[转帖]堆表&索引组织表
堆表&索引组织表 https://zhuanlan.zhihu.com/p/487271927
很多大佬强调学习一定要看"原版英文材料"。
比如再google搜索堆表和索引组织表,可以看到很多中文加工的材料,比如下面:

实际你随便翻几篇,会发现由于作者的水平限制,整体都讲的云里雾里,导致用户看完更迷茫...(我觉得与其中文材料各种生拉硬扯, 为何不把原版材料翻译出来)。
我摘抄几个英文官网的材料来看,直观感受下官方文档的质量:
堆表结构
堆表的材料pg官方文档做的不错(阿里云polar-o也是堆表结构,图表也不错,适合墙内用户(橘黄色))比如:
堆表文件格式
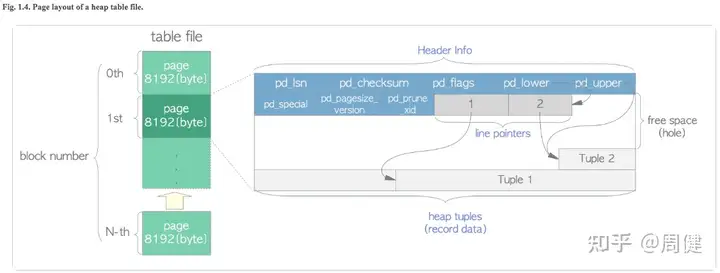
pg
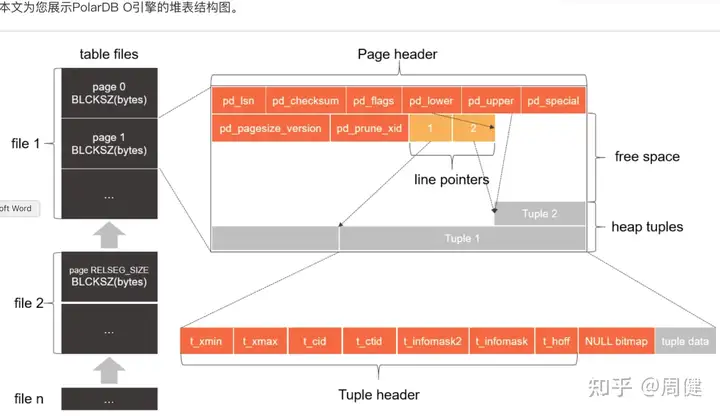
polar-o
堆表数据插入
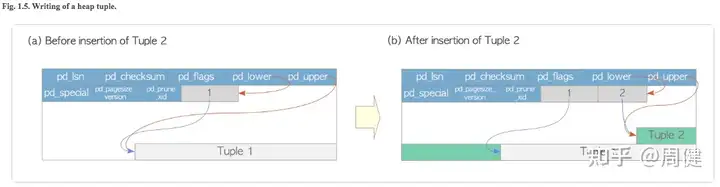
pg

polar-o
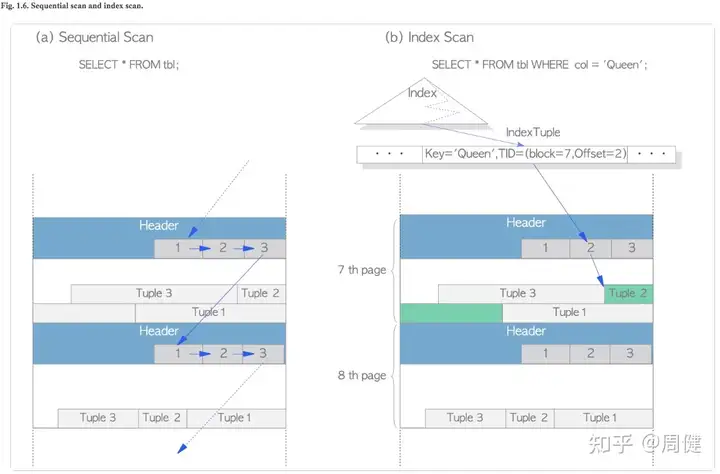
堆表数据查找
索引组织表
索引组织表的材料Jeremy Cole关于innodb材料非常经典做的不错(git图标库)。
innodb的概念里,一切文件皆索引,下面直观体验下:
btree整体结构
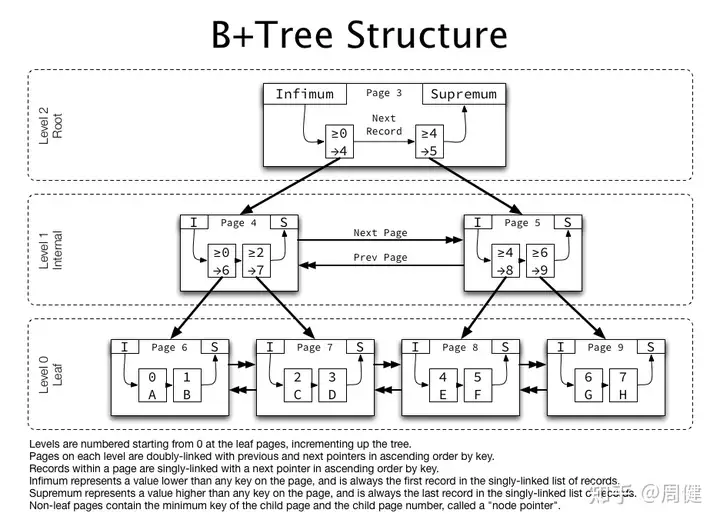
btree由page组成,page对应文件中一个16kb片段
Page内部详情
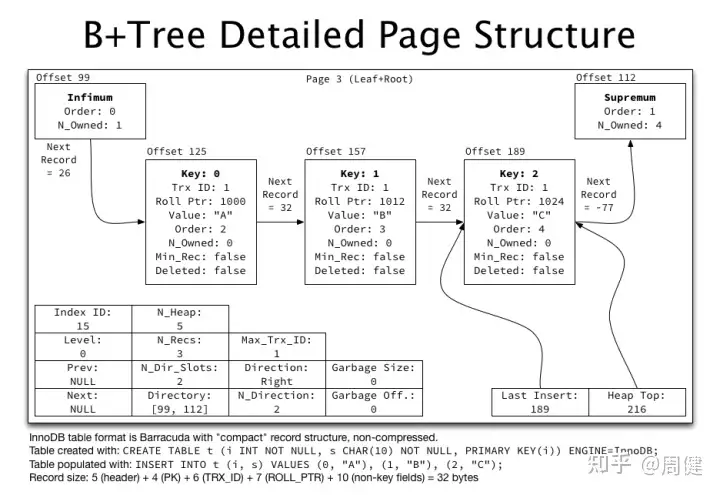
page内部结构图形化展示
Page内部二级索引详情
上图中page内部单链表组成,并且key实际上不一定物理上有序。为了高效再page内进行查找,引入Page Directory Structure,大概4个record组成一个slot,page内record性能可以提升4倍,如下:
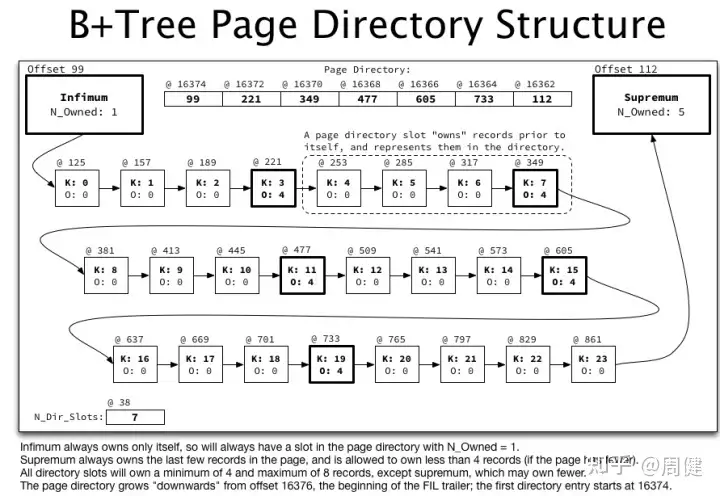
内存索引和文件的关系:
上面是从内存或者逻辑角度看索引组织表,实际在用户进行CRUD操作时,会涉及到内存page树和索引文件file的分配和回收等复杂逻辑,该逻辑可以通过下图来描述:
- tree -> 文件页面管理
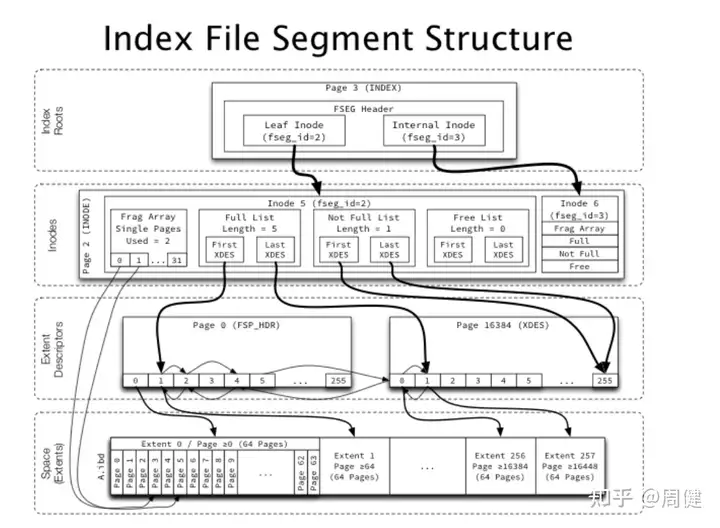
- 一个索引由一个root page节点来描述,启动时从ibdata的数据词典表中load元数据信息,其中SYS_INDEXES系统表中记录了表,索引及索引根页对应的page no(
DICT_FLD__SYS_INDEXES__PAGE_NO),进而找到btree根page。找到根page后,通过其page header结构(见Page内部详情图左下角部分)PAGE_BTR_SEG_LEAF、PAGE_BTR_SEG_TOP两个字段可以定位出该索引的叶子和非叶子fseg;这样整个btree和fseg、extent、page的关系都建立起来了。
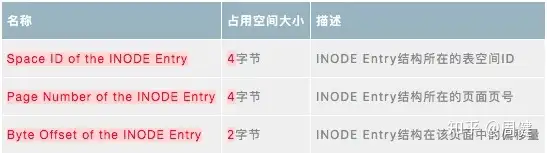
PAGE_BTR_SEG_TOP 和PAGE_BTR_SEG_LEAF结构
- root节点的所有内部节点和所有叶子节点分别由两个fseg段组成(效率原因,分别让叶子层和内部节点的物理page集中再一起)
- 每个fseg内部包含很多extent(和表实际大小相关)和32个碎片page数组(来承载最初的数据512KB的数据),每个extent1M包含64个page(16k),为了保证访问效率,一般分配空间按段为单位,但为了减少小表空间浪费。
上图中对于一个索引,会有两个fsegment段,每个对应下图标红的结构,再该索引crud的过程中,会通过其内部的FRAG_ARR来管理小数据量,通过FSET_xx来管理extent。
但是如果其FSET_FREE为空,此时就需要从全局FSP的FSP_XXX链表获取文件级别的extent空间,这部分由表头存储并通过FSP_HEADER来进行管理,见下图:
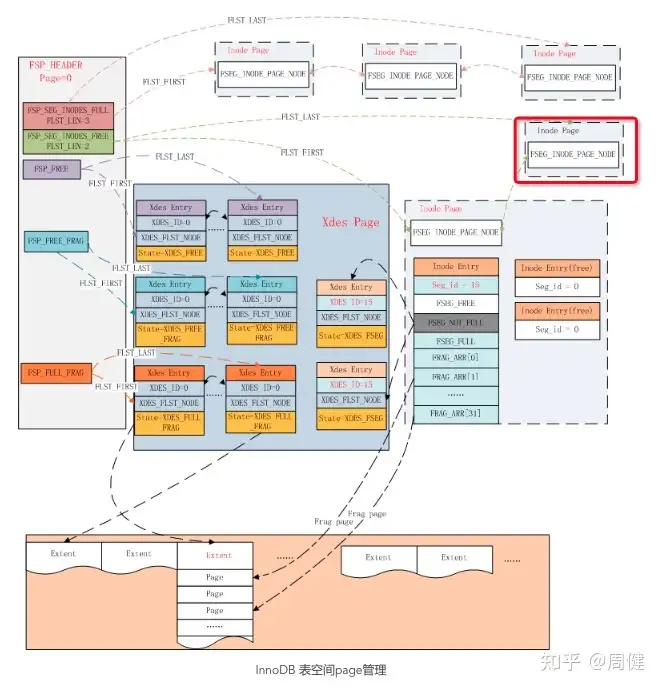
- 关于inode page:
- 由File Space Header的两个指针进行全局管理,每一项为一个inode类型的page 16KB。
- 每个inode page包含85个inode entry,每个inode entry对应一个file segment;
- 每个索引需要使用两个file segment,每个file segment对应32个琐碎page和extent链表,构成tree主体结构
索引文件布局
上面可以看到inode、file segment、extent、page等概念,其和文件物理布局之间的关系如下:
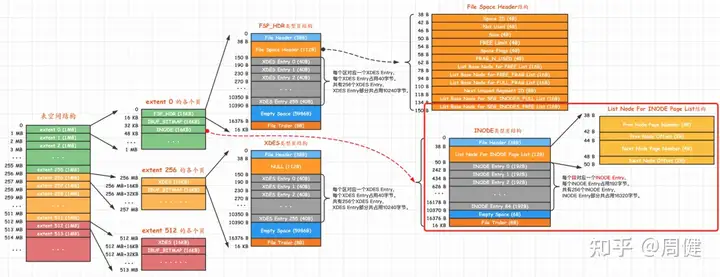
- 物理文件整体上按照粒度分为三类:
- page:文件切分基础单位,一个page 16KB
- extent:为了避免page粒度太细导致tree查找随机io问题,连续的64个page 组成一个extent,1M空间
- group: 文件角度的逻辑概念,对应512个extent,实际没有使用。
- 关于表大小
- page id为4字节,所以一个文件承载的page数为4G,容量为64TB(4GB * 16K)
- 文件级别当前使用空间:
- 通过File Space Header.Free Limit来描述当前文件有效初始化的边界。
- fseg是从tree的角度引申出逻辑概念。用来管理extent。物理文件层面并没有fseg的概念,fset管理的大小可以为整个文件,最大64TB;fset和group都是逻辑概念,没有关系更没有一一对应的关系。
参考
[转帖]堆表&索引组织表的更多相关文章
- mysql之索引组织表
1.二叉树/平衡树.B-tree.B+tree.B*tree 树:最上一层是根节点.最底下一层是叶子节点.(一般左边节点小于右边节点) 二叉树:每个节点最多只能有两个分支,一般只用于教材.二叉树的深度 ...
- 聚集索引、非聚集索引、聚集索引组织表、堆组织表、Mysql/PostgreSQL对比、联合主键/自增长、InnoDB/MyISAM(引擎方面另开一篇)
参考了多篇文章,分别记录,如下. 下面是第一篇的总结 http://www.jb51.net/article/76007.htm: 在MySQL中,InnoDB引擎表是(聚集)索引组织表(cluste ...
- 4. 跟踪标记 (Trace Flag) 610 对索引组织表(IOT)最小化日志
跟踪标记:610 功能: 用批量导入操作(Bulk Import Operations)加载数据时,对于索引组织表(即有聚集索引的表) 最小化日志: 上图为simple/bulk-logged恢复模式 ...
- MySQL InnoDB 索引组织表 & 主键作用
InnoDB 索引组织表 一.索引组织表定义 在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT). 在Inno ...
- Oracle数据库 查看表是否是 索引组织表的方法
1. 最近在工作过程中发现 一个表插入很慢 以为是索引组织表, 所以一直有点纠结 但是发现 产品里面是没有IOT的 于是找了下公司的OCP 问了下 如何查看 就是 user_tables 视图里面的一 ...
- 【oracle11g,18】存储结构:暂时表,手工条带化,表/索引迁移表空间,删除表,外部表
一. 暂时表 暂时表放在暂时表空间,不生成redo,仅仅有undo. 在暂时表中能够创建索引.视图及触发器,还能够使用"Export and Import(导出和导入)"或&quo ...
- (转)Mysql技术内幕InnoDB存储引擎-表&索引算法和锁
表 原文:http://yingminxing.com/mysql%E6%8A%80%E6%9C%AF%E5%86%85%E5%B9%95innodb%E5%AD%98%E5%82%A8%E5%BC% ...
- MySQL技术内幕InnoDB存储引擎(表&索引算法和锁)
表 4.1.innodb存储引擎表类型 innodb表类似oracle的IOT表(索引聚集表-indexorganized table),在innodb表中每张表都会有一个主键,如果在创建表时没有显示 ...
- MySQL表结构,表空间,段,区,页,MVCC
索引组织表(IOT表):为什么引入索引组织表,好处在那里,组织结构特点是什么,如何创建,创建IOT的限制LIMIT. IOT是以索引的方式存储的表,表的记录存储在索引中,索引即是数据,索引的KEY为P ...
- MySQL表结构,表空间,段,区,页,MVCC ,undo 事务槽
索引组织表(IOT表):为什么引入索引组织表,好处在那里,组织结构特点是什么,如何创建,创建IOT的限制LIMIT. IOT是以索引的方式存储的表,表的记录存储在索引中,索引即是数据,索引的KEY为P ...
随机推荐
- SQL语句(mysql)「一」
SQL的一些常用语句 创建类 CREAT DATABASE <数据库名>; 该方法创建一个数据库,当要使用一个数据库的时候,使用指令: USE <数据库名>; 查看当前正在使用 ...
- P7112 【模板】行列式求值
学<高等代数>第二章的时候过来搜了搜模板,结果真搜到了.于是水一篇题解. 本文部分内容来自<高等代数>. 行列式定义 对于一个 \(n\) 阶行列式 \[A_{n \times ...
- LeetCode 947. 移除最多的同行或同列石头 并查集
传送门 思路 干货太干就不太好理解了,以下会有点话痨( ̄▽ ̄)" 首先题目给了一个二维stones数组,存储每个石子的坐标,因为在同行或者同列的石子最终可以被取到只剩下一个,那么我们将同行同 ...
- row_number函数的不稳定性
本文分享自华为云社区<row_number函数的不稳定性>,作者: nullptr_ . row_number为窗口函数,用来为各组内数据生成连续排号 基础用法 postgres=# se ...
- Win10 企业版激活方法
如果大家想要激活 Win10的企业版,可以依次执行下面的命令,分别表示安装win10企业版密钥,设置kms服务器,激活win10企业版;slmgr /ipk NW6C2-QMPVW-D7KKK-3GK ...
- MQTT(EMQX) - Linux CentOS Docker 安装
MQTT(EMQX) - Linux CentOS 直接安装 和 Docker 安装 常规安装 下载文件 版本选择:https://www.emqx.com/zh/downloads/broker/ ...
- ORM执行SQL 双下划线查询 ORM外键字段创建 外键字段相关操作 ORM跨表查询 跨表查询进阶操作
目录 ORM执行SQL语句 方式1:使用pymysql模块 方式2:使用raw方法 方式3:django connection 双下划线查询 __gt(>) __lt(<) queryse ...
- RTS超低延时直播技术:保障大型赛事直播零时差互动
2022卡塔尔世界杯呼啸而来. 11月20日开幕,28天赛期.64场比赛,国际足联主席因凡蒂诺预计,卡塔尔世界杯将吸引全球50亿观众,可以说2022卡塔尔世界杯是这个冬天当之无愧的「超级流量场」. 世 ...
- Python报错:AttributeError: type object 'str' has no attribute '_name_'(机器学习实战treePlotter代码)解决方案
错误信息: 学习<机器学习实战>这本书时,按照书上的代码运行,产生了错误,但是在代码中没有错误提示,产生错误的代码如下: if type(secondDict[key])._name_ = ...
- vivo平台化实践探索之旅-平台产品系列01
vivo 互联网平台产品研发团队- Yang Yang 本篇为<vivo 平台产品>系列文章的第1篇.主要描述在业务高速发展的背景下,vivo软件工程师通过系统平台化建设等手段,逐步解决软 ...