DM数据库SQL分页案例
DM一哥们找我优化条分页的SQL语句,结果集很小返回99行数据,废话不说安排一下。
原始SQL语句如下,保密要求,给真实的表名换了别名:
SELECT count(*)
FROM (SELECT TMP.*,
ROWNUM ROW_ID
FROM (select *
from (select pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 name,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN '是'
WHEN jfw01.JFW01009 = '0' THEN '否'
else '' end) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (partition by jbt.task_oid order by jbti.UPDATED_DATE desc) as rn,
(case
when jbt.BIZ_STATUS_CODE = 'WU999' then ''
else
(SELECT bl.REMARK
FROM qqqqq bl
where bl.biz_Status_Code IN
('WU104', 'WU107', 'WM106', 'WM109', 'WM112', 'WU110', 'WM115', 'WU110',
'WM115')
AND bl.TASK_OID = jbt.TASK_OID
order by bl.CREATED_DATE DESC LIMIT 1) end) reCallOpinion,
to_char(rr.a15021, 'yyyy') as promoteYear,
rr.a15017 as reviewResultType
FROM aaaaa jbti,
bbbbb jbt
inner join ccccc pp
on
jbt.task_oid = pp.TASK_ID
left join ddddd jfw01
on
pp.biz_person_id = jfw01.biz_person_id
left join uuuuu jfa34
on
pp.biz_person_id = jfa34.biz_person_id
left join vvvvv bu
on
pp.UNIT_ID = bu.UNIT_ID
left join
(select ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark desc, id desc) AS num,
a15021,
a15017,
biz_person_id
from rrrrr) rr
on
pp.biz_person_id = rr.biz_person_id
and rr.num = '1'
WHERE jbt.task_oid = jbti.task_oid
and pp.UNIT_ID in
(select unit_oid
from sssss
where user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE in
(select jmn.FLOW_NODE_CODE
from jjjjj jmn
where jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC)
WHERE rn = 1) TMP
WHERE ROWNUM <= 100)
WHERE ROW_ID > 1;
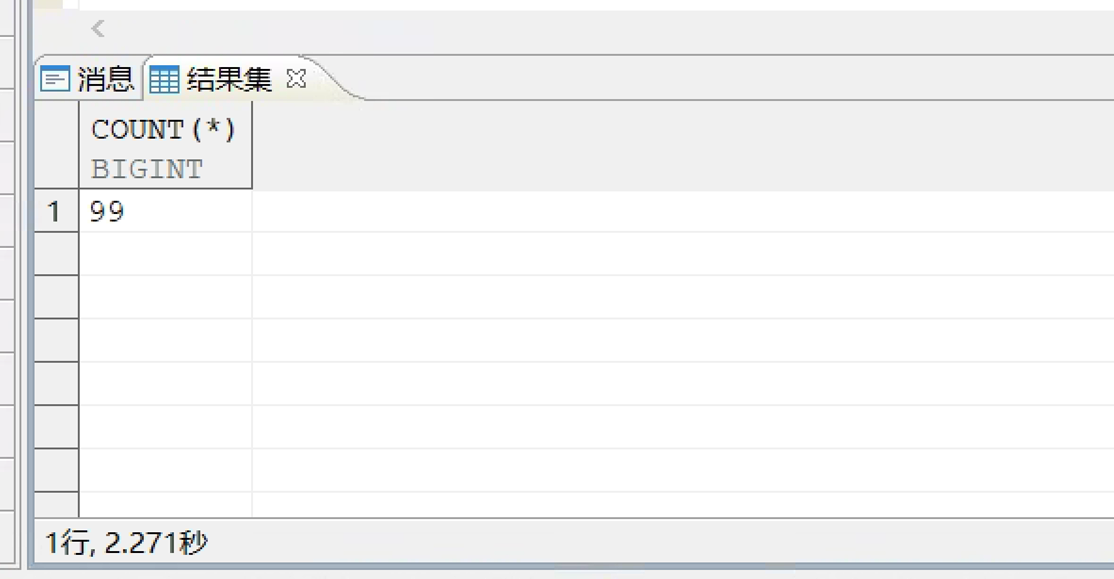
执行时间:
DM数据库的执行计划太难看了,直接忽略,用瞪眼大法观察下SQL大致看看是哪里慢的。
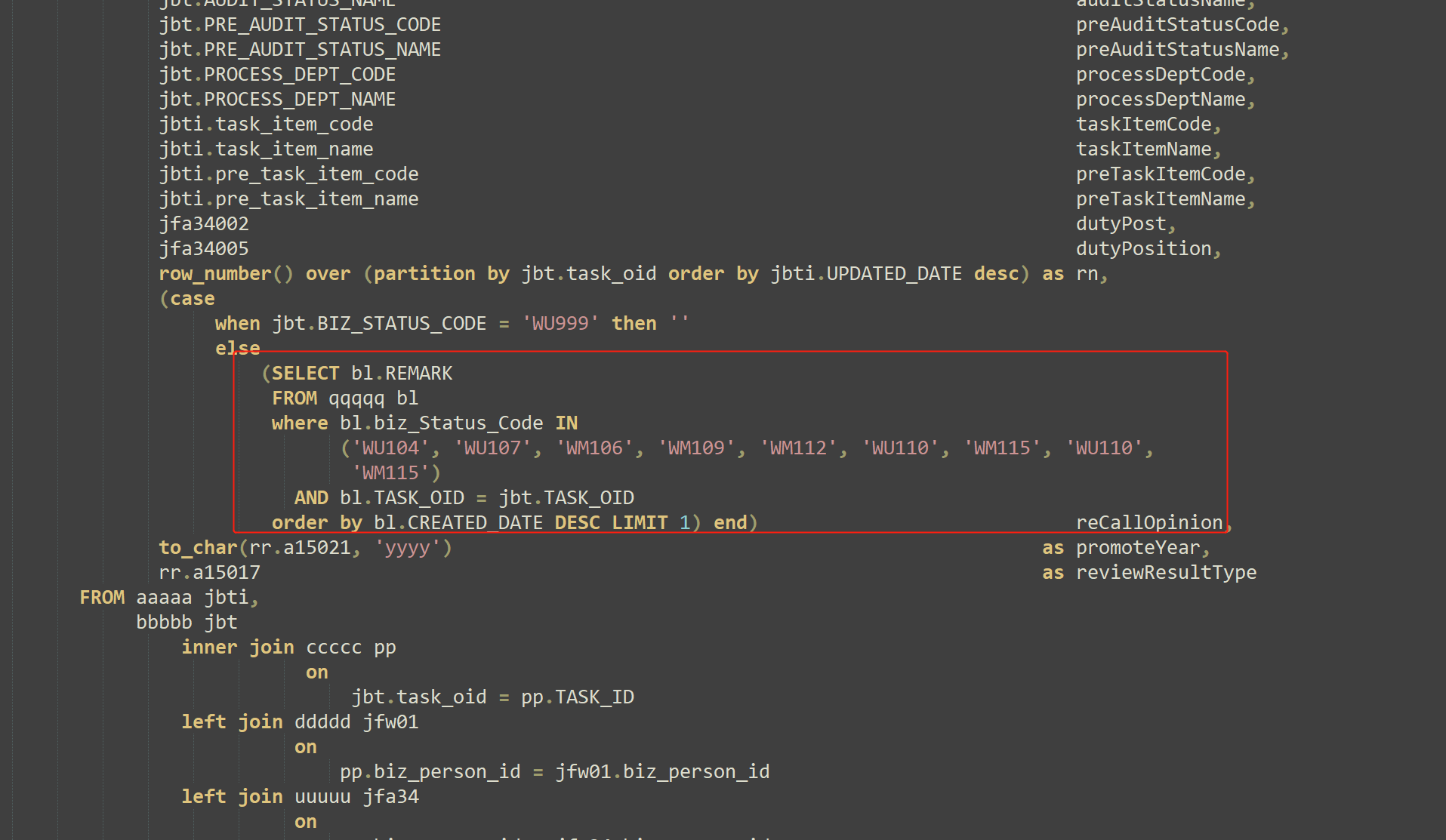
这段标量子查询去掉以后,单独把SQL拿出来跑,不加外层分页代码,0.1S能出结果,137条记录,大致判断是这里导致慢的因素。
select pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 name,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN '是'
WHEN jfw01.JFW01009 = '0' THEN '否'
else '' end) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (partition by jbt.task_oid order by jbti.UPDATED_DATE desc) as rn,
to_char(rr.a15021, 'yyyy') as promoteYear,
rr.a15017 as reviewResultType
FROM aaaaa jbti,
bbbbb jbt
inner join ccccc pp
on
jbt.task_oid = pp.TASK_ID
left join ddddd jfw01
on
pp.biz_person_id = jfw01.biz_person_id
left join uuuuu jfa34
on
pp.biz_person_id = jfa34.biz_person_id
left join vvvvv bu
on
pp.UNIT_ID = bu.UNIT_ID
left join
(select ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark desc, id desc) AS num,
a15021,
a15017,
biz_person_id
from rrrrr) rr
on
pp.biz_person_id = rr.biz_person_id
and rr.num = '1'
WHERE jbt.task_oid = jbti.task_oid
and pp.UNIT_ID in
(select unit_oid
from sssss
where user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE in
(select jmn.FLOW_NODE_CODE
from jjjjj jmn
where jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC
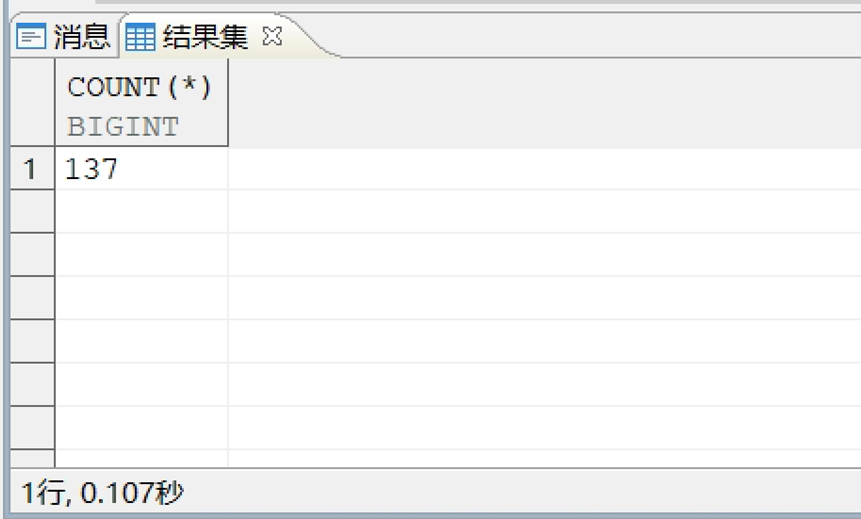
qqqqq 表加个联合索引再跑分页语句试试。
CREATE INDEX "IDX_TASK_BIZ" ON "qqqqq"("TASK_OID" ASC,"BIZ_STATUS_CODE" ASC) STORAGE(ON "hzgz_xcuatdb", CLUSTERBTR);
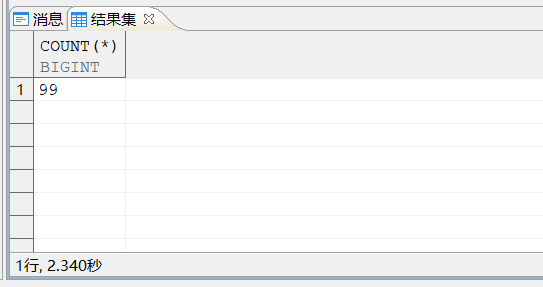
还是需要2.34S才能出结果,这个时候笔者就在想会不会是分页框架提供的分页方式不对,换个分页写法再试试。
-- 使用新的分页模板,没改语句
SELECT count(*)
FROM (SELECT *
FROM (SELECT t.*,
rownum ROW_ID
FROM (select pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 name,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN '是'
WHEN jfw01.JFW01009 = '0' THEN '否'
else '' end) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (partition by jbt.task_oid order by jbti.UPDATED_DATE desc) as rn,
(case
when jbt.BIZ_STATUS_CODE = 'WU999' then ''
else
(SELECT bl.REMARK
FROM qqqqq bl
where bl.biz_Status_Code IN
('WU104', 'WU107', 'WM106', 'WM109', 'WM112', 'WU110', 'WM115', 'WU110',
'WM115')
AND bl.TASK_OID = jbt.TASK_OID
order by bl.CREATED_DATE DESC LIMIT 1) end) reCallOpinion,
to_char(rr.a15021, 'yyyy') as promoteYear,
rr.a15017 as reviewResultType
FROM aaaaa jbti,
bbbbb jbt
inner join ccccc pp
on
jbt.task_oid = pp.TASK_ID
left join ddddd jfw01
on
pp.biz_person_id = jfw01.biz_person_id
left join uuuuu jfa34
on
pp.biz_person_id = jfa34.biz_person_id
left join vvvvv bu
on
pp.UNIT_ID = bu.UNIT_ID
left join
(select ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark desc, id desc) AS num,
a15021,
a15017,
biz_person_id
from rrrrr) rr
on
pp.biz_person_id = rr.biz_person_id
and rr.num = '1'
WHERE jbt.task_oid = jbti.task_oid
and pp.UNIT_ID in
(select unit_oid
from sssss
where user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE in
(select jmn.FLOW_NODE_CODE
from jjjjj jmn
where jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC) t)
WHERE rownum <= 100)
WHERE ROW_ID >= 1;
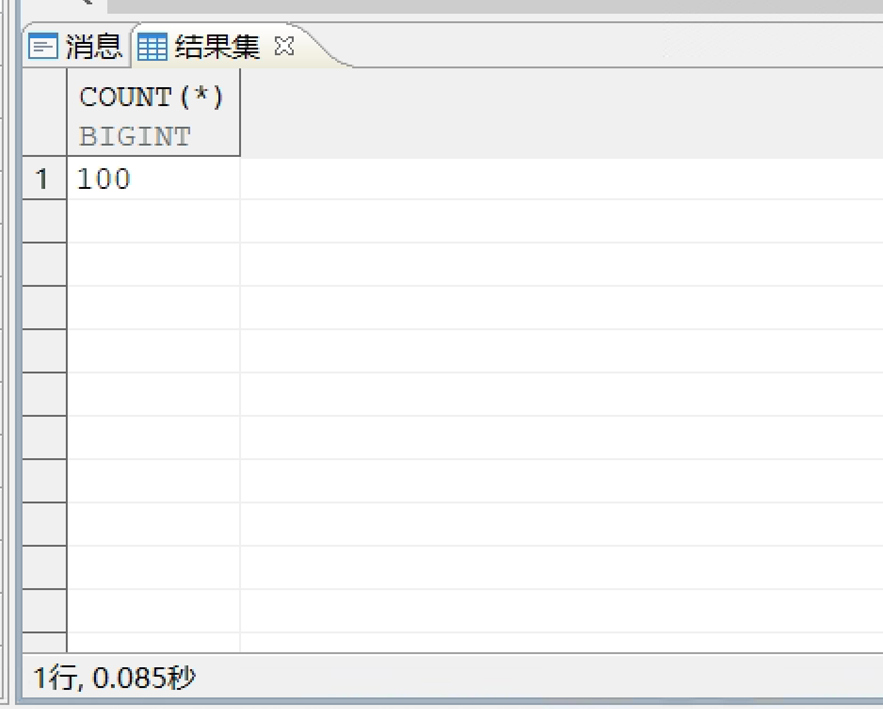
可以看到新的分页语句0.085S就能出结果了,简直秒杀。
总结:开发框架提的分页插件有可能提供错误的分页框架,会极大影响SQL语句原有的性能,需要多测试才能知道分页语句的性能是否符合性能要求,下面笔者提供个正确的分页框架:
select *
from (select *
from (select a.*, rownum rn from (
需要分页的 SQL
) a)
where rownum <= 10)
where rn >= 1;
最后,提供个left join 等价改写的方式干掉上面的标量子查询,但是在本案例中等价改写方式并没有太大性能提升,仅供娱乐:
-- 改分页模板,改SQL
SELECT count(*)
FROM (SELECT *
FROM (SELECT t.*,
rownum ROW_ID
FROM (SELECT pp.BIZ_PERSON_ID partyPersonOid,
pp.BIZ_PERSON_ID bizPersonId,
pp.PERSON_ID personOid,
pp.PERSON_ID personId,
pp.A01065 a01065,
jbt.task_oid taskOid,
pp.A01084 idNo,
pp.A01001 NAME,
jfa34.jfa34009 jfa34009,
jfa34.jfa34010 jfa34010,
jfa34.jfa34013 jfa34013,
jfa34.jfa34014 jfa34014,
bu.UNIT_ID unitOid,
bu.B01001 unitName,
bu.JFB01002 adminUnitName,
bu.PARENT_UNIT_ID parentUnitId,
(CASE
WHEN jfw01.JFW01009 = '1' THEN
'是'
WHEN jfw01.JFW01009 = '0' THEN
'否'
ELSE
''
END) isTfPerson,
jbt.CREATED_DATE createdDate,
jbt.UPDATED_DATE updatedDate,
jbt.PROCESS_RESULT processResult,
jbt.start_time startTime,
jbt.complete_time completeTime,
jbt.CREATED_DATE creatTaskTime,
jbt.UPDATED_DATE updateTaskTime,
jbt.item_code itemCode,
jbt.BIZ_STATUS_CODE bizStatusCode,
jbt.BIZ_STATUS_NAME bizStatusName,
jbt.PRE_BIZ_STATUS_CODE preBizStatusCode,
jbt.PRE_BIZ_STATUS_NAME preBizStatusName,
jbt.AUDIT_STATUS_CODE auditStatusCode,
jbt.AUDIT_STATUS_NAME auditStatusName,
jbt.PRE_AUDIT_STATUS_CODE preAuditStatusCode,
jbt.PRE_AUDIT_STATUS_NAME preAuditStatusName,
jbt.PROCESS_DEPT_CODE processDeptCode,
jbt.PROCESS_DEPT_NAME processDeptName,
jbti.task_item_code taskItemCode,
jbti.task_item_name taskItemName,
jbti.pre_task_item_code preTaskItemCode,
jbti.pre_task_item_name preTaskItemName,
jfa34002 dutyPost,
jfa34005 dutyPosition,
row_number() over (PARTITION BY jbt.task_oid ORDER BY jbti.UPDATED_DATE DESC) AS rn,
(CASE WHEN jbt.BIZ_STATUS_CODE = 'WU999' THEN '' ELSE bl.REMARK END) reCallOpinion,
to_char(rr.a15021, 'yyyy') AS promoteYear,
rr.a15017 AS reviewResultType
FROM aaaaa jbti,
bbbbb jbt
left join
(select *
from (select REMARK,
TASK_OID,
row_number() over (PARTITION by TASK_OID ORDER by CREATED_DATE desc ) as rn
from qqqqq
where biz_Status_Code in ('WU104',
'WU107',
'WM106',
'WM109',
'WM112',
'WU110',
'WM115',
'WU110',
'WM115'))
where rn = 1) bl on jbt.task_oid = bl.task_oid
INNER JOIN ccccc pp
ON jbt.task_oid = pp.TASK_ID
LEFT JOIN ddddd jfw01
ON pp.biz_person_id = jfw01.biz_person_id
LEFT JOIN uuuuu jfa34
ON pp.biz_person_id = jfa34.biz_person_id
LEFT JOIN vvvvv bu
ON pp.UNIT_ID = bu.UNIT_ID
LEFT JOIN (SELECT ROW_NUMBER() OVER (PARTITION BY biz_person_id ORDER BY a15021 DESC, handle_Mark DESC, id DESC) AS num,
a15021,
a15017,
biz_person_id
FROM rrrrr) rr
ON pp.biz_person_id = rr.biz_person_id
AND rr.num = '1' WHERE jbt.task_oid = jbti.task_oid
AND pp.UNIT_ID IN
(SELECT unit_oid FROM sssss WHERE user_id = 'admin')
AND jbti.TASK_ITEM_STATUS = '1'
AND jbti.TASK_ITEM_CODE IN
(SELECT jmn.FLOW_NODE_CODE
FROM jjjjj jmn
WHERE jmn.MENU_CODE = 'B742101101')
ORDER BY jbt.UPDATED_DATE DESC) t)
WHERE rownum <= 99)
WHERE ROW_ID >= 1;
DM数据库SQL分页案例的更多相关文章
- 数据库SQL优化大总结之 百万级数据库优化方案(转载)
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 这篇文章我花费了大量的时间查找资料.修改.排版,希望大家阅读之后,感觉 ...
- 关于数据库SQL优化
1.数据库访问优化 要正确的优化SQL,我们需要快速定位能性的瓶颈点,也就是说快速找到我们SQL主要的开销在哪里?而大多数情况性能最慢的设备会是瓶颈点,如下载时网络速度可能会是瓶颈点,本地复制文件 ...
- 数据库sql优化总结之5--数据库SQL优化大总结
数据库SQL优化大总结 小编最近几天一直未出新技术点,是因为小编在忙着总结整理数据库的一些优化方案,特此奉上,优化总结较多,建议分段去消化,一口吃不成pang(胖)纸 一.百万级数据库优化方案 1.对 ...
- 盘点几种数据库的分页SQL的写法(转)
Data序列——盘点几种数据库的分页SQL的写法http://www.cnblogs.com/fireasy/archive/2013/04/10/3013088.html
- jDialects:一个从Hibernate抽取的支持70多种数据库方言的原生SQL分页工具
jDialects(https://git.oschina.net/drinkjava2/jdialects) 是一个收集了大多数已知数据库方言的Java小项目,通常可用来创建分页SQL和建表DDL语 ...
- 我的sql数据库存储过程分页- -
以前用到数据库存储过程分页的时候都是用 not in 但是最近工作的时候,随着数据库记录的不断增大,发现not in的效率 真的不行 虽然都设置了索引,但是当记录达到10w的时候就发现不行了,都是需要 ...
- sql分页查询(2005以后的数据库)和access分页查询
sql分页查询: select * from ( select ROW_NUMBER() over(order by 排序条件) as rowNumber,* from [表名] where 条件 ) ...
- oracle,mysql,SqlServer三种数据库的分页查询的实例。
MySql: MySQL数据库实现分页比较简单,提供了 LIMIT函数.一般只需要直接写到sql语句后面就行了.LIMIT子 句可以用来限制由SELECT语句返回过来的数据数量,它有一个或两个参数,如 ...
- SQL分页查询,纯Top方式和row_number()解析函数的使用及区别
听同事分享几种数据库的分页查询,自己感觉,还是需要整理一下MS SqlSever的分页查询的. Sql Sever 2005之前版本: select top 页大小 * from 表名 where i ...
- MySQL 数据库增量数据恢复案例
MySQL 数据库增量数据恢复案例 一.场景概述 MySQL数据库每日零点自动全备 某天上午10点,小明莫名其妙地drop了一个数据库 我们需要通过全备的数据文件,以及增量的binlog文件进行数据恢 ...
随机推荐
- 2023ccpc大学生程序设计竞赛-wmh
这算是我第一次参加这种团队赛,感谢程老师给我这个机会.刚开赛还算比较顺利,一眼看出来A是个签到,拿下之后开始跟榜F题.一开始想法比较简单,就是排序,记录相邻两个数的差,然后再排序.wa了后以为是范围出 ...
- MIT 6.5840 Raft Implementation(2B, Log Replication)
Raft实现思路+细节(2B) 任务分解 2B中最主要的任务就是进行日志的复制.Raft是一个强领导人的系统,这意味着所有的日志添加都是由领导人发起的,与之相类似的,还有很多其他的结论(它们都是比较显 ...
- 【hack】浅浅说说自己构造hack的一些逻辑~
怎么说呢,相信很多考过竞赛的同学都会在平时的练习/考试中遭遇过100分但没有AC的情况,结果一看评测结果:subtask的数据点没过! 这时候就是遇到hack数据了,如果被这类数据卡住,说明你的代码可 ...
- P1941 [NOIP2014 提高组] 飞扬的小鸟 题解
我们先不管障碍物. 设 \(f[i][j]\) 表示来到点 \((i,j)\) 的最少点击屏幕数. 因为每秒要不上升 \(k\times x[i]\),要么下降 \(y[i]\). 所以有: \[f[ ...
- 揭秘 .NET 中的 TimerQueue(下)
前言 上文给大家介绍了 TimerQueue 的任务调度算法. https://www.cnblogs.com/eventhorizon/p/17557821.html 这边做一个简单的复习. Tim ...
- Web通用漏洞--CSRF
Web通用漏洞--CSRF 漏洞简介 CSRF(Cross Site Request Forgery, 跨站请求伪造/客户端请求伪造),即通过伪造访问数据包并制作成网页的形式,使受害者访问伪造网页,同 ...
- SNAT与DNAT原理及应用
SNAT与DNAT原理及应用 当内部地址要访问公网上的服务时(如httpd访问),内部地址会主动发起连接,由路由器或者防火墙上的网关对内部地址做个地址转换,将内部地址的私有IP转换为公网的公有IP,网 ...
- Redis的五大数据类型的数据结构
概述 Redis底层有六种数据类型包括:简单动态字符串.双向链表.压缩列表.哈希表.跳表和整数数组.这六种数据结构五大数据类型关系如下: String:简单动态字符串 List:双向链表.压缩列表 ...
- QA|20221010|SecureCRT|我们5分钟前执行了a指令,但因为执行b指令打印了大量日志,把指令记录冲掉了,以后如何避免这种情况?
Q:我们5分钟前执行了a指令,但因为执行b指令打印了大量日志,把指令记录冲掉了,以后如何避免这种情况? A:如下配置
- 《Python魔法大冒险》005 魔法挑战:自我介绍机器人
魔法师和小鱼坐在图书馆的一扇窗户旁,窗外的星空闪烁着神秘的光芒.魔法师轻轻地拍了拍小鱼的肩膀. 魔法师: 小鱼,你已经学会了编写简单的魔法程序,现在我要教你如何创造一个有自己思想的机器人,让它能够和我 ...