论文阅读:A new approach solve the multi-product multi-period inventory lot sizing with supplier selection problem
论文:A new approach solve the multi-product multi-period inventory lot sizing with supplier selection problem
期刊:Computer & Operations Research
1. 模型建立:具有供应商选择问题的多产品多周期库存批量确定
1.1 问题定义
将具有供应商选择问题的多产品多周期库存批量问题正式定义如下:
假设计划周期有限,市场需求已知且有多种产品,每种产品可以由一组供应商提供(比如:在某个计划期内,一种产品可以在一个或多个供应商处采购)
在每个周期向供应商下订单时,会产生供应商订购成本(supplier ordering cost)
对于每个周期,若产品在一整个周期内都在仓库中,则会产生库存持有成本(product holding cost)
假设不允许缺货,且库存大小没有限制
1.2 考虑供应商选择问题的多产品多周期库存批量的混合整数线性规划模型
符号说明
下标
\(i=1,2,3,\dots,I\) 产品的索引
\(j=1,2,3,\dots,J\) 供应商的索引
\(t=1,2,3,\dots,T\) 计划周期的索引
参数
\(D_{it}=\)产品\(i\)在周期\(t\)的需求
\(P_{ij}=\)产品\(i\)从供应商\(j\)处购买的采购价格
\(H_i=\)产品\(i\)在每个周期的持有成本
\(O_{j}=\)供应商\(j\)的订货成本
决策变量
\(X_{ijt}=\)在周期\(t\)产品\(i\)从供应商\(j\)处订购的批量
\(Y_{jt}=\begin{cases}1&\text{if 在周期t向供应商j下订单}\\0&\text{otherwise}\end{cases}\)
混合整数线性规划模型(MILP)的建立
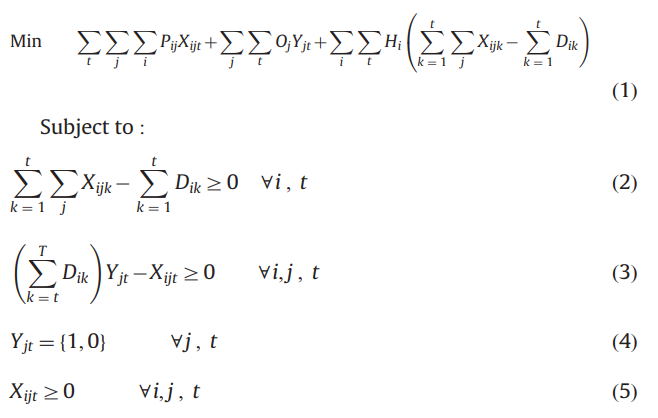
(1):目标函数为买方的总成本,即总采购成本+总订货成本+总库存持有成本
(2):为防止缺货发生,对于各个周期内的各个产品,在该周期前(包括该周期)的总订购量必须大于或等于在该周期前(包括该周期)的总需求量
(3):对于每个周期,每个产品必须先向对应的供应商下单才能订购,约束条件(3)确定了在不收取相应订购成本的情况下下订单是不可能的,即\(Y_{jt}=0\)时,该约束不成立。(我觉得这个设置很巧妙,因为当\(Y_{jt}=1\)时,对应周期和产品在供应商\(j\)处的订购量不会超过后面周期中该产品的总需求量,也就是说这条约束还同时限制了\(D_{ik}\)的求解范围)
(4)、(5):决策变量取值范围约束
由于这个问题是一个NP难问题,当实例较大时问题会变得无法解决。该模型通过商业整数线性规划求解器在非常小的实例大小下求解到最优性。对于现实世界中常见的大尺寸实例,该问题无法最优解决。
2.基于减少与优化方法(reduce and optimize approach, ROA)求解具有供应商选择的多产品多周期库存批量问题
本节提出了一种启发式算法,用于求解多产品多周期库存批量与供应商选择问题的混合整数线性规划(MILP)。
加强数学公式的一种方法是在模型中添加有效的不等式。因此,通过包括以下有效不等式(6),进一步加强了上面刚刚提出的数学公式(1)~(5):
\]
该不等式对周期\(t\)使用的供应商总数施加了边界。尽管不等式(6)对上述模型来说是多余的,但有助于帮助CPLEX创建一些新的cuts。
作者发现,式(6)对优化过程有积极影响,特别是在求解质量和时间上。
2.1 Reduce and optimize approach (ROA)
减少和优化方ROA的解释如下。ROA是基于原始问题建立一个减小的可行域(ruduce feasible region) 并对其进行优化。尽管在大多数情况下,ROA不能确保最优性,但它可以在合理的时间内获得接近最优的解。尽管如此,如果手头问题的最优解对于减小问题是可行的,那么ROA保证了最优解。从根本上讲,ROA在以下声明中列出:
\(B_C:\)整个数学模型中的二进制变量集合(假设有\(n\)个二进制变量\(y_1,y_2,\dots,y_n\))
\(B_O:\)在未知最优解中,二进制变量等于1的集合
\(B_R:\)约简集合(reduce set),包含了部分的二进制变量
要求上述集合满足条件:\(B_O\subseteq{B_R}\subseteq{B_C}\)
显然,ROA的挑战是获得集合\(B_R\),使得\(B_R\)是集合\(B_C\)的子集,并且覆盖集合\(B_O\)。然后ROA使用商业MIP求解器(如CPLEX)在减小的可行空间\(B_R\)上重复优化问题。换句话说,将不在集合\(B_R\)中的二进制变量固定为等于0(即\(y_i=0\)当且仅当\(y_i\in{B_C-B_R}\))。
至关重要的是,在某些情况下,ROA找不到好的解决方案。这些情况是:
① 当集合\(B_R\)仅包含集合\(B_O\)的一部分时
② 当集合\(B_R\)和\(B_O\)不相交时。
此外,值得一提的是,具有最优解的集合\(B_O\)总是不确定的。
ROA基本上由四个阶段组成:
第一阶段构建了一个可行的变量约简集(初始集\(B_R\))。
第二阶段在约简的变量集中优化数学模型。
第三阶段选择要包括在约简的变量集中的新变量。
第四阶段细化约简的数学模型,然后进入第二阶段。
这里,有一些方法可以构造初始集合\(B_R\):
① 随机创建初始集合\(B_R\)
② 在短时间内求解问题的完全模型,然后使用其现有解(即,在现有解决方案中等于1的变量形成集合\(B_R\))
③ 求解问题的一个LP松弛并使用其最优解(即,在最优LP松弛解中等于1的变量形成集合\(B_R\))
④ 用启发式方法解决问题以构造初始集合\(B_R\)
⑤ 以上方式的组合
在本文中,ROA的第三阶段是迭代地增强集合\(B_R\)。该任务可以通过从先前解决的约简问题的解决方案中获取信息来执行。这里,为了提高\(B_R\),建议获得不在集合\(B_R\)中的变量的降低成本(reduce cost)。然后在\(B_R\)上重新优化问题,直到满足停止条件,或者(在最小化问题中)没有发现更多的负降低成本。
值得一提的是,二进制变量的降低成本是无法确定的。然而,可以容易地求解LP松弛,然后获得不在集合\(B_R\)中的变量的降低的成本。然后,具有负降低成本的变量需要包括在集合\(B_R\)中。为了防止集合\(B_R\)在每次改进迭代中持续增长时达到不可管理的大小,集合\(B_R\)中降低成本大于或等于零的变量从集合中删除。此外,还建立了要添加到集合\(B_R\)的变量的最大数量。
值得一提的是,存在几种流行的算法,用于解决类似于多产品多周期库存批量与供应商选择问题的问题。其中一些是基于遗传算法(GA)、粒子群优化(PSO)、蚁群优化(ACO)、分散搜索(SS)、差分进化(DE)等。这些算法有一组候选解,并且它们迭代地改进解的集合。相反,减少和优化方法(ROA)总是考虑一个小的二进制变量集,并在这个集上优化问题。这是其他流行算法(GA、PSO、ACO、SS、DE)和ROA的主要区别。
2.2 一种基于ROA的启发式算法
在这一小节中,提出了一种启发式算法。启发式算法中使用了以下缩写:RedMILP、RelaxMILP、max-nva、nvnrc、LBvar和UBvar。
RedMILP是MILP模型,但当优化问题在一组二进制变量(\(Y_{jt}\))上求解时。
RelaxMILP是一个松弛的MILP模型,其中所有二进制变量都是松弛的。
max-nva表示要添加到集合\(B_R\)中的最大变量数。
nvnrc表示成本为负的变量数。
\(LB_{var}\)和\(UB_{var}\)表示决策变量\(Y_{jt}\)的下界和上界。
\(Y^{WW}_{jt}\)表示Wagner–Whitin[23]算法找到的解。上标WW对应Wagner–Whitin的首字母缩写。
\(Y^S_{jt}\)中的上标\(S\)表示“解”。
\(Y^c_{jt}\)中上标\(C\)对应“连续”;这是当二进制变量被放宽为取连续值时。
\(RCY_{jt}\)表示变量\(Y^c_{jt}\)的降低成本。
需要指出的是,公式模型总是包含约束(2)、(3)、(4)、(5)和所提出的有效不等式(6)。解决过程由以下算法中显示的伪代码描述:

上述启发式算法的工作原理如下。
Step 1. 初始集是应用Wagner–Whitin[23]算法构建的。在这一步骤中,目标是从哪个供应商\(j\)和在哪个时间段\(t\)购买产品,不需要确定批量。换言之,Wagner–Whitin[23]算法仅用于确定初始集\(B_R\)中必须包括哪些二进制变量(即\(Y_{jt}\))。
Step 2. 从优化问题的初始可行集\(B_R\)开始,求解\(β\)时间单位的RedMILP模型。如果\(clock<\tau\),则转到Step 3。否则,算法停止并返回现有的解决方案。
Step 3. 一旦求解了RedMILP,则确定现有解的每个二进制变量(\(Y^S_{jt}\))的值,并将在Step 4中使用该值。
Step 4. 利用所有二进制变量的值,构建连续变量集,将下限和上限设置为Step 3中获得的相应值
Step 5. 在这里,一个称为RelaxMILP的代理问题(surrogate problem)得到了解决。此操作是指用于确定Step 4中定义的每个变量的reduce cost的策略。
Step 6. 在该步骤中,如果没有更多具有负降低成本(negative reduce costs)的变量添加到\(B_R\),则算法停止并返回现有解决方案。否则,可以在Step 7中增强集合\(B_R\)。
Step 7. 现在,集合\(B_R\)改进如下:如果nvnrc<max-nva,则将nvnrc变量添加到集合\(B_R\)。否则,将具有最大负降低成本的max-nva变量添加到设置\(B_R\)。返回Step 2。
正如大多数启发式算法的典型情况一样,必须定义一些参数。在该算法中,需要确定初始集\(B_R\)和以下参数的值:\(β\)、\(τ\)和max-nva。用于\(β\)、\(τ\)和max-nva的值分别为8分钟、30分钟和400。很明显,在非常大的情况下,negative reduce cost的变量数量也是一个很大的数字。因此,至关重要的是,考虑到具有10000个二进制变量的最大实例的大小,建立变量的最大数量(max-nva)。max-nva的值设置为最大实例中二进制变量总数的4%。
论文阅读:A new approach solve the multi-product multi-period inventory lot sizing with supplier selection problem的更多相关文章
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 【论文阅读】Motion Planning through policy search
想着CSDN还是不适合做论文类的笔记,那里就当做技术/系统笔记区,博客园就专心搞看论文的笔记和一些想法好了,[]以后中框号中间的都算作是自己的内心OS 有时候可能是问题,有时候可能是自问自答,毕竟是笔 ...
- 分布式多任务学习论文阅读(四):去偏lasso实现高效通信
1.难点-如何实现高效的通信 我们考虑下列的多任务优化问题: \[ \underset{\textbf{W}}{\min} \sum_{t=1}^{T} [\frac{1}{m_t}\sum_{i=1 ...
- Ensemble learning A survey 论文阅读
Ensemble learning A survey是2018年发表的一篇关于集成学习的综述性论文 发展 在Surowiecki的书中The Wisdom of Crowds,当符合以下标准时,大众的 ...
- Learning under Concept Drift: A Review 概念漂移综述论文阅读
首先这是2018年一篇关于概念漂移综述的论文[1]. 最新的研究内容包括 (1)在非结构化和噪声数据集中怎么准确的检测概念漂移.how to accurately detect concept dri ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
随机推荐
- String--getline()
#include <string> #include <sstream> #include <iostream> int main() { std::wstring ...
- ASCII编码的影响与作用:数字化时代的不可或缺之物
一.ASCII编码的起源 ASCII(American Standard Code for Information Interchange)编码是一种最早用于将字符转换为数字的编码系统.它诞生于20世 ...
- mybatis处理集合、数组参数使用in查询
对于mybatis的参数类型是集合数组的时候进行查询. 第一种:参数list ,使用mybatis的标签 1 SELECT * FROM TABLE_NAME AS a WHERE 2 3 a.id ...
- java+mysql实现的公益管理系统
一功能 1.管理员的登录 2.公益项目的增删改查 3.负责人的增删改查 4.捐款人的增删改查 5.志愿者增删改查 二界面展示 1.欢迎界面 2.登录界面 3.系统首页 4.项目管理 5.负责人管理 6 ...
- 简化Simulink的建模与模型重构
简化Simulink的建模与模型重构 模型重构 Simulink作为汽车和自动化领域中经典的模型工程必备工具,不管是专业的汽车控制器的开发还是自动化控制的专业应用编程,都会使用到Simulink进行图 ...
- 【Azure 存储服务】使用PowerShell脚本创建存储账号(Storage Account)的共享访问签名(SASToken) : New-AzStorageContainerSASToken
问题描述 使用PowerShell脚本如何来创建存储账号(Storage Account)的共享访问签名呢?查询到可以使用 New-AzStorageContainerSASToken 命令来生成Az ...
- 单词本z ctrl shift alt - tr踩踏 shi流出 al不同
单词本z ctrl shift alt ctrl = control = 控制 con = com = 一起 tr- = 踩 踏 - 原始印欧语形式为 *der- contra = 相对,相反(一起踩 ...
- Dreamweaver基础教程:系列介绍
目录 前言 Dreamweaver 软件介绍 软件安装 学习支持 相关资料 前言 我一直对前端的一些技术比较感兴趣,之前有用过GitHub上的开源项目部署了自己的导航网站猿导航,但并没有系统的去深入学 ...
- Docker 部署GitLabs 版本升级 13.9.x -> 15.3.x
Gitlabs版本升级大版本不能直接跳级升级, 可以参考官方的升级路径.本人是从13.9.x需要升级到最新的15.3.x. 参考官方路径结合自己的实际情况成功升级. 13.9.0 -> 13.1 ...
- KTL 最新版
K,K线,Candle蜡烛图. T,技术分析,工具平台 L,公式Language语言使用c++14,Lite小巧简易. 项目仓库:https://github.com/bbqz007/KTL Core ...