OUT了吧,Kafka能实现消息延时了
摘要:本文讲述如何在保存Kafka特有能力的情况下给Kafka扩充一个具有能处理延时消息场景的能力。
本文分享自华为云社区《Kafka也能实现消息延时了?》,作者:HuaweiCloudDeveloper 。
1、背景
Kafka是一个拥有高吞吐、可持久化、可水平扩展,支持流式数据处理等多种特性的分布式消息流处理中间件,采用分布式消息发布与订阅机制,在日志收集、流式数据传输、在线/离线系统分析、实时监控等领域有广泛的应用,Kafka它虽有以上这么多的应用场景和优点,但也具备其缺陷,比如在延时消息场景下,Kafka就不具备这种能力,因此希望能在保存Kafka特有能力的情况下给Kafka扩充一个具有能处理延时消息场景的能力。
2、开发环境

3、云服务介绍
分布式消息服务Kafka版: 华为云分布式消息服务Kafka版是一款基于开源社区版Kafka提供的消息队列服务,向用户提供计算、存储和带宽资源独占式的Kafka专享实例。使用华为云分布式消息服务Kafka版,资源按需申请,按需配置Topic的分区与副本数量,即买即用,您将有更多精力专注于业务快速开发,不用考虑部署和运维。
4、方案设计
i、方案简述
此方案实现,需要借助两个Topic来进行实现,一个Topic用于及时接收生产者们所产生的消息,另一个Topic则用于消费者拉取消息进行消费。另外在这两个Topic之间加上一个队列用于做延时的逻辑判断,如果消息满足了延时的条件,则将队列中的消息生产至我们的消费者需要拉取的Topic中。
ii、方案架构图
Kafka消息延时方案架构图

Kafka消息延时实现思路
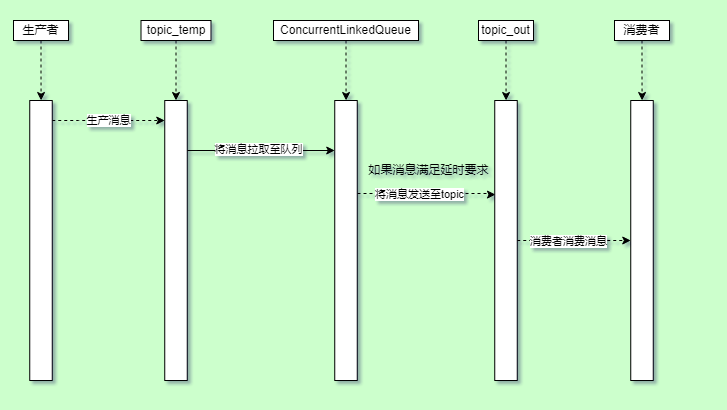
- 生产者将生产消息存入topic_delay主题中进行存储。
- 将topic_delay主题中的所有消息拉取至ConcurrentLinkedQueue队列中。
- 取值判断是否满足延时要求。
a. 如果满足延时要求,则将消息生产至topic_out主题中,并将queue队列中的值移除。
b. 如果不满足延时要求,则等待自定义时间后重试判断。 - 消费者最终从topic_out主题中拉取消息进行消费。
iii、方案时序图
Kafka消息延时方案时序图
5、代码参数指南
本项目中起到延时作用的类Delay.java其余类为官方提供用于测试生产和消费消息,如需使用官方测试的使用的生产消费代码相关配置介绍可以参考https://support.huaweicloud.com/devg-kafka/how-to-connect-kafka.html 。 如需使用自己配置的生产者消费者,只配置Delay.java中的参数即可。
Delay.java参数详情
- delay:自定义延时时间,单位ms。
- topic_delay变量:用于临时存储消息的topic名称。
- topic_out变量:用于消费者拉取消息消费的topic名称。
- 关于消费者和生产者配置可按需配置,可参考Kafka官方文档:https://kafka.apache.org/documentation/#producerconfigs
6、代码实现
实现代码可参考Kafka消息延时
package com.dms.delay; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord; import java.time.Duration;
import java.util.Arrays;
import java.util.Date;
import java.util.Properties;
import java.util.concurrent.ConcurrentLinkedQueue; /**
* Hello world!
*
*/
public class Delay { //缓存队列
public static ConcurrentLinkedQueue<ConsumerRecord<String, String>> link = new ConcurrentLinkedQueue();
//延迟时间(20秒),可根据需要设置延迟大小
public static long delay = 20000L; /**
*入口
* @param args
*/
public static void main( String[] args )
{
//延时主题(用于控制延时缓冲)
String topic_delay = "topic_delay";
//输出主题(直接供消费者消费)
String topic_out = "topic_out";
/*
消费线程
*/
new Thread(new Runnable() {
@Override
public void run() {
//消费者配置。请根据需要自行设置Kafka配置
Properties props = new Properties();
props.setProperty("bootstrap.servers", "192.168.0.59:9092,192.168.0.185:9092,192.168.0.4:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//指定消费主题
consumer.subscribe(Arrays.asList(topic_delay));
while (true) {
//轮询消费
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10));
//遍历当前轮询批次拉取到的消息
for (ConsumerRecord<String, String> record : records){
System.out.println(record);
//将消息添加到缓存队列
link.add(record);
}
}
}
}).start();
/*
生产线程
*/
new Thread(new Runnable() {
@Override
public void run() {
//生产者配置(请根据需求自行配置)
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.0.59:9092,192.168.0.185:9092,192.168.0.4:9092");
props.put("linger.ms", 1);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//创建生产者
Producer<String, String> producer = new KafkaProducer<>(props);
//持续从缓存队列中获取消息
while(true){
//如果缓存队列为空则放缓取值速度
if(link.isEmpty()){
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
//获取缓存队列栈顶消息
ConsumerRecord<String, String> record = link.peek();
//获取该消息时间戳
long timestamp = record.timestamp();
Date now = new Date();
long nowTime = now.getTime();
if(timestamp+ Delay.delay <nowTime){
//获取消息值
String value = record.value();
//生产者发送消息到输出主题
producer.send(new ProducerRecord<String, String>(topic_out, "",value));
//从缓存队列中移除该消息
link.poll();
}else {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}).start();
}
}
7、结果反馈
OUT了吧,Kafka能实现消息延时了的更多相关文章
- ActiveMQ笔记(6):消息延时投递
在开发业务系统时,某些业务场景需要消息定时发送或延时发送(类似:飞信的短信定时发送需求),这时候就需要用到activemq的消息延时投递,详细的文档可参考官网说明,本文只介绍二种常用的用法: 注:本文 ...
- Kafka介绍与消息队列
消息队列的好处: 消息队列(Message Queue) 消息: 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列:一种特殊的线性表(数据元素首尾相接),特殊之 ...
- Kafka与常见消息队列的对比
Kafka与常见消息队列的对比 RabbitMQ Erlang编写 支持很多的协议:AMQP,XMPP, SMTP, STOMP 非常重量级,更适合于企业级的开发 发送给客户端时先在中心队列排队.对路 ...
- Kafka设计解析(十六)Kafka 0.11消息设计
转载自 huxihx,原文链接 [原创]Kafka 0.11消息设计 目录 一.Kafka消息层次设计 1. v1格式 2. v2格式 二.v1消息格式 三.v2消息格式 四.测试对比 Kafka 0 ...
- Kafka中的消息是否会丢失和重复消费(转)
在之前的基础上,基本搞清楚了Kafka的机制及如何运用.这里思考一下:Kafka中的消息会不会丢失或重复消费呢?为什么呢? 要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费 ...
- RabbitMq(7)消息延时推送
应用场景 目前常见的应用软件都有消息的延迟推送的影子,应用也极为广泛,例如: 淘宝七天自动确认收货.在我们签收商品后,物流系统会在七天后延时发送一个消息给支付系统,通知支付系统将款打给商家,这个过程持 ...
- Kafka作为分布式消息系统的系统解析
Kafka概述 Apache Kafka由Scala和Java编写,基于生产者和消费者模型作为开源的分布式发布订阅消息系统.它提供了类似于JMS的特性,但设计上又有很大区别,它不是JMS规范的实现,如 ...
- RabbitMQ,RocketMQ,Kafka 几种消息队列的对比
常用的几款消息队列的对比 前言 RabbitMQ 优点 缺点 RocketMQ 优点 缺点 Kafka 优点 缺点 如何选择合适的消息队列 参考 常用的几款消息队列的对比 前言 消息队列的作用: 1. ...
- RabbitMQ,RocketMQ,Kafka 事务性,消息丢失和消息重复发送的处理策略
消息队列常见问题处理 分布式事务 什么是分布式事务 常见的分布式事务解决方案 基于 MQ 实现的分布式事务 本地消息表-最终一致性 MQ事务-最终一致性 RocketMQ中如何处理事务 Kafka中如 ...
- Kafka笔记--指定消息的partition规则
参数的设定:参考资料 不错的资料:http://blog.csdn.net/honglei915/article/details/37697655 http://developer.51cto.com ...
随机推荐
- 9.17 多校联测 Day3 总结
全程罚坐场. 模拟赛考试状态持续低迷,为明天的状态感到深深担忧. <题目并不难,请喧哗的同学不要大声 AK>,离谱. 不保证按难度顺序排序,尝试改变策略.开始第 1h 将四道题通读一遍并做 ...
- 推荐一款“自学编程”的宝藏网站!详解版~(在线编程练习,项目实战,免费Gpt等)
云端源想学习平台,一站式编程服务网站云端源想官网传送门 精品课程:由项目实战为导向的视频课程,知识点讲解配套编程练习,让初学者有方向有目标. 课程阶段:每门课程都分多个阶段进行,由浅入深,很适合零基础 ...
- 字符串匹配|kmp笔记
很久之前学的了. 我很懒,不太喜欢画图. 做个笔记回忆一下: kmp 朴素比对字符串 所谓字符串匹配,是这样一种问题:"字符串 T 是否为字符串 S 的子串?如果是,它出现在 S 的哪些位置 ...
- 一文概览NLP句法分析:从理论到PyTorch实战解读
关注TechLead,分享AI全维度知识.作者拥有10+年互联网服务架构.AI产品研发经验.团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI ...
- 生成ios证书最简单的方法
使用了hbuilderx的uniapp来开发app很方便,但是官网的文档,生成ios的私钥证书却需要使用mac电脑来生成,假如没有mac电脑就无法使用教程的方法来生成ios证书. 因为hbuilder ...
- fileinclude
这里的话需要注意几个点 cookie中的变量赋值不适用冒号而是等于号 如果后面有路径的话就直接写文件名就好了,不用写后缀
- 将ECharts图表插入到Word文档中
@ 目录 在后端调用JS代码 准备ECharts库 生成Word文档 项目地址 库封装 本文示例 EChartsGen_DocTemplateTool_Sample 如何通过ECharts在后台生成图 ...
- Pandas 分组聚合操作详解
Pandas 是 Python 中用于数据分析的重要工具,它提供了丰富的数据操作方法.在数据分析过程中,经常需要对数据进行分组聚合操作.本文将介绍 Pandas 中的数据分组方法以及不同的聚合操作,并 ...
- 【Android】Android Bmob后端云配置
简介 开发一个具有网络功能的应用,在Bmob移动应用云存储平台中,只需要注册一个账号,就可以实现申请创建任意多个数据库,获得对应的key,下载对应版本的SDK,并嵌入到移动应用中,调用存取的KPI,进 ...
- Google Colab 现已支持直接使用 🤗 transformers 库
Google Colab,全称 Colaboratory,是 Google Research 团队开发的一款产品.在 Colab 中,任何人都可以通过浏览器编写和执行任意 Python 代码.它尤其适 ...