[转帖]性能调优:理解Set Statistics IO输出
https://www.cnblogs.com/woodytu/p/4535658.html
性能调优是DBA的重要工作之一。很多人会带着各种性能上的问题来问我们。我们需要通过SQL Server知识来处理这些问题。经常被问到的一个问题是:早上这个存储过程运行时间还是可以的,但到了晚上就很慢很慢。对此,我们可以笑着回答:这个存储过程运行多次后,已经累趴了,所以很慢。
存储过程或语句运行时间取决于服务器的工作量。如果在晚上,服务器负担很重的话,你的存储过程可能需要更多的时间来运行,因为它在等待CPU周期(CPU cycle)和IO完成(IO completion)。为了获得一致的响应时间,我们需要减少执行完成的资源需求,那就是所谓的性能调优。
IO和CPU是完成执行的主要资源使用对象。更少的资源使用,更稳定的性能表现。这篇文章我们来理解下性能调优中DBCC STATISTCS IO所扮演的角色。
默认情况下SET STATISTCS IO是停用的,我们可以通过下列语句在当前会话级别打开。
1 SET STATISTICS IO ON
这个语句可以帮助我们获得在语句执行时,所发生IO数(页读/写)。我们来看一个例子的输出。

1 USE StatisticsDB
2 GO
3 SELECT * INTO SalesOrderDetail FROM AdventureWorks2008R2.Sales.SalesOrderDetail
4 GO
5 SET STATISTICS IO ON
6 DBCC dropcleanbuffers
7 DBCC freeproccache
8 GO
9 SELECT * FROM SalesOrderDetail
10 GO
11 SELECT * FROM SalesOrderDetail

Set Statistics IO的输出信息可以在消息TAB页里找到。同样的语句我们执行了2次,第一次是在清空缓存后执行,第2次没有。
我们来看下输出信息:
扫描计数(Scan count):
根据微软在线帮助,扫描计数是在任何方向都达到叶级别后启动的查询/扫描数,目的在于检索用于构造输出的最终数据集的所有值。
- 如果使用的索引是主键的唯一索引或聚集索引并且您仅查找一个值,则扫描计数为 0。 例如 WHERE Primary_Key_Column = <value>。
当您使用对非主键列定义的非唯一的聚集索引搜索一个值时,扫描计数为 1。 这是为了针对您正在搜索的键值检查重复值。 例如 WHERE Clustered_Index_Key_Column = <value>。
当 N 为通过使用索引键定位键值后,在叶级别的左侧或右侧启动的不同查找/扫描数时,则扫描计数为 N。
这个数字告诉我们优化器所选择的计划,对这个对象的重复读取次数。很多人误以为这个是对整张表的读取次数,这是完全错误的。
我们通过一个例子来理解扫描计数。
1 CREATE TABLE ScanCount (Id INT IDENTITY(1,1),Value CHAR(1))
2 INSERT INTO ScanCount (Value ) VALUES ('A') ,('B'),('C'),('D'), ('E') , ('F')
3 CREATE UNIQUE CLUSTERED INDEX ix_ScanCount ON ScanCount(Id)
4
5 SET STATISTICS IO ON
6 --Unique clustered Index used to search single value
7 SELECT * FROM ScanCount WHERE Id =1
8 --Unique clustered Index used to search multiple value
9 SELECT * FROM ScanCount WHERE Id IN(1,2,3,4,5,6)
10 --Unique clustered Index used to search multiple value
11 SELECT * FROM ScanCount WHERE Id BETWEEN 1 AND 6
我们来看下上面3个查询语句的输出。
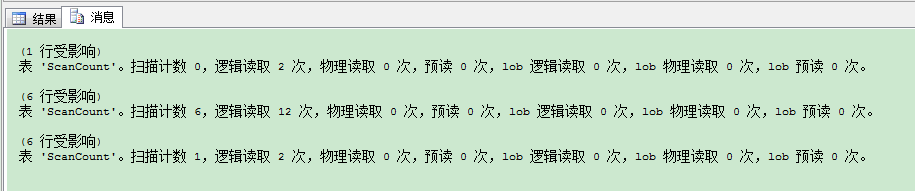
在第1个SELECT语句的输出里,扫描计数为0。这和MSDN里在线帮助“如果使用的索引是主键的唯一索引或聚集索引并且您仅查找一个值,则扫描计数为 0。”描述一致。因为它是唯一索引(聚集/非聚集索引),不需要在叶子层,进行进一步的向左或向右扫描,因为这里只有一个值来匹配。那也是在唯一索引上查找单一值,扫描计数为0的原因。扫描计数是1的话,会在非唯一索引(聚集或非聚集索引)上发生。
对于第2个SELECT语句,扫描计数是6.这是因为我们在找多个不同值。MSDN在线帮助对此有详细说明: “如果使用的索引是主键的唯一索引或非聚集索引,你在查找N个值,则扫描计数为N。”。
我们来看看执行计划里的SEEK谓语,将更清晰:

即使只有一个where条件,还是会分裂成多个谓语。对于每个SEEK谓语,它会生成1个扫描数。
对于最后一个SELECT语句,扫描计数为1,因为MSDN在线帮助说了: “当 N 为通过使用索引键定位键值后,在叶级别的左侧或右侧启动的不同查找/扫描数时,则扫描计数为 N。” 在叶子节点聚集索引结构用来找到1值后,叶子层的向左扫描开始,直到找到值6。我们看下执行计划里的SEEK 谓语,将更清晰:

逻辑读取(logical Read):
从数据缓存读取的页数。数字越小,性能越好。在性能调优中这个数字非常重要。因为它不会随着执行又执行而改变,除非数据或查询语句有变动。在进行性能调优时,这个可以作为性能提升的重要参考。
物理读取(physical reads):
从磁盘读取的页数。这个会随着执行又执行而改变。大多数情况下,连续第2次的执行时,它的物理读取值为0(可以参考上面连续查询的物理读取数变化)。
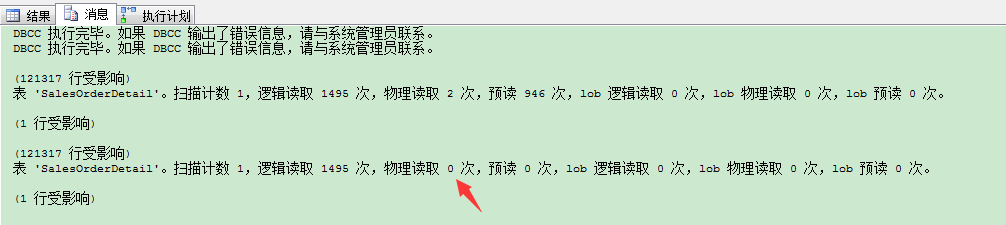
如果连续执行后,物理读取次数下降了,我们可以假定是服务器上内存使用配置的错误,或者服务器工作量饱和,有内存压力。你需要在服务器级别思考问题的原因。在查询调优时,这个数字不太重要,因为它一直在变,对于下降这个值,你不能对它做出太多控制。
预读 (read-ahead reads):
为进行查询而放入缓存的页数。这个值告诉我们物理页读取数,即SQL Server执行的,作为预读机制的一部分。在查询执行请求那些可能用到页之前,SQL Server把物理数据页读入缓存,用于完成接下来查询的页需要。
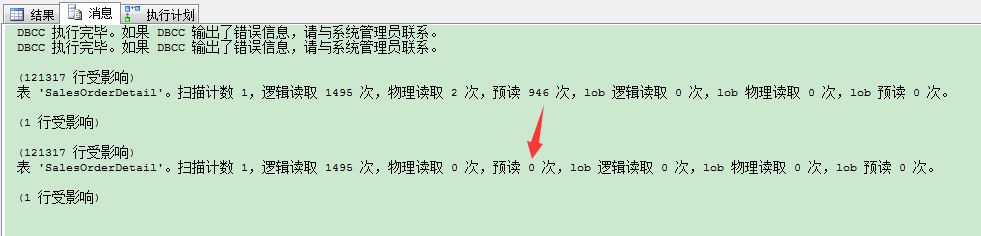
可以看到,物理读取是2次,预读是946次。这就是说,查询执行请求了2个页,并预读了946个页到数据缓存,SQL Server估计下次查询可能要用到这些页。和物理读取一样,这个值对在查询调优里并不重要。
lob 逻辑读取(lob logical reads):
从数据缓存读取的 text、ntext、image 或大值类型 (varchar(max)、nvarchar(max)、varbinary(max)) 页的数目。这个和逻辑读一样重要,我们要非常重视。
lob 物理读取(lob physical reads):
从磁盘读取的 text、ntext、image 或大值类型页的数目。
lob 预读(lob read-ahead reads):
为进行查询而放入缓存的 text、ntext、image 或大值类型页的数目。
总结下,逻辑读取和LOB逻辑读取是2个重要数值,在性能调优时,我们要重点围观。如果把这2个值调低,不在本文的讨论范围。通常创建合适的索引或重写查询可以帮助我们彻底降低这2个值。
参考文章:
注:此文章为WoodyTu学习MS SQL技术,收集整理相关文档撰写,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,有了您的支持才能激发作者更大的写作热情,非常感谢!
[转帖]性能调优:理解Set Statistics IO输出的更多相关文章
- 性能调优:理解Set Statistics IO输出
性能调优是DBA的重要工作之一.很多人会带着各种性能上的问题来问我们.我们需要通过SQL Server知识来处理这些问题.经常被问到的一个问题是:早上这个存储过程运行时间还是可以的,但到了晚上就很慢很 ...
- 性能调优之访问日志IO性能优化
性能调优之访问日志IO性能优化 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨询qq:908821 ...
- 性能调优3:硬盘IO性能
数据库系统严重依赖服务器的资源:CPU,内存和硬盘IO,通常情况下,内存是数据的读写性能最高的存储介质,但是,内存的价格昂贵,这使得系统能够配置的内存容量受到限制,不能大规模用于数据存储:并且内存是易 ...
- 性能调优:理解Set Statistics Time输出
在性能调优:理解Set Statistics IO输出我们讨论了Set Statistics IO,还有如何帮助我们进行性能调优.这篇文章会讨论下Set Statistics Time,它会告诉我们执 ...
- mysql监控、性能调优及三范式理解
原文:mysql监控.性能调优及三范式理解 1监控 工具:sp on mysql sp系列可监控各种数据库 2调优 2.1 DB层操作与调优 2.1.1.开启慢查询 在My.cnf文件中添加如 ...
- JVM | 第1部分:自动内存管理与性能调优《深入理解 Java 虚拟机》
目录 前言 1. 自动内存管理 1.1 JVM运行时数据区 1.2 Java 内存结构 1.3 HotSpot 虚拟机创建对象 1.4 HotSpot 虚拟机的对象内存布局 1.5 访问对象 2. 垃 ...
- [转帖]JVM性能调优详解
JVM性能调优详解 https://www.cnblogs.com/secbro/p/11833651.html 应该是 jdk8 以前的方法 貌似permsize 已经放弃这一块了. 前面我们学习了 ...
- 第0/24周 SQL Server 性能调优培训引言
大家好,这是我在博客园写的第一篇博文,之所以要开这个博客,是我对MS SQL技术学习的一个兴趣记录. 作为计算机专业毕业的人,自己对技术的掌握总是觉得很肤浅,博而不专,到现在我才发现自己的兴趣所在,于 ...
- 在SQL Server 2016里使用查询存储进行性能调优
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在 ...
- SQL Server调优系列基础篇 - 性能调优介绍
前言 关于SQL Server调优系列是一个庞大的内容体系,非一言两语能够分析清楚,本篇先就在SQL 调优中所最常用的查询计划进行解析,力图做好基础的掌握,夯实基本功!而后再谈谈整体的语句调优. 通过 ...
随机推荐
- DC-3
DC-3 前言:这个DC系列去年就做完了,但是因为那时候visualbox老崩搞得头大,一直漏了DC-3没做.现在重新搞好了来完结这个系列 扫存活的主机,显示只开了80 扫了一下目录,看了几个没有什么 ...
- CSS3学习笔记-字体属性
在CSS3中,可以使用字体属性来控制网页中文本的样式和排版.以下是常用的字体属性: font-family 该属性用于指定网页中的文本所使用的字体.我们可以通过使用通用的字体名称,或者直接使用字体名称 ...
- VEGA:诺亚AutoML高性能开源算法集简介
摘要:VEGA是华为诺亚方舟实验室自研的全流程AutoML算法集合,提供架构搜索.超参优化.数据增强.模型压缩等全流程机器学习自动化基础能力. 本文分享自华为云社区<VEGA:诺亚AutoML高 ...
- vue2升级vue3:getCurrentInstance—Composition api/hooks中如何获取$el
在vue2中,我们进程看到 this.$el 操作.但是在vue3 如何获取组件的当前 dom 元素呢? 可以利用 getCurrentInstance getCurrentInstance Vue ...
- Cesium球心坐标与本地坐标系经纬转换的数学原理—矩阵变换
之前整理过:<透析矩阵,由浅入深娓娓道来-高数-线性代数-矩阵>.<三维旋转笔记:欧拉角/四元数/旋转矩阵/轴角-记忆点整理>,这次转载 FuckGIS的<Cesium之 ...
- 32. 干货系列从零用Rust编写正反向代理,关于堆和栈以及如何解决stack overflow
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,七层负载均衡,内网穿透,后续将实现websocket代 ...
- Leaflet 使用图片作为地图
Leaflet 使用图片作为地图 关键代码: L.CRS.Simple.transformation = new L.Transformation(1, 0, 1, 0); // 坐标原点切换为左上角 ...
- 使用jasypt加密配置的时候,报错:DecryptionException: Unable to decrypt
前几天分享了一篇<Spring Boot 2.x基础教程:加密配置中的敏感信息> ,然后看到群里有小伙伴反应跟着这篇文章出现了这个异常com.ulisesbocchio.jasyptspr ...
- UVA - 10391:Compound Words (字符串水题)
题目大意 给定若干单词,按字典序输出由两个单词拼接而成的单词 思路分析 用set存储所有单词,枚举每个单词word,遍历word的所有左右子串组合情况,若左右子串均在set中,说明符合题意.时间复杂度 ...
- 阿里云蝉联 FaaS 领导者,产品能力获最高分
日前,权威咨询机构 Forrester 发布 The Forrester Wave: Functions-As-A-Service Platforms, Q2 2023.阿里云凭借函数计算的产品能力在 ...