Springboot+ELK实现日志系统简单搭建
前面简单介绍了ELK三剑客中的其中两个Elasticsearch和Kibana的简单使用,如果对这两个不了解,可以看下下面的
现在来看看这最后一个Logstash
还是这个地方https://elasticsearch.cn/download/ 下载与es,kibana版本对应的Logstash,然后解压。
1.和es一样,如果机器内存小,有想玩这个的,记得把config下面的jvm.options文件中的jvm参数设置小点,我设置的256m:
-Xms256m
-Xmx256m
2.写配置文件logstash.conf,默认有个logstash-sample.conf这个文件,可以直接拿来修改
内容如下:
#暴露9090端口作为输入
input {
tcp {
#host 192.168.0.69
port => 9090
}
}
#输出到elasticsearch,此输出创建一个名为myserver的索引
output {
elasticsearch {
hosts => ["http://192.168.0.67:9200"]
index => "myserver"
}
}
以上就是最简单的配置了
3.使用此配置文件启动logstash:./bin/logstash -f ./config/logstash.conf

4.创建spingboot工程,springboot日志本来就用的logback,但是我们还需要引入相关的logstash依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.2</version>
</dependency>
5.在appliction.properties配置文件指定logstash服务的端口位置,就是上面logstash 暴露出来的输入端口,我们上面的是9090端口
logstash.address=192.168.0.69:9090
6.logback日志配置文件:logback-spring.xml(resources下面和工程appliction配置文件同级)
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--logstash地址,从application.properties中获取-->
<springProperty scope="context" name="LOGSTASH_ADDRESS" source="logstash.address"/> <!--输出到logstash的appender-->
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!--可以访问的logstash日志收集端口-->
<destination>${LOGSTASH_ADDRESS}</destination>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>Asia/Shanghai</timeZone>
</timestamp>
<pattern>
<pattern>
{
"app": "my-server",
"level": "%level",
"thread": "%thread",
"logger": "%logger{50} %M %L ",
"message": "%msg"
}
</pattern>
</pattern>
<stackTrace>
<throwableConverter class="net.logstash.logback.stacktrace.ShortenedThrowableConverter">
<maxDepthPerThrowable>100</maxDepthPerThrowable>
<rootCauseFirst>true</rootCauseFirst>
<inlineHash>true</inlineHash>
</throwableConverter>
</stackTrace>
</providers>
</encoder>
</appender> <root level="INFO">
<appender-ref ref="LOGSTASH"/>
</root>
</configuration>
7.启动springboot服务,这个时候我们会发现控制台不会再输出日志了,因为日志输出到logstash,再由logstash发送到es去了。
调用我们接口查看下服务是否成功启动了

说明服务已经成功启动,现在去看kibana查看日志信息
8.搜索是否有myserver的索引,可以看到tomcat 8080端口启动的日志

我们每次都这样搜索来看是不是很不方便,我们可以把这个索引加到discover中,后续只需要在里面搜索我们想要内容就行了
9.Management --->Index Patterns --->Create index pattern--->搜索匹配的索引然后创建
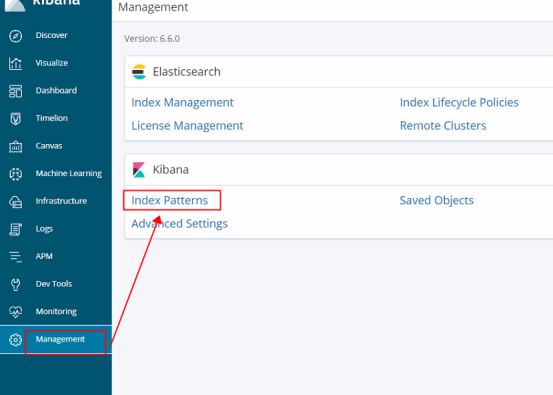
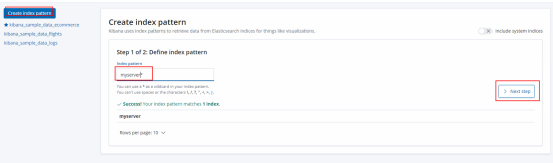
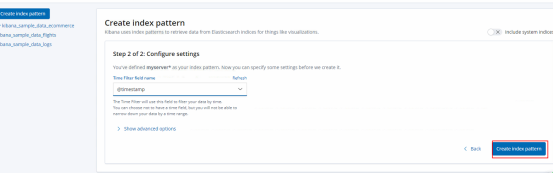
创建好了就可以在kibana的index列表看见这个索引了
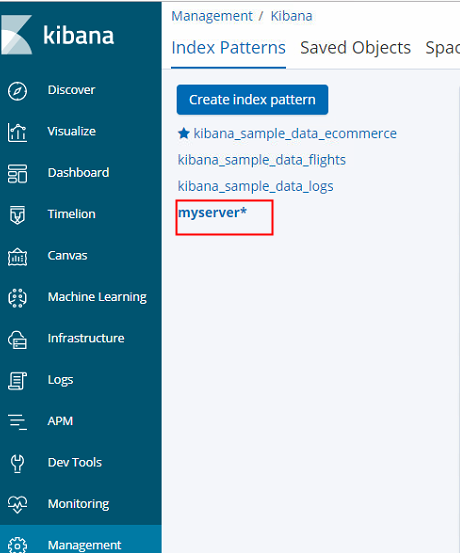
现在就可以discover中使用这个索引了,不用再去dev tools工具中去写查询了

我们着看刚才调用接口打印的日志就可以在discover中看见了
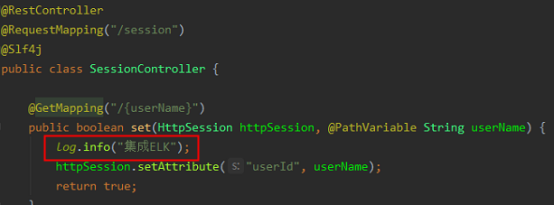
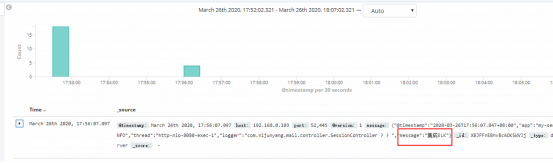
10.discover中信息筛选:默认的筛选时间是15分钟内的,如果时间比较久了就需要重新选择下时间,然后输入要搜索的内容port,我们就可以看到之前服务起动的日志了
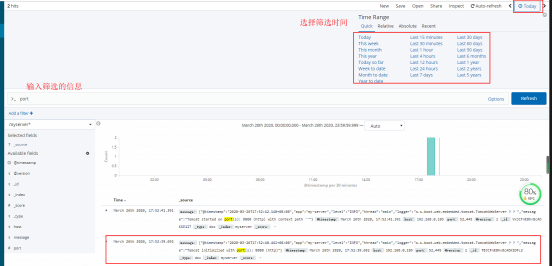
ELK简单的集成使用,大概就是这个样子了,当然logstash中还可以去过滤处理数据。像我们现在的日志在kibana里面的格式是很难看的。
Springboot+ELK实现日志系统简单搭建的更多相关文章
- ELK分布式日志系统的搭建
前言 ELK即分别为ElasticSearch.Logstash(收集.分析.过滤日志的工具).Kibana(es的可视化工具),其主要工作原理就是由不同机器上的logstash收集日志后发送给es, ...
- 【7.1.1】ELK日志系统单体搭建
ELK是什么? 一般来说,为了提高服务可用性,服务器需要部署多个实例,每个实例都是负载均衡转发的后的,如果还用老办法登录服务器去tail -f xxx.log,有很大可能错误日志未出现在当前服务器中, ...
- .NET下日志系统的搭建——log4net+kafka+elk
.NET下日志系统的搭建--log4net+kafka+elk 前言 我们公司的程序日志之前都是采用log4net记录文件日志的方式(有关log4net的简单使用可以看我另一篇博客),但是随着 ...
- ELK +Nlog 分布式日志系统的搭建 For Windows
前言 我们为啥需要全文搜索 首先,我们来列举一下关系型数据库中的几种模糊查询 MySql : 一般情况下LIKE 模糊查询 SELECT * FROM `LhzxUsers` WHERE UserN ...
- ELK统一日志系统的应用
收集和分析日志是应用开发中至关重要的一环,互联网大规模.分布式的特性决定了日志的源头越来越分散, 产生的速度越来越快,传统的手段和工具显得日益力不从心.在规模化场景下,grep.awk 无法快速发挥作 ...
- Ubuntu学习笔记-win7&Ubuntu双系统简单搭建系统指南
win7&Ubuntu双系统简单搭建系统指南 本文是自己老本子折腾Ubuntu的一些记录,主要是搭建了一个能够足够娱乐(不玩游戏)专注练习自己编程能力的内容.只是简单的写了关于系统的安装和一些 ...
- springboot+ELK+logback日志分析系统demo
之前写的有点乱,这篇整理了一下搭建了一个简单的ELK日志系统 借鉴此博客完成:https://blog.csdn.net/qq_22211217/article/details/80764568 设置 ...
- mysql日志系统简单使用
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBM ...
- springboot elk实时日志搭建
https://blog.csdn.net/yy756127197/article/details/78873310 基本的上的过程如这篇博客,logback的配置文件和依赖不太一样 具体见源码其中的 ...
- ELK+Kafka日志收集环境搭建
1.搭建Elasticsearch环境并测试: (1)删除es的容器 (2)删除es的镜像 (3)宿主机调内存: 执行命令:sudo sysctl -w vm.max_map_count=655360 ...
随机推荐
- mysql alter与update的区别
alter是更改表名,字段的 而updata是更改数据的,一定要记住要联合where使用,否则就会全部更改. updata与set联用 alter与change column和add联用
- ez_curl【代码审计】
ez_curl[代码审计][难度:4] 题目描述 代码审计类题目,附上代码: <?php highlight_file(__FILE__); $url = 'http://back-end:30 ...
- jenkins安装部署、主从架构、slave镜像、K8S对接
介绍 CI/CD工具,自动化持续集成和持续部署,用于构建各种自动化任务. 官方提供了docker镜像https://hub.docker.com/r/jenkins/jenkins 使用Deploym ...
- 如何对U盘的使用权限进行管控
对U盘的使用权限进行管控是保护企业信息安全的一项重要措施.以下是一些常见的方法,可帮助您有效管理和控制U盘的使用权限: 禁用U盘端口: 在公司计算机上禁用或限制USB端口的使用,特别是那些不需要使用U ...
- 浅谈android的activity
说道activity,大家可以说是熟悉的不能再熟悉,首先,先来个镇楼图, 个人觉得谷歌的这张图,比别的什么生命周期图都好;说下各个生命周期注意的: 1:onstart()时,activity可见; 2 ...
- 工具类图片转base64
工具类图片转base64 import sun.misc.BASE64Encoder; import java.io.FileInputStream; import java.io.IOExcepti ...
- MinIO客户端之diff
MinIO提供了一个命令行程序mc用于协助用户完成日常的维护.管理类工作. 官方资料 mc diff 检查指定桶内对象清单的差异,注意不比较对象内容的差异,命令如下: ./mc diff local1 ...
- django token 认证 简单记录
class User(AbstractUser): username = models.CharField( max_length=20, unique=True, primary_key=True, ...
- flutter中显示年月日、星期与时间
代码 import 'package:flutter/material.dart'; import 'package:intl/intl.dart'; import 'dart:async'; imp ...
- 神经网络基础篇:史上最详细_详解计算图(Computation Graph)
计算图 可以说,一个神经网络的计算,都是按照前向或反向传播过程组织的.首先计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作.后者用来计算出对应的梯度或导数.计算图解释了为什么用这种方式 ...