火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
关键技术
数据模型统一
- 类型(Type):描述一类元数据,由多个属性组成。例如,hive table是一类元数据,hive_db也是一类元数据。Type可具备继承关系。按面向对象的编程思想,可以理解type为一个Class。
- 实例(Entity):代表一个type的具体事例。一个entity可能作为一个属性存在于另一个entity中,例如hive_table中的db属性,db本身也是一个entity。在面向对象的编程思想中,一个entity可以认为是一个class的instance。
- 属性(Attribute):属性的集合组合而成为一个Type。属性本身的类型(typeName)可能是一个自定义的type,也可能是一种基础类型,包括date,string等。例如,db是hive_table的一个属性,column也是hive_table的一个属性。
- 关系(Relationship):一种特殊的Entity,用以描述两个Entity之间的关联模式。
- 继承与组合的广泛使用
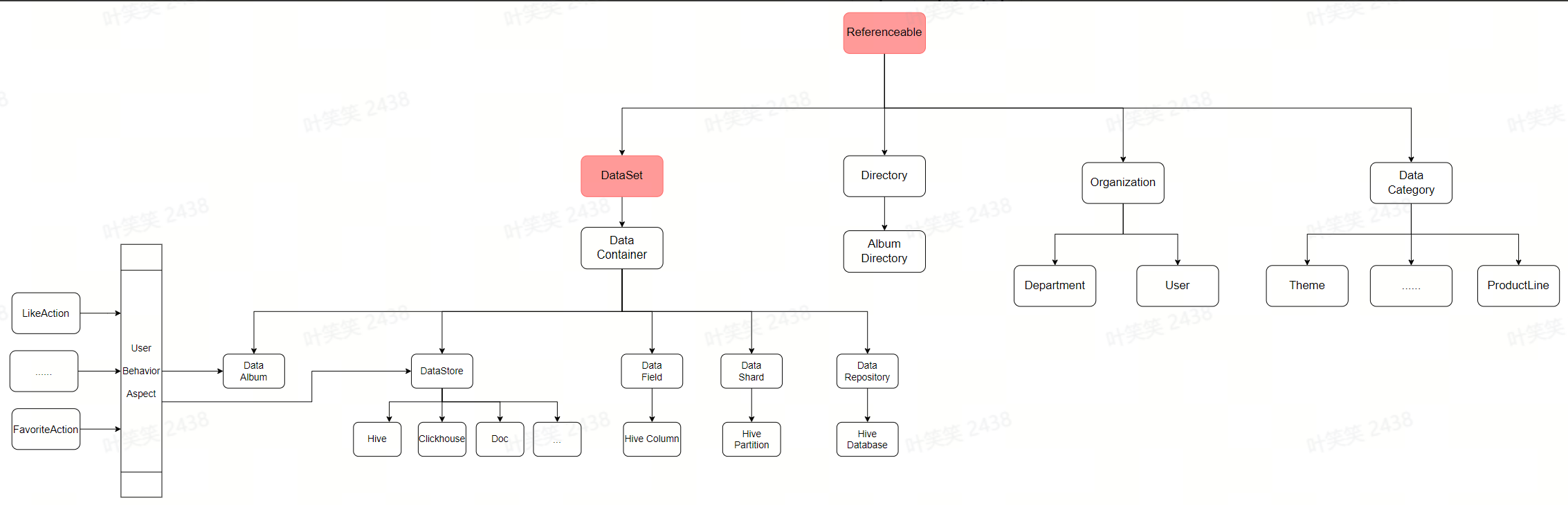
- 调整类型加载机制
数据接入标准化
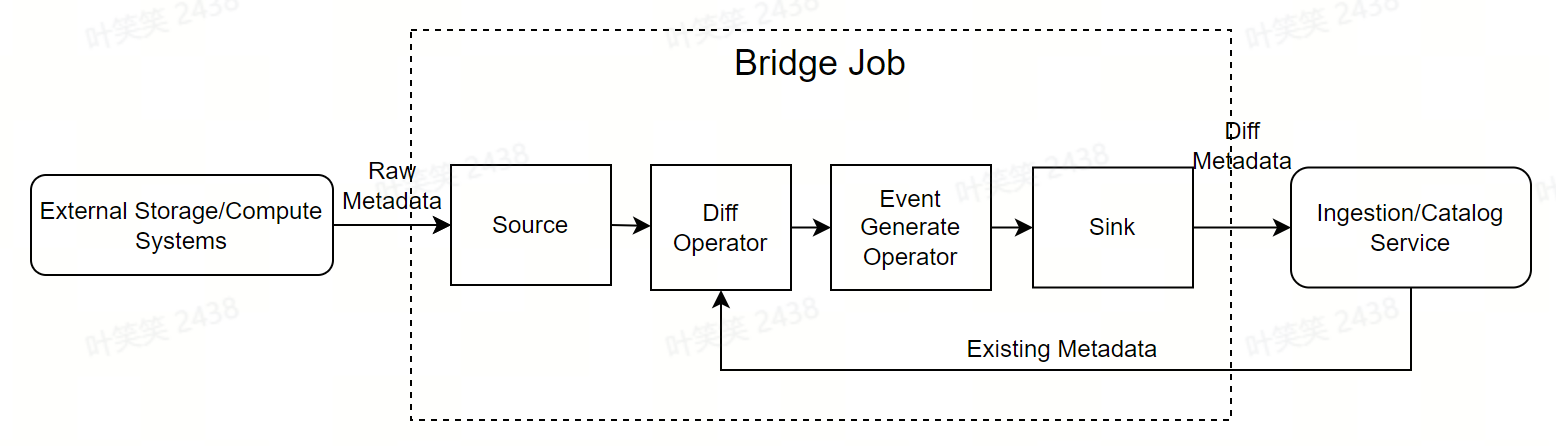
- Source:从外部存储计算系统等批量拉取最新的全量元数据。数据结构和字段通常由外部系统决定。概念上可对齐Flink的source operator。
- Diff Operator:接收source的输出,并从Catalog Service拉取当前系统中的全量元数据,做差异对比,产出差异的部分。概念上对齐Flink中的某一种自定义的ProcessFunction。
- Event Generate Operator:接收Diff Operator的输出,根据Catalog系统定义好的格式,将差异的metadata转化成event格式,比如对于新建的metadata,转换成CreateEvent。概念上对齐Flink中的某一种自定义的ProcessFunction。
- Sink:接收Event Generate Operator的输出,将差异的metadata写入Ingestion Service。概念上对齐Flink的sink operator。
- Bridge Job:组装pipeline,做运行时控制。概念上对齐Flink的Job。
搜索优化
- 搜索中存在部分很强的Pattern:用户搜索元数据时,有一些隐式的习惯,通过挖掘埋点中的固定pattern,给了我们针对性优化的机会。
- 行为数据规模有限:公司内部的元数据搜索用户,通常是千级别,而每天搜索的点击次数是万级别,这个规模远远小于对外的通用搜索引擎,也造成很多模型没法及时收敛,但也一定程度上给与我们简化问题的机会。
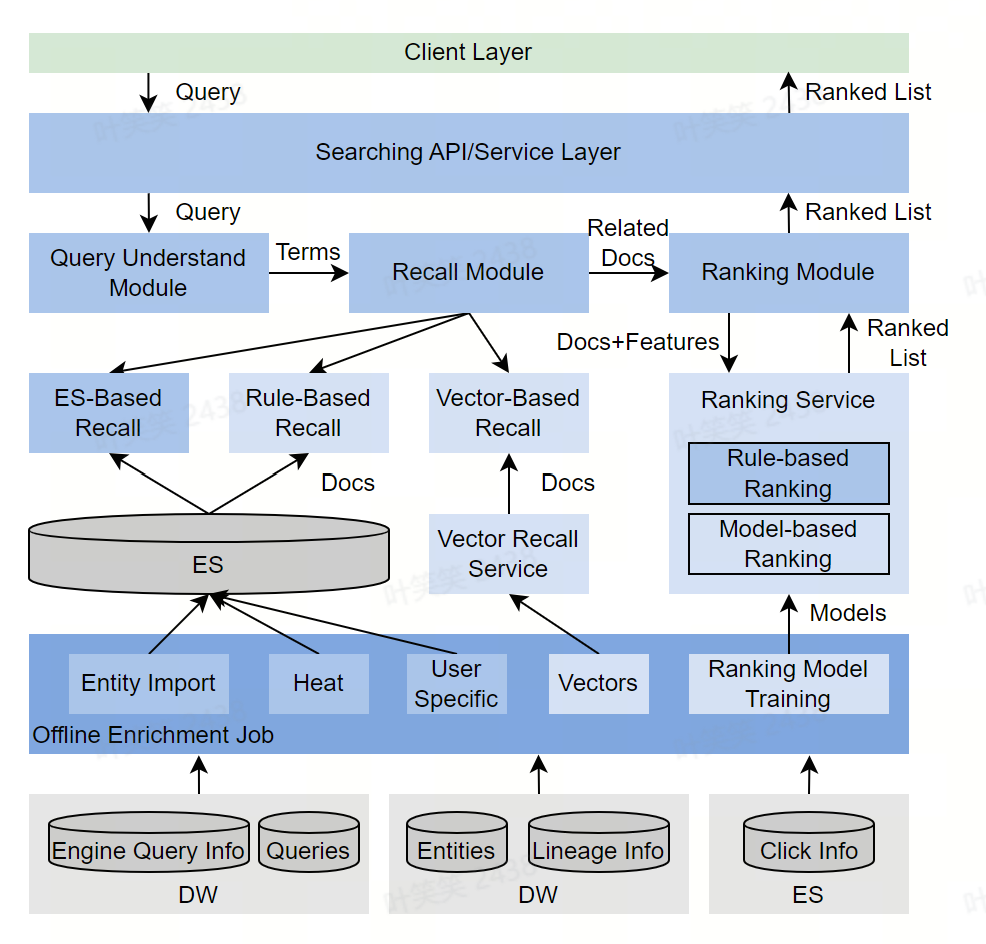
- 离线部分:负责汇集各类与搜索相关的数据,做数据清洗或者模型训练,根据不同的用途,写入不同的存储,供给在线搜索模块使用。
- 在线部分:分为搜索理解、召回、精排三个主要阶段,步骤和概念上与通用搜索引擎对齐。
- 对于强Pattern,广泛使用Rule-Based的优化手段:比如,火山引擎 DataLeap 研发人员发现很大一部分用户在搜索Hive时,会使用“库名.表名”的pattern,在识别到query语句中有“.”时,火山引擎 DataLeap 研发人员会优先尝试根据库名和表名检索
- 激进的个性化:因用户规模可控,且某位用户通常会频繁使用某个领域的元数据,火山引擎 DataLeap 研发人员记录了很多用户的历史行为细节,当query语句与过去浏览过元数据有一定文本相关性时,个性化相关的得分会有较大提升
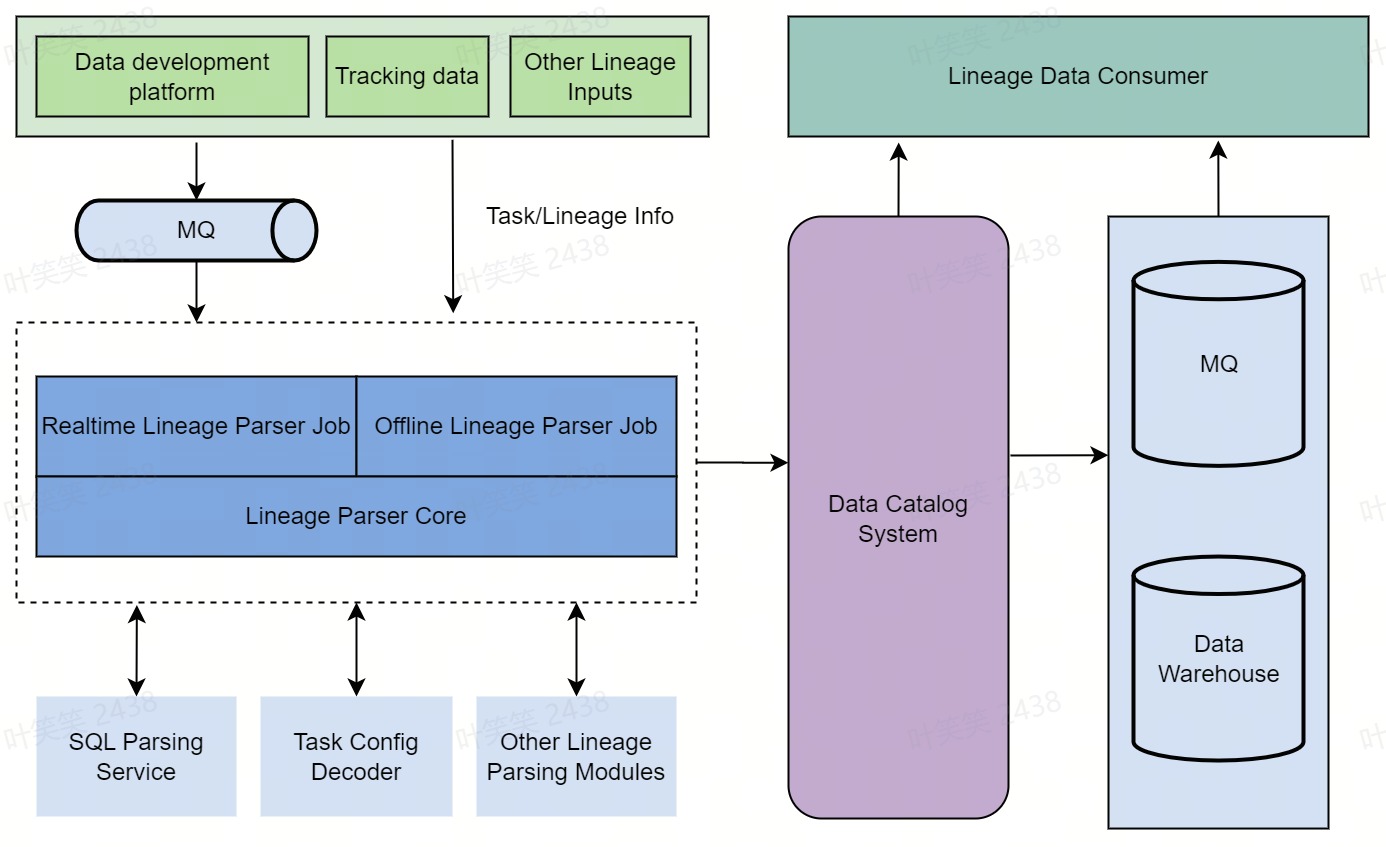
血缘能力
存储层优化
读优化:开启MutilPreFetch 能力
写优化:去除Guid全局唯一性检查
|
|
优化前
|
优化后
|
|
小表(10列以内)
|
1~2s
|
<100ms
|
|
中表(100-500列)
|
3-5min
|
2~5s
|
|
超大表(3000列以上)
|
15min以上,经常写入失败
|
0.5~1min,可写入
|
未来工作
火山引擎 DataLeap 构建Data Catalog系统的实践(三):关键技术与总结的更多相关文章
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 字节跳动构建Data Catalog数据目录系统的实践(上)
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系.本文介绍了字节跳动 Data ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 基于MRS-ClickHouse构建用户画像系统方案介绍
业务场景 用户画像是对用户信息的标签化.用户画像系统通过对收集的各维度数据,进行深度的分析和挖掘,给不同的用户打上不同的标签,从而刻画出客户的全貌.通过用户画像系统,可以对各个用户进行精准定位,从而将 ...
随机推荐
- TS版LangChain实战:基于文档的增强检索(RAG)
LangChain LangChain是一个以 LLM (大语言模型)模型为核心的开发框架,LangChain的主要特性: 可以连接多种数据源,比如网页链接.本地PDF文件.向量数据库等 允许语言模型 ...
- 小白必知:AIGC 和 ChatGPT 的区别
原文 : https://openaigptguide.com/chatgpt-aigc-difference/ AIGC 和 ChatGPT 都是人工智能技术,但它们的功能和应用场景不同. AIGC ...
- 嵌入式linux主机通过分区镜像生成固件,DD备份分区后打包成固件,px30刷机教程 ,rockchip刷机教程
我这边有一个工控路由器因为刷机变砖了,网上下载不到固件,自己暂时还没有搞过编译.我找到了同型号的路由器,把它的系统制作成镜像. 具体操作分为三步: 第一步,直接用DD命令备份了几个分区,分区我暂时还不 ...
- mybatis数据不匹配问题
错误:数据不匹配的问题 原因:在初始化数据时.创建构造参数时只创建了全参,没有创建口参. 具体原因:因为mybatis框架会调用这个默认构造方法来构造实例对象.即Class类的newInstance方 ...
- 后端程序员必会的前端知识-03:Vue2
三. Vue 2 1. Vue 基础 1) 环境准备 安装脚手架 npm install -g @vue/cli -g 参数表示全局安装,这样在任意目录都可以使用 vue 脚本创建项目 创建项目 vu ...
- 华企盾DSC在苹果电脑上申请审批没有通知
由于系统通知这里没有允许DSC通知,开启后即可.系统偏好设置-通知与专注模式-通知
- 华企盾DSC无缝替换亿赛通案例
第一种方法无缝替换亿赛通案例 1. 把DSCClient.exe和DSCService.exe添加到亿赛通的加密控制策略中,关联类型设置为*.*|,配置为落地自动解密,包括其它程序也配置成落地自动解密 ...
- 别再傻傻地用 ifconfig 查地址了!这条命令足以让你摘掉小白工程师的帽子
大家好,我是民工哥. 众所周知,在 Linux 系统中,ip 和 ifconfig 这个两命令的功能十分相似,ifconfig 是 net-tools 中已被弃用的一个命令,很多年前就已经没有维护了. ...
- Next.js 开发指南 初始篇 | Next.js CLI
基础篇.实战篇.源码篇.面试篇四大篇章带你系统掌握 Next.js! 前言 欢迎学习 Next.js!在学习具体的知识点之前,我们先来创建一个 Next.js 项目.创建了可运行的项目,才能在学习 ...
- VSFTPD2.3.4(笑脸漏洞)复现
vsftpd2.3.4笑脸漏洞复现 目标服务器:metasploitable2(192.168.171.11) 渗透机:Kali(192.168.171.21) 方法一:手动复现 首先用kali扫描一 ...