Scikit-learn从入门到放弃
前置建议阅读:
Scikit-learn简介
Sklearn:官方文档https://scikitlearn.com.cn/0.21.3/
Scikit-learn(也称sklearn)是基于Python编程语言的机器学习工具,是简单高效的数据挖掘和数据分析工具,它建立在NumPy、SciPy和matplotlib等库的基础上,可在各种环境中重复使用。其基本功能主要被分为六大部分:分类、回归、聚类、数据降维、模型选择以及数据预处理。
(1) 分类:识别给定对象的所属类别,属于监督学习的范畴,常见的应用场景包括图像识别等。目前Scikit-learn已经实现的算法包括:支持向量机(SVM)、最近邻、逻辑回归、随机森林、决策树以及多层级感知器(MLP)神经网络等。
(2) 回归:预测与给定对象相关联的连续值属性,常见的应用场景包括客流预测等。目前Scikit-learn已经实现了以下算法:支持向量回归(SVR)、Lasso回归、贝叶斯回归、随机森林回归等。Scikit-learn实现的回归算法几乎涵盖了开发者的各种需求范围,并且还为各种算法提供简单的实例参考。
(3) 聚类:与分类不同,聚类是对给定对象根据相似特征进行分组集合,属于无监督学习的范畴,最常见的应用包括车站聚类、轨迹数据聚类、出租车上下客点聚类等。目前Scikit-learn实现的算法包括:K-means聚类、谱聚类、层次聚类以及DBSCAN聚类等。
(4) 数据降维:当样本数量远少于样本的特征数量时,或特征数量过多导致计算量过大,特征稀疏性过于严重时,往往需要进行特征降维,例如使用主成分分析(PCA)、非负矩阵分解(NMF)或特征选择等降维技术来减少要考虑的随机变量个数,其主要应用场景包括图片处理等。
(5) 模型选择:对于给定的参数和模型,比较、验证和选择哪个模型的效果最好,其主要目的是通过设置不同的参数来运行模型,进而通过结果选择最优参数以提升最终的模型精度。目前Scikit-learn实现的模块包括:格点搜索,交叉验证和各种针对预测误差评估的度量函数。
(6) 数据预处理:数据的特征提取和归一化,通常是机器学习过程中的第一个也是最重要的一个环节,可以大大提高学习的效率。其中,特征提取是指将文本或图像数据转换为可用于机器学习的数字变量。通过去除不变、协变或其他统计上不重要的特征量来改进机器学习,提高学习的精确度的一种方法。归一化是指将输入数据转换为具有零均值和单位权方差的新变量,但因为大多数时候都做不到精确等于零,因此会设置一个可接受的范围,一般都要求落在0-1之间。
Scikit-learn搭建了一套完整的用于数据预处理、数据降维、特征提取和归一化的算法(模块),同时它针对每个算法和模块都提供了丰富的参考案例和说明文档。可以通过Sklearn的官方文档(中文版)进行查看学习。
SVM分类
SVM(Support Vector Machines),支持向量机是一种二分类模型,其基本模型定义为特征空间上间隔最大的线性分类器。它将实例的特征向量映射为空间中的一些点,其目的就是画出一条线,以便区分两类点,以至如果以后有了新的点,这条线也可以做出很好的分类。该算法适合中小型数据样本、非线性、高维的分类问题。在所有知名的数据挖掘算法中,SVM是最准确、最高效的算法之一,属于二分类算法,可以支持线性和非线性的分类。
Sklearn中的SVM算法库封装了libsvm和liblinear的实现,仅仅重写了算法的接口部分,使用时直接调用即可。SVM将算法库分为了两类,一类是分类的算法库,主要包含LinearSVC、NuSVC和SVC三种算法,另一类是回归算法类,包含SVR、NuSVR和LinearSVR三种算法。关于各种算法的具体使用可以看官方文档,官方文档有着非常详细的讲解。
下面以一个简单的二分类案例对Sklearn中SVM的使用进行简单示范,具体过程如下:
首先构造数据集,数据集包含正类和负类,均服从正态分布,且每个类的元素个数均为(200,2),不同处在于正类的中心点为(2,2),负类的中心点为(0,0)。接着给数据集分别贴上标签,正类标签为1,负类标签为0,并将正负类按行合并成同一个数据集。
import numpy as np
from sklearn import svm
import pandas as pd
import matplotlib.pyplot as plt
# 正类,服从(0,1)的正态分布
p = np.random.randn(200, 2)
for i in range(200):
p[i][0] += 2
p[i][1] += 2
# 负类,服从(0,-1)的正态分布
f = np.random.randn(200, 2)
# 将np数组转换成dataframe
df_p = pd.DataFrame(p, columns=['x', 'y'])
# 加上标签z,正类标签为1
df_p['z'] = 1
# 负类标签为0
df_f = pd.DataFrame(f, columns=['x', 'y'])
df_f['z'] = 0
# 将正负类合并成一个dataframe(按行进行合并)
con = pd.concat([df_p,df_f],axis=0)
print(con)

数据集构造好以后可以划分训练集和测试集,共有400个数据,取其中250个数据点作为训练集,150个点作为测试集。接着规定训练集的特征和标签,并进行分类训练:通过svm接口直接新建SCM分类器,对分类器进行训练,得到训练好的参数以及测试集上的准确率。
# 重置数据集索引
con.reset_index(inplace=True, drop=True)
# 划分训练集和测试集
test_size = 150
train_data = con[:-test_size]
test_data = con[-test_size:]
# 选择训练集特征和标签
X = train_data[['x', 'y']]
Z = train_data['z']
# 新建SCV分类器
clf = svm.SVC(kernel='linear')
# 训练
clf.fit(X,Z)
# 在训练集上的准确率
clf.score(X, Z)
# 训练好的参数: coefficients:类别特征向量,Intercept:判别函数类别参数
print('Coefficients: %s \n\nIntercept %s' % (clf.coef_, clf.intercept_))
# 在测试集上的准确率
print('\n\nScore: %.2f' % clf.score(test_data[['x','y']], test_data['z']))
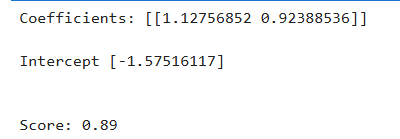
经过模型训练,返回相关参数及模型准确率如表所示:
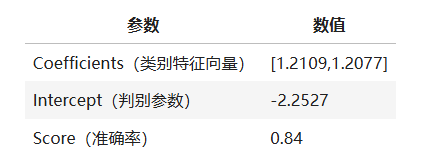
随机森林回归
随机森林是一种由多个决策树构成的集成算法,在分类和回归问题上都有不错的表现。在解释随机森林以前,需要简单介绍一下决策树。决策树是一种很简单的算法,解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法。
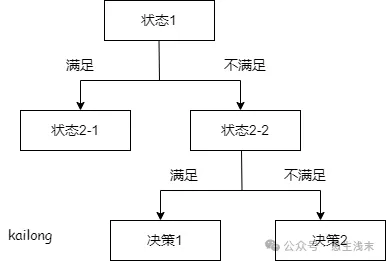
随机森林就是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,森林的每棵决策树分别进行判断分类,每个决策树会得到一个自己的分类结果,分类结果中哪一个分类最多,随机森林就会把这个结果当作最终结果。 随机森林作为解决分类、回归问题的集成算法,具有以下的优点:
(1) 对于大部分资料,可以产生高准确度的分类器;
(2) 可以处理大量的输入变量;
(3) 随机性的引入,不容易过拟合;
(4) 能处理离散型和连续性数据,无需规范化。
同样,在利用随机森林解决分类、回归问题时,也存在以下的缺点:
(1) 在某些噪音较大的分类或回归问题上会过拟合;
(2) 同一属性,有不同取值的数据中,取值划分较多的属性会对随机森林产生更大的影响,在该类数据上产出的属性权值是不可信的;
(3) 森林中的决策树个数很多时,训练需要的时间和空间会较大。
以北京西直门地铁站的进站客流数据为例,通过sklearn的随机森林算法对客流进行预测,更好地理解sklearn的基本使用方法。
首先利用Pandas导入西直门地铁站每15min的进站客流量,并且利用matplotlib绘制客流曲线图。具体代码如下:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
# 导入西直门地铁站点15min进站客流
df = pd.read_csv('./xizhimen.csv', encoding="gbk", parse_dates=True)
len(df)
df.head() # 观察数据集,这是一个单变量时间序列
plt.figure(figsize=(15, 5))
plt.grid(True) # 网格化
plt.plot(df.iloc[:, 0], df.iloc[:, 1], label="XiZhiMen Station")
plt.legend()
plt.show()
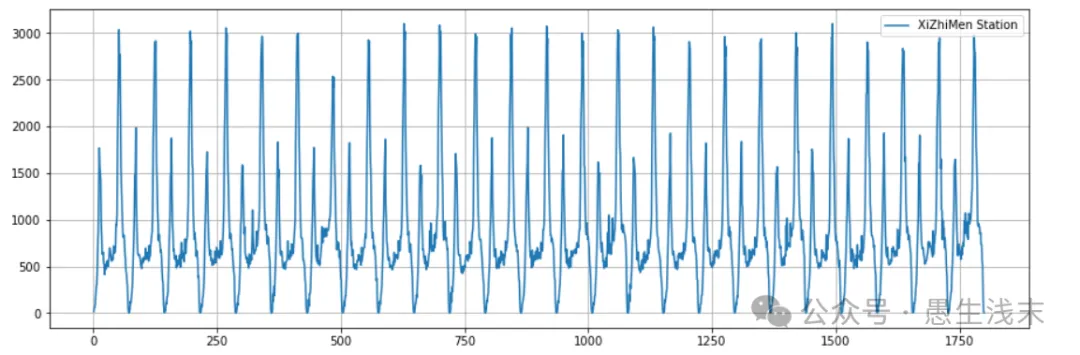
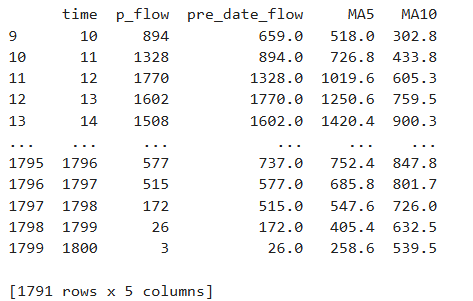
考虑到客流量大小受先前客流影响,此处新增该时刻地铁客流的前一个15min客流量、该时刻前五个15min的平均客流量以及前十个15min的平均客流量,以此提高客流预测的准确率,同时删除异常数据NULL的所在行,避免影响预测。取数据集的80%作为训练集,20%作为测试集。具体代码如下:
# 增加前一天的数据
df['pre_date_flow'] = df.loc[:, ['p_flow']].shift(1)
# 5日移动平均
df['MA5'] = df['p_flow'].rolling(5).mean()
# 10日移动平均
df['MA10'] = df['p_flow'].rolling(10).mean()
df.dropna(inplace=True)
X = df[['pre_date_flow', 'MA5', 'MA10']]
y = df['p_flow']
X.index = range(X.shape[0])
X_length = X.shape[0]
split = int(X_length * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
print()
接着需要对随机森林模型进行拟合,由于sklearn已经将实现随机森林回归的相关函数进行封装,因此只需要通过接口调用相关函数就可以进行回归预测。预测得到结果以后,利用matplotlib对预测结果进行可视化。具体代码如下:
random_forest_regressor = RandomForestRegressor(n_estimators=15)
# 拟合模型
random_forest_regressor.fit(X_train, y_train)
score = random_forest_regressor.score(X_test, y_test)
result = random_forest_regressor.predict(X_test)
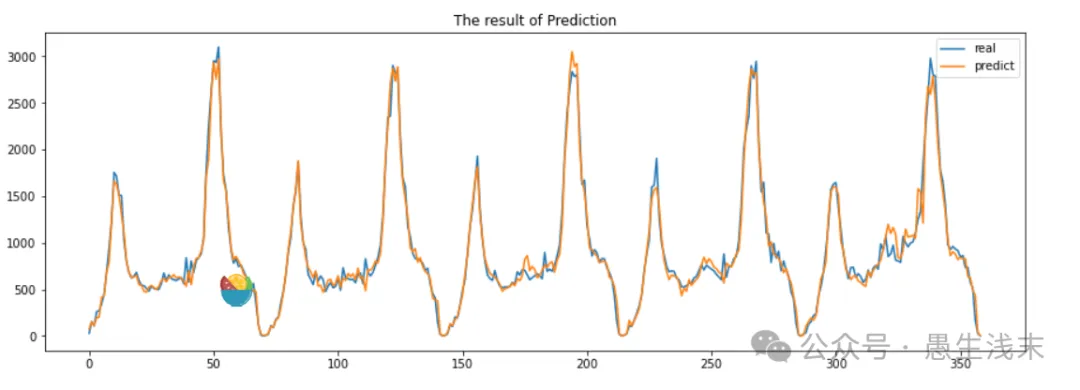
plt.figure(figsize = (15, 5))
plt.title('The result of Prediction')
plt.plot(y_test.ravel(), label='real')
plt.plot(result, label = 'predict')
plt.legend()
plt.show()
K-means聚类
聚类分析:将大量数据中具有“相似”特征的数据点或样本划分为一个类别。
与分类、序列标注等任务不同,聚类是在事先并不知道任何样本标签的情况下,通过数据之间的内在关系把样本划分为若干类别,使得同类别样本之间的相似度高,不同类别样本之间的相似度低(簇内差异小,簇间差异大)。聚类模型建立在无类标记的数据上,是一种非监督的学习算法,相对于监督学习,蕴含了巨大的潜力与价值。 K-means聚类是无监督学习的杰出代表之一,是最基础常用的聚类算法,基于点与点之间的距离相似度来计算最佳类别归属。它的基本思想是:通过迭代寻找K个簇(Cluster)的一种划分方案,使得聚类结果对应的损失函数最小。其中损失函数定义为各个样本距离所属簇中心点的误差平方和。
在sklearn中,为了方便使用,将K-means算法的实现进行打包封装,在需要使用该算法进行聚类分析时,直接调用即可。下面以北京地铁进站客流数据向读者展示如何使用sklearn中的K-means算法。
首先通过Pandas导入北京地铁站点15min进站客流数据,接着对数据进行预处理,删除NULL值所在行的数据,删除“Station_name”列,仅仅保留每个车站的15min进站客流数据。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
# 导入北京地铁站点15min进站客流
df = pd.read_csv('./in_15min.csv', encoding="gbk", parse_dates=True)
len(df)
df.dropna(inplace=True) # 首先去除空值所在的行
x_data = df.drop('Station_name', axis=1) # 以列为单位,删除'Station_name'列
接着需要确定K值,此处基于簇内误差平方和,使用肘方法确定簇的最佳数量(即K值),其基本理念就是找出聚类偏差骤减的K值,以此确定最优聚类数。通过画出不同K值的聚类偏差图可以清楚看出。具体代码如下:
# 肘方法看K值
d = []
for i in range(1, 15):
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=300, random_state=0)
km.fit(x_data)
d.append(km.inertia_) # inertia簇内误差平方和
plt.plot(range(1, 15), d, marker='o')
plt.xlabel('number of clusters')
plt.ylabel('distortions')
plt.show()
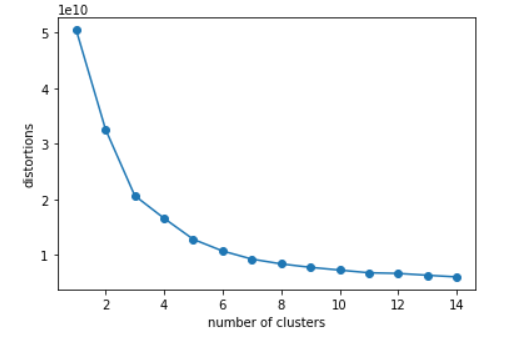
由聚类偏差图可以看出,K值取6较为合适,或根据需要,取大致聚类结果即可。
调用sklearn的KMeans算法,根据客流进站数据对车站类别进行聚类,并返回聚类结果。至于聚类效果的评价指标,此处选择了两个较为常见的指标:轮廓系数以及c&h得分,判断聚类效果的好坏。具体代码如下:
# 从效果图可以看出,K取6最合适
model_kmeans = KMeans(n_clusters=6, random_state=0)
model_kmeans.fit(x_data)
y_pre = model_kmeans.predict(x_data)
y_pre += 1
print('聚类结果为:' + str(y_pre))
# 评价指标
silhouette_s = metrics.silhouette_score(x_data, y_pre, metric = 'euclidean')
calinski_harabaz_s = metrics.calinski_harabasz_score(x_data, y_pre)
print('轮廓系数为:%.2f,c&h得分为:%d' % (silhouette_s, calinski_harabaz_s))

该模型的评价指标如模型评价指标表所示:
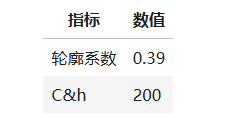
聚类所追求的是对于每个簇而言,其簇内差异小,簇外差异大。轮廓系数S正是描述簇内外差异的关键指标,取值范围为[-1, 1],当S越接近于1,聚类效果越好;越接近-1,聚类效果越差。该模型的轮廓系数为0.39,说明聚类效果良好。至于c&h分数,被定义为组间离散于组内离散的比率,该分值越大说明聚类效果越好,该模型的c&h分数为200,聚类效果良好。
本文相关数据文件公众号回复“Scikit-learn从入门到放弃”获取。
公众号本文地址:https://mp.weixin.qq.com/s/L0tKz9JFnsgrzSCXDswbRA
Scikit-learn从入门到放弃的更多相关文章
- CYQ.Data 从入门到放弃ORM系列:开篇:自动化框架编程思维
前言: 随着CYQ.Data 开始回归免费使用之后,发现用户的情绪越来越激动,为了保持这持续的激动性,让我有了开源的念头. 同时,由于框架经过这5-6年来的不断演进,以前发的早期教程已经太落后了,包括 ...
- [精品书单] C#/.NET 学习之路——从入门到放弃
C#/.NET 学习之路--从入门到放弃 此系列只包含 C#/CLR 学习,不包含应用框架(ASP.NET , WPF , WCF 等)及架构设计学习书籍和资料. C# 入门 <C# 本质论&g ...
- OpenStack从入门到放弃
OpenStack从入门到放弃 目录: 为何选择云计算/云计算之前遇到的问题 什么是云计算 云服务模式 云应用形式 传统应用与云感知应用 openstack及其相关组件介绍 flat/vlan/gre ...
- 绕过校园网的共享限制 win10搭建VPN服务器实现--从入门到放弃
一.开篇立论= =.. 上次说到博主在电脑上搭建了代理服务器来绕过天翼客户端的共享限制,然而经过实际测试还不够完美,所以本着生命不息,折腾不止的精神,我又开始研究搭建vpn服务器= =... (上次的 ...
- 《区块链:从入门到放弃》之obc安装步骤
obc安装步骤 朋友们可能会好奇,厨师不研究菜谱怎么改研究兵法了,哈哈,我原本是app出身,最近被安排去预研区块链和比特币技术,2个月下来,颇有斩获.期间得到IBM的CC同学指导我一步一步安装obc的 ...
- win10搭建代理服务器实现绕过校园网的共享限制--从入门到放弃
博主所在学校特别坑爹,校园网被电信一家垄断了,而且最恶心的还是电信要求一条网线只能供一台电脑上网,不许接路由器共享网络= =- (还有电信2M价格是380+每年,20m是500每年,而且网速都很慢= ...
- WPF从入门到放弃系列第二章 XAML
本文是作者学习WPF从入门到放弃过程中的一些总结,主要内容都是对学习过程中拜读的文章的整理归纳. 参考资料 XAML 概述 (WPF):https://msdn.microsoft.com/zh-cn ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Android -- 带你从源码角度领悟Dagger2入门到放弃
1,以前的博客也写了两篇关于Dagger2,但是感觉自己使用的时候还是云里雾里的,更不谈各位来看博客的同学了,所以今天打算和大家再一次的入坑试试,最后一次了,保证最后一次了. 2,接入项目 在项目的G ...
- Android -- 带你从源码角度领悟Dagger2入门到放弃(二)
1,接着我们上一篇继续介绍,在上一篇我们介绍了简单的@Inject和@Component的结合使用,现在我们继续以老师和学生的例子,我们知道学生上课的时候都会有书籍来辅助听课,先来看看我们之前的Stu ...
随机推荐
- Blazor Server App Cannot find the fallback endpoint specified by route values
github官方issues中提到的解决方案,CreateBuilder时指定项目绝对路径可以解决. 1 // 指定项目路径,也可以用Assembly.GetCallingAssembly获取 2 c ...
- 【VMware VCF】VMware Cloud Foundation Part 02:部署 Cloud Builder。
VMware Cloud Builder 是用于构建 VMware Cloud Foundation 第一个管理域的自动化部署工具,通过将一个预定义信息的 Excel 参数表导入到 Cloud Bui ...
- 第十二节 JMeter基础-中级地址信息【IF控制器】
声明:本文所记录的仅本次操作学习到的知识点,其中商城IP错误,请自行更改. 背景:提交订单前,我们需要核对一些信息,比如商品信息,收货地址,支付方式等.现在核对一下收货地址信息. 思路: 1.前提条件 ...
- JAVA课后谈1
1.课程中动手动脑的问题 在本次课堂实验中,我暴露出了很多问题,尤其是逻辑思维方面,不能很好的处理数理运算问题.在实际生活中客户的要求千变万化,而我们作为一个合格的程序设计者应该顺应其要求,尽可能的去 ...
- python面向对象:继承
python面向对象:继承super()的用 super()的用法 一: class A: def __init__(self): self.a = '这是一个属性' def add(self, x) ...
- RPA美团外卖商家中心批量发送消息
美团外卖商家中心批量发送消息,首先我们需要确定给谁发,发送什么内容 给谁发:可以传入美团用户名.美团订单号.美团将通过此条件进行搜索进入会话框 发送什么内容:批量发送信息给不同的用户,比如给不同的订单 ...
- 14、Spring之基于注解的声明式事务
14.1.概述 14.1.1.编程式事务 事务功能的相关操作全部通过自己编写代码来实现: Connection conn = ...; try { // 开启事务:关闭事务的自动提交 conn.set ...
- 【Hibernate】01 概述
什么是Hibernate? - Hibernate是我们JavaEE开发中的DAO层框架 - DAO[Data Access Object] 数据访问对象层 - 在DAO层,访问数据库,进行CRUD操 ...
- 【SpringBoot】11 Web开发 Part2 模板引擎
开发回顾: JavaWeb开发使用JSP技术,所有的页面文件必须是JSP,才能接受数据处理 JSP的好处是,数据交互方便,有JSTL补充 SpringBoot的区别: 我们最终的项目是一个jar包 内 ...
- 【Java】找不到此类异常
Java.lang.classNotFoundException 找不到此类异常: java.lang.ClassNotFoundException: org.springframework.web. ...