)搜索一稀里糊涂过去了,现在填个坑. 头图 是\(Logos\)! P3193 [HNOI2008] GT考试 题链:洛谷 题库 题目大意: 求有多少 ...