架构设计|基于 raft-listener 实现实时同步的主备集群
背景以及需求
- 线上业务对数据库可用性可靠性要求较高,要求需要有双 AZ 的主备容灾机制。
- 主备集群要求数据和 schema 信息实时同步,数据同步平均时延要求在 1s 之内,p99 要求在 2s 之内。
- 主备集群数据要求一致
- 要求能够在主集群故障时高效自动主备倒换或者手动主备倒换,主备倒换期间丢失的数据可找回。
为什么使用 Listener
Listener:这是一种特殊的 Raft 角色,并不参与投票,也不能用于多副本的数据一致性。
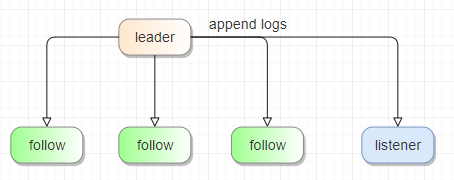
原本的 NebulaGraph 中的 Listener 是一个 Raft 监听器,它的作用是将数据异步写入外部的 Elasticsearch 集群,并在查询时去查找 ES 以实现全文索引的功能。
这里我们需要的是 Listener 的监听能力,用于快速同步数据到其他集群,并且是异步的执行,不影响主集群的正常读写。
这里我们需要定义两个新的 Listener 类型:
- Meta Listener:用于同步表结构以及其他元数据信息
- Storage Listener:用于同步 storaged 服务的数据
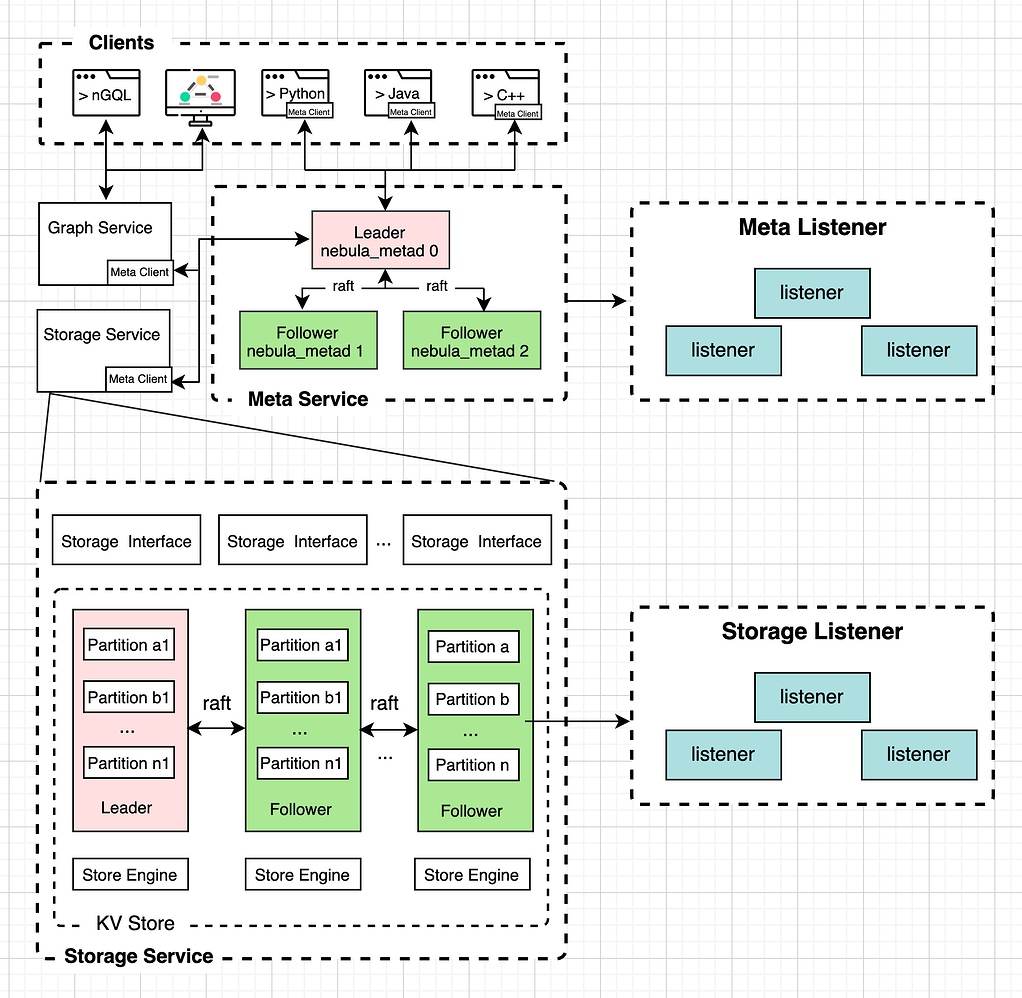
这样 storaged 服务和 metad 服务的 part leader 节点接受到写请求时,除了同步一份数据给 follower 节点,也会同步一份给各自的 listener 节点。
备集群如何接受数据?
现在我们面临几个问题:
- 两个新增 Listener 在接收到 leader 同步的日志后,应该如何再同步给备集群?
- 我们需要匹配和解析不同的数据操作,例如添加点、删除点、删除边、删除带索引的数据等等操作;
- 我们需要将解析到的不同操作的数据重新组装成一个请求发送给备集群的 storaged 服务和 metad 服务;
通过走读 nebula-storaged 的内核代码我们可以看到,无论是 metad 还是 storaged 的各种创建删除表结构以及各种类型数据的插入,最后都会序列化成一个 wal 的 log 发送给 follower 以及 listener 节点,最后存储在 RocksDB 中。
因此,我们的 listener 节点需要具备从 log 日志中解析并识别操作类型的能力,和封装成原请求的能力,因为我们需要将操作同步给备集群的 metad 以及 storaged 服务。
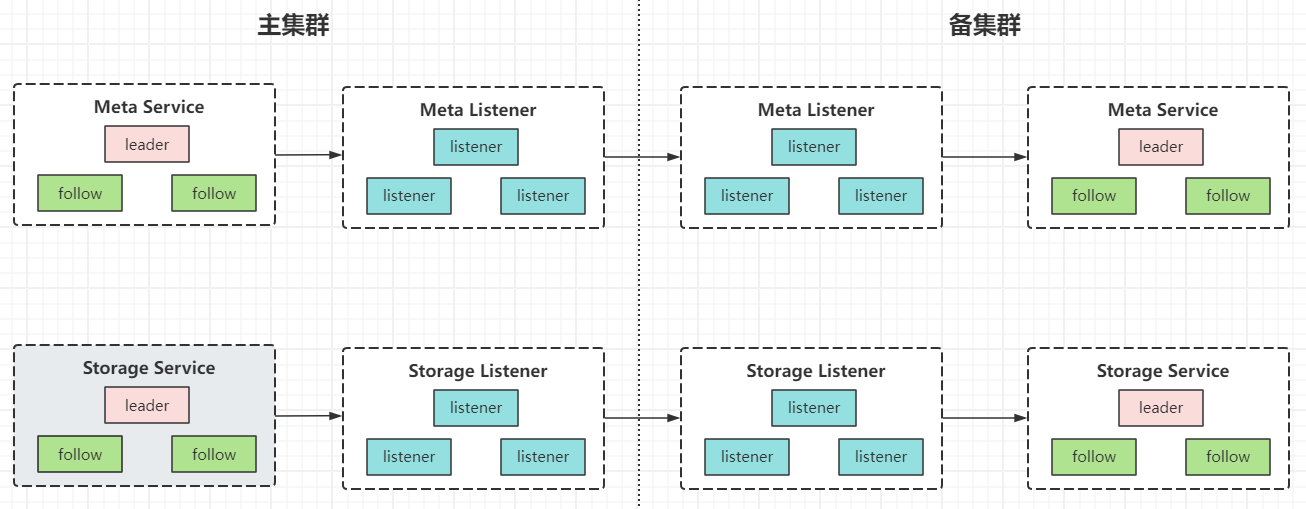
这里涉及到一个问题,主集群的 listener 需要如何感知备集群?备集群 metad 服务的信息以及 storaged 服务的信息?从架构设计上来看,两个集群之间应该有一个接口通道互相连接,但又不干涉,如果由 listener 节点直接发送请求给备集群的 nebula 进程,两个集群的边界就不是很明显了。所以这里我们再引入一个备集群的服务 listener 服务,它用于接收来自主集群的 listener 服务的请求,并将请求转发给自己集群的 metad 以及 storaged 服务。
这样做的好处。两边集群的服务模块是对称的,方便我们后面快速地做主备切换。
Listener 节点的管理和可靠性
为了保证双 AZ 环境的可靠性,很显然 Listener 节点也是需要多节点多活的,在 nebula 内核源码中是有对于 listener 的管理逻辑,但是比较简单,我们还需要设计一个 ListenerManager 实现以下几点能力:
- listener 节点注册以及删除命令
- listener 节点动态负载均衡(尽量每个 space 各个 part 分布的 listener 要均匀)
- listener 故障切换
节点注册管理以及负载均衡都比较简单好设计,比较重要的一点是故障切换应该怎么做?
listener 故障切换的设计
listener 节点故障切换的需求可以拆分为以下几个部分:
- listener 同步 wal 日志数据时周期性记录同步的进度(commitId && appendLogId);
- ListenerManager 感知到 listener 故障后,触发动态负载均衡机制,将故障 listener 的 part 分配给其他在运行的 listener;
- 分配到新 part 的 listener 们获取原先故障 listener 记录的同步进度,并以该进度为起始开始同步数据;
至于 listener 同步 wal 日志数据时周期性记录同步的进度应该记录到哪里?可以是存储到 metad 服务中,也可以存储到 storaged 服务对应的 part 中。
nebula 主备切换设计
在聊主备切换之前,我们还需要考虑一件事,那就是双 AZ 环境中,应该只能有主集群是可读可写的,而其他备集群应该是只读不能写。这样是为了保证两边数据的最终一致性,备集群的写入只能是由主集群的 listener 请求来写入的,而不能被 graphd 服务的请求写入。
所以我们需要对集群状态增加一种“只读模式”,在这种只读模式下,表明当前集群状态是处于备集群的状态,拒绝来自 graphd 服务的写操作。同样的,备集群的 listener 节点处在只读状态时,也只能接收来自主集群的请求并转发给备集群的进程,拒绝来自备集群的 wal 日志同步。
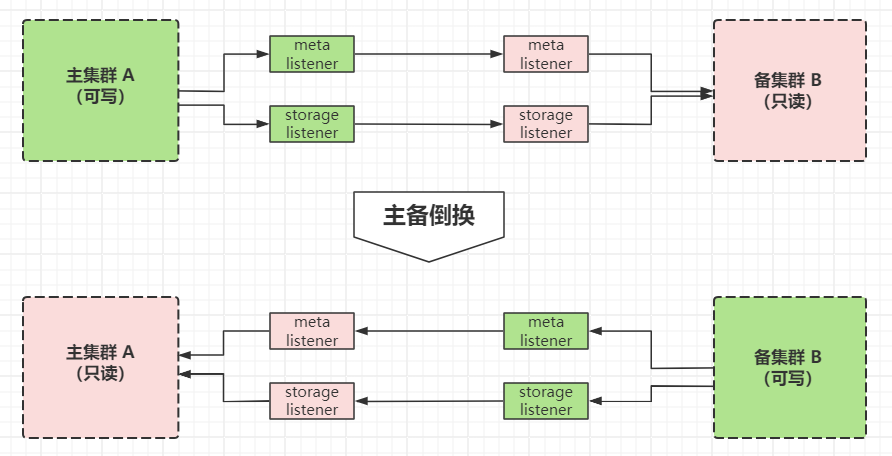
主备倒换发生时,需要有以下几个动作:
- 主集群的每个 listener 记录自己所负责的 part 的同步进度(commitId && appendLogId);
- 备集群的 nebula 服务转换为可写;
- 备集群的 listener 节点转换为可写,并且开始接收来自自己集群的 metad 和 storaged 进程的 wal 日志;
- 主集群的 listener 以及各个服务转换为只读状态,开始接收来自新的主集群的数据同步请求;
这几个动作细分下来,最主要的内容就是状态转换以及上下文信息保存和同步,原主集群需要保存自己主备切换前的上文信息(比如同步进度),新的主集群需要加载自己的数据同步起始进度(从当前最新的 commitLog 开始)
主备切换过程中的数据丢失问题
很明显,在上面的设计中,当主备切换发生时,会有一段时间的“双主”的阶段,在这个阶段内,原主集群的剩余日志已经不能再同步给备集群了,这就是会被丢失的数据。如何恢复这些被丢失的数据,可能的方案有很多,因为原主集群的同步进度是有记录的,有哪些数据还没同步完也是可以查询到的,所以可以手动或者自动去单独地同步那一段缺失数据。
当然这种方案也会引入新的问题,这段丢失地数据同步给主集群后,主集群会再次同步一遍回现在的备集群,一段 wal 数据的两次重复操作,不知道为引起什么其他的问题。
所以关于主备切换数据丢失的问题,我们还没有很好的处理方案,感兴趣的伙伴欢迎在评论区讨论。
感谢你的阅读 (///▽///)
对图数据库 NebulaGraph 感兴趣?欢迎前往 GitHub 查看源码:https://github.com/vesoft-inc/nebula;
想和其他图技术爱好者一起交流心得?和 NebulaGraph 星云小姐姐 交个朋友再进个交流群;
{kind=link}
架构设计|基于 raft-listener 实现实时同步的主备集群的更多相关文章
- 基于uReplicator复制的kafka主备集群间的切换策略
一.概述 目前基于中间件uReplicator实现了kafka集群间的迁移复制,可以实现跨区.跨云的kafka集群间复制同步,也可以实现kafka集群的冷热互备架构:在实现集群间同步以后,需要解决一个 ...
- 实时计算框架:Flink集群搭建与运行机制
一.Flink概述 1.基础简介 Flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算.Flink被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算.主要特性包 ...
- 基于 Clusternet 与 OCM 打造新一代开放的多集群管理平台
背景 随着 5G.物联网设备的爆炸性增长以及智能终端不断增强的计算能力,带来了前所未有的数据量,传统的中心集中式计算捉襟见肘."新基建"战略的实施,工业互联网.车联网/自动驾驶.智 ...
- 基于RHCS的web双机热备集群搭建
基于RHCS的web双机热备集群搭建 RHCS集群执行原理及功能介绍 1. 分布式集群管理器(CMAN) Cluster Manager.简称CMAN.是一个分布式集群管理工具.它执行在集群的各个节 ...
- Spark运行模式_基于YARN的Resource Manager的Custer模式(集群)
使用如下命令执行应用程序: 和"基于YARN的Resource Manager的Client模式(集群)"运行模式,区别如下: 在Resource Manager端提交应用程序,会 ...
- 架构设计 | 基于电商交易流程,图解TCC事务分段提交
本文源码:GitHub·点这里 || GitEE·点这里 一.场景案例简介 1.场景描述 分布式事务在业务系统中是十分常见的,最经典的场景就是电商架构中的交易业务,如图: 客户端通过请求订单服务,执行 ...
- 架构设计 | 基于Seata中间件,微服务模式下事务管理
源码地址:GitHub·点这里 || GitEE·点这里 一.Seata简介 1.Seata组件 Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务.Seata将为用 ...
- 基于sersync海量文件实时同步
项目需求:最近涉及到数百万张图片从本地存储迁移到云存储,为了使完成图片迁移,并保证图片无缺失,业务不中断,决定采用实时同步,同步完后再做流量切换.在实时同步方案中进行了几种尝试. 方案1:rsync+ ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- MHA-结合MySQL半同步复制高可用集群(Centos7)
目录 一.理论概述 本案例部署思路 二.环境 三.部署 部署MHA 部署二进制包MySQL及部署主从复制 部署半同步复制 配置MHA MHA测试 部署lvs+keepalived(lvs1,lvs2) ...
随机推荐
- 适用于AbpBoilerplate的阿里云腾讯云Sms短信服务
Sms 适用于AbpBoilerplate的短信服务(Short Message Service,SMS)模块,通过简单配置即可使用,仅更改一处代码即可切换短信服务提供商. Aliyun.Sms由阿里 ...
- 解决windows11远程连接阿里云Centos7
本地连接CentOs7时报错 Permission denied (publickey,gssapi-keyex,gssapi-with-mic). 网上大部分说的是去修改 vim /etc/ss ...
- vim技巧--提取文本与文本替换
前几天遇到一个使用情景,需要从一个包含各个读取代码文件路径及名字的文件中把文件路径提取出来,做一个filelist,这里用到了文本的提取和替换,这里做个小总结记录一下. 从网上找了一个作者写的代码用来 ...
- Edge 语音识别 生成文字 显示在input new webkitSpeechRecognition()
Edge 语音识别 生成文字 显示在input new webkitSpeechRecognition() 代码 <html> <head> <style> bod ...
- vscode 利用正则 搜索标签 tags (?=.*关键字1)(?=.*关键字2).*
vscode 利用正则 搜索标签 (?=.关键字1)(?=.关键字2).* 这里关键词是可以多个并且不按照顺序搜索的,就是写起来需要 (?=.关键字) 最后. 结尾 我是不是需要制作一个转换的小工具呢 ...
- python 判断bytes是否相等的几种方法
一 前言: python判断bytes是否相等,一般要用到这几种方法:is,==,operator.下面做几个例子让大家看一下. 二 正文: 1 相等方法: test1=b'0xab' test2=b ...
- GdbServer和libuuid移植到HISI3520d
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 修复华硕笔记本fn+f2在ubuntu下wifi不能够正常使用和WiFi Disabled (Hard-blocked) (译文)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文发布于 2014-12-22 11:49:16 ...
- awk第一天
awk第一天 1.用awk 打印整个test.txt (以下操作都是用awk工具实现,针对test.txt) awk '{print}' test.txt [root@master ~]# awk ' ...
- 记录--从AI到美颜全流程讲解
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 美颜和短视频 美颜相关APP可以说是现在手机上的必备的软件,例如抖音,快手,拍出的"照骗"和视频不加美颜效果,估计没有 ...