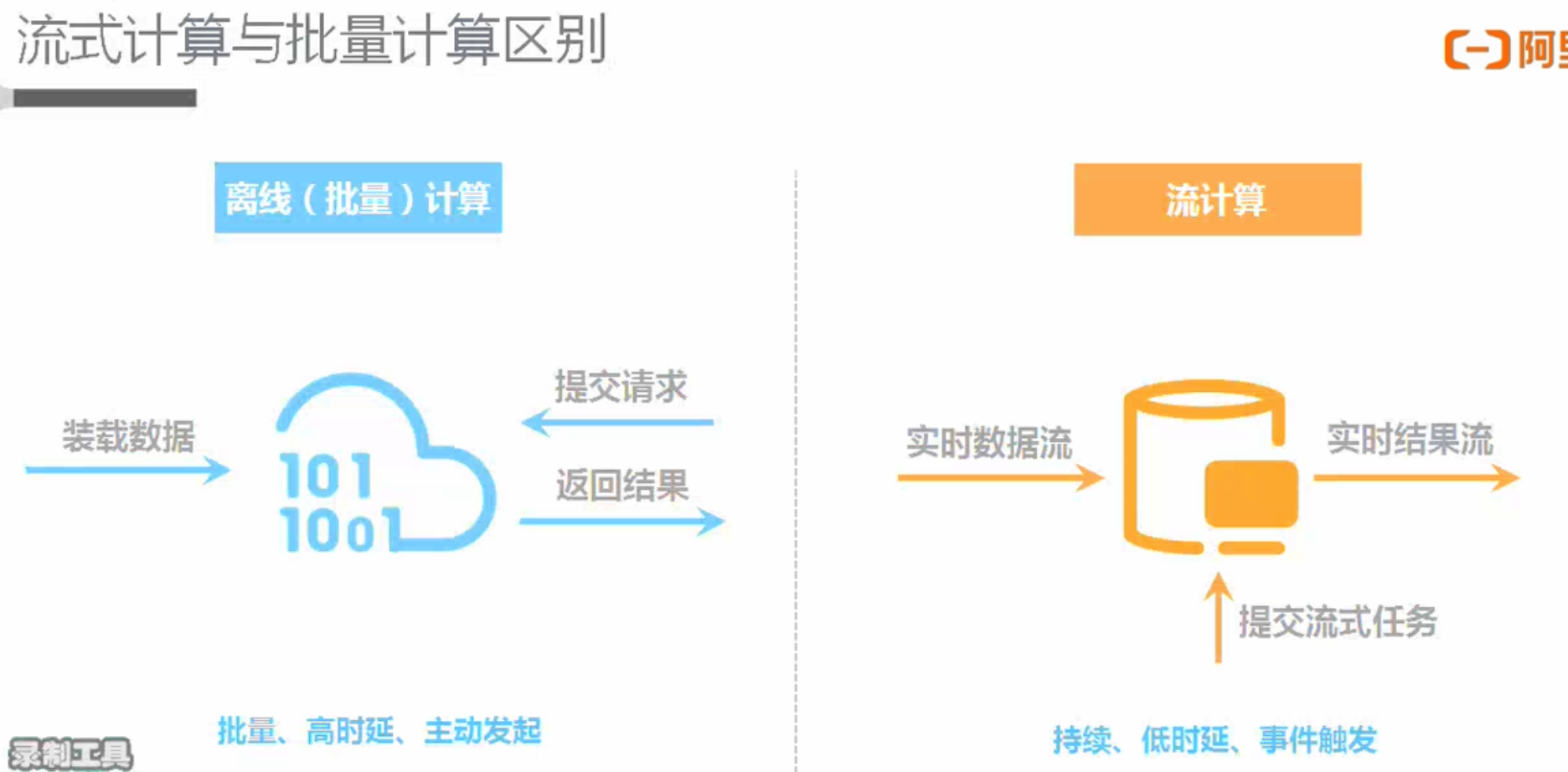
批处理(Batch或离线计算)和流计算(Streaming或实时计算)
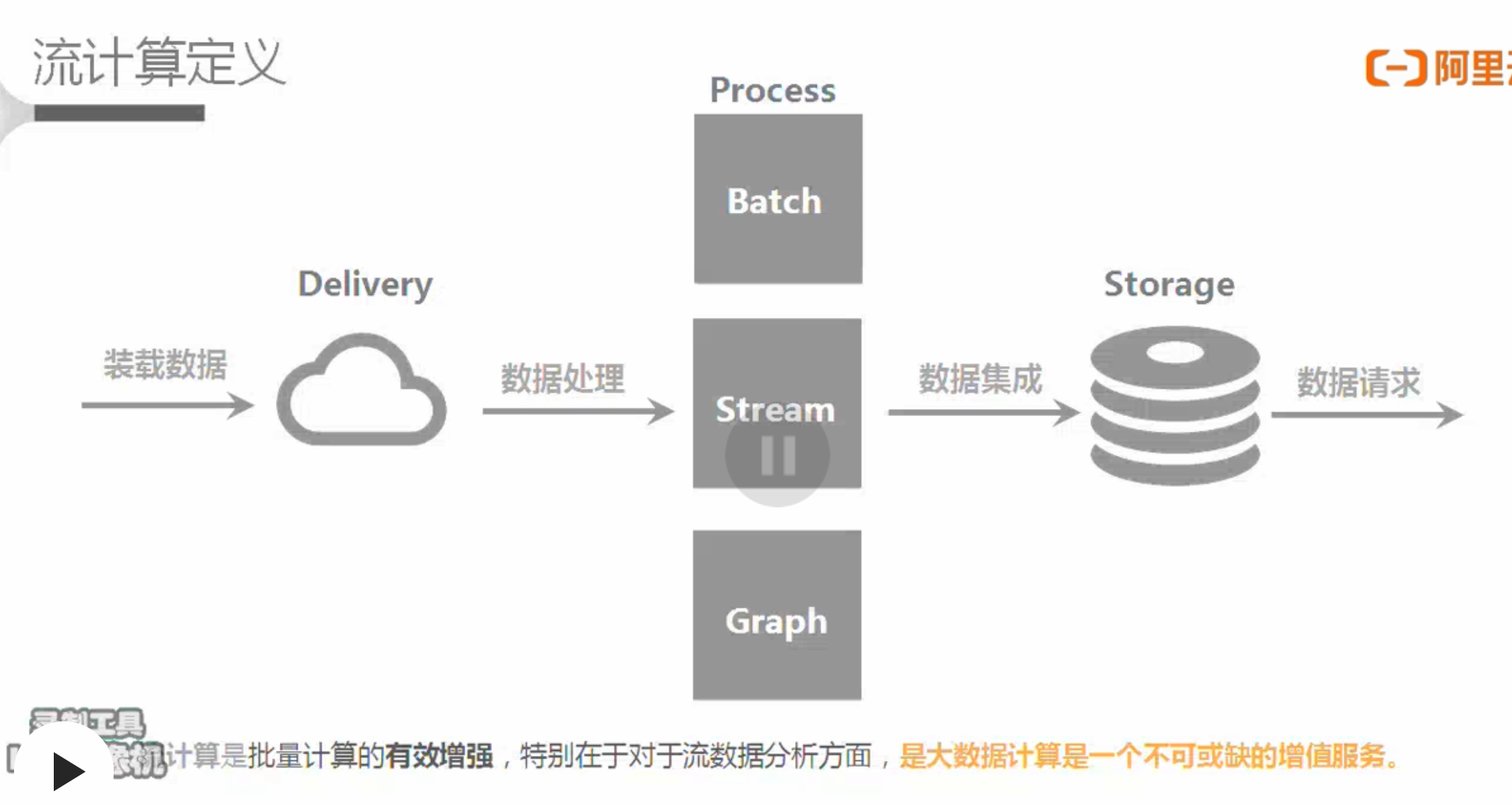
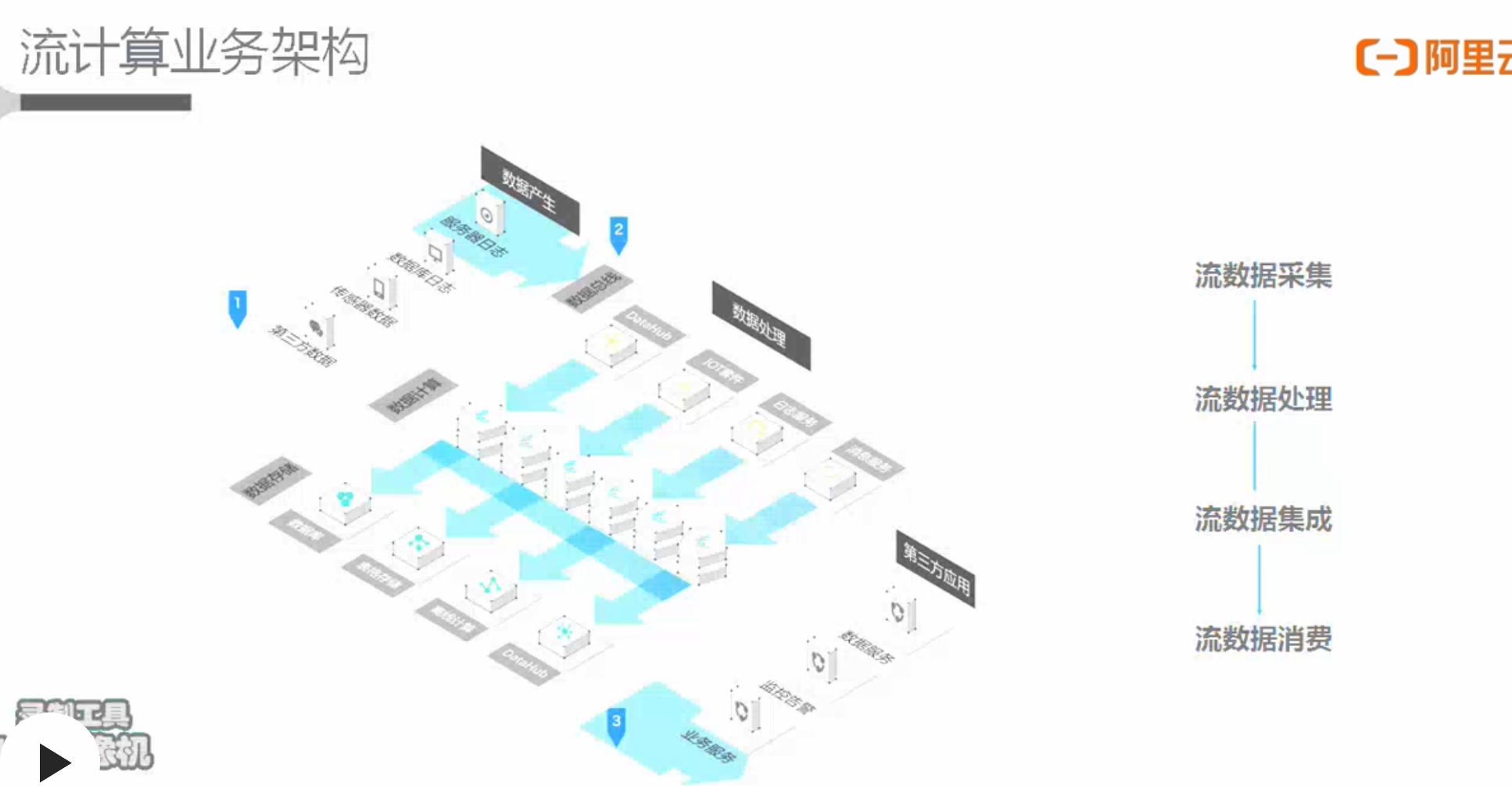
大数据处理流程
- 课程:https://developer.aliyun.com/learning/course/432/detail/5385
- 流程
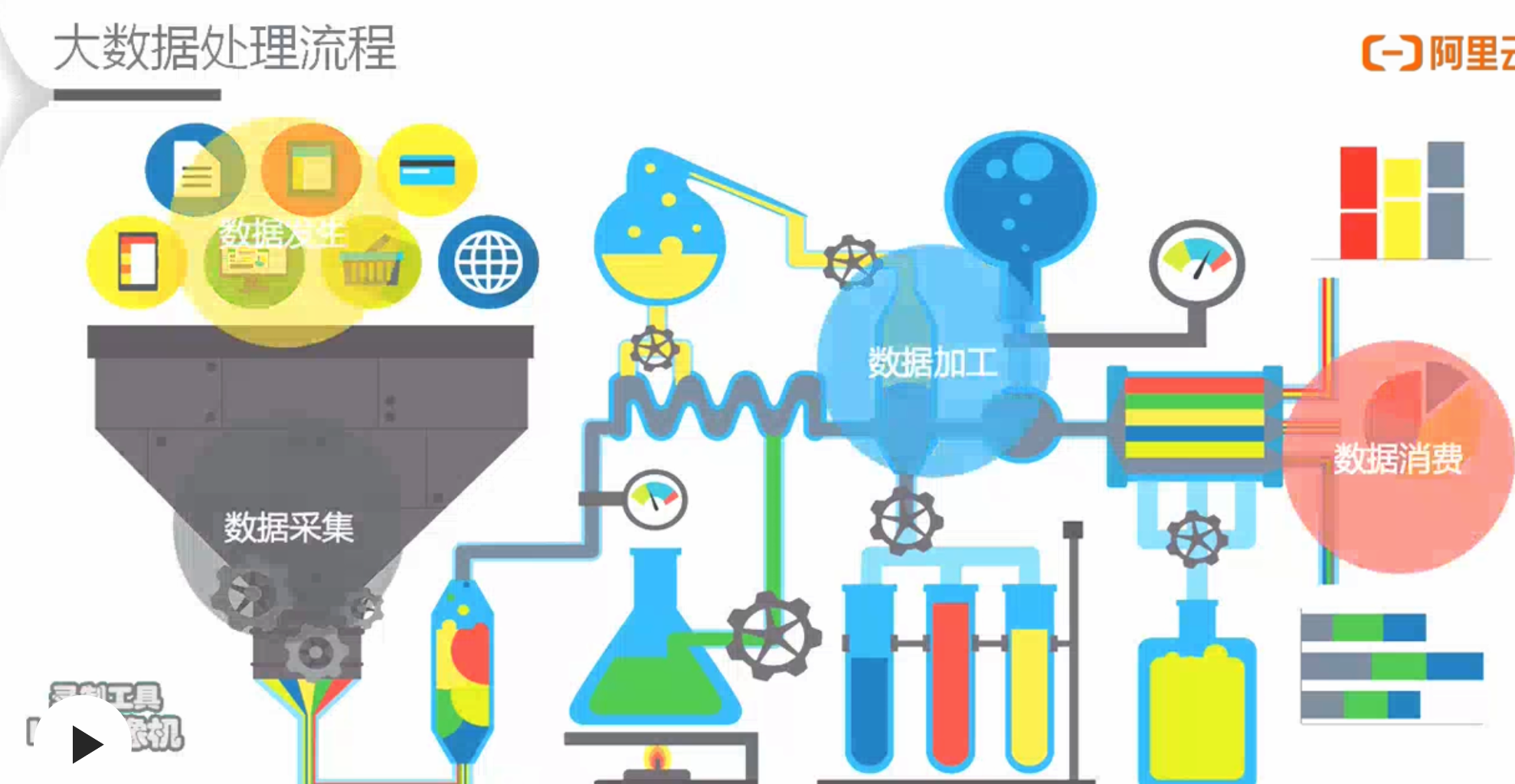

- 发
批处理(Batch或离线计算)
- 基础:google的三大论文——论文GFS、MapReduce、BigTable(kv存储)
- 基于上述论文,开发了产品Hadoop:包含存储(HDFS)+计算(MapReduce)两部分
- 基于mapreduce上面长出了HIVE(就是SQL,降低开发门槛)
- 后面2.0阶段 Spark:解决了磁盘的shuffle性能问题,成为业界批处理的主流;但阿里内部一直是ODPS(基于mapreduce)上去做
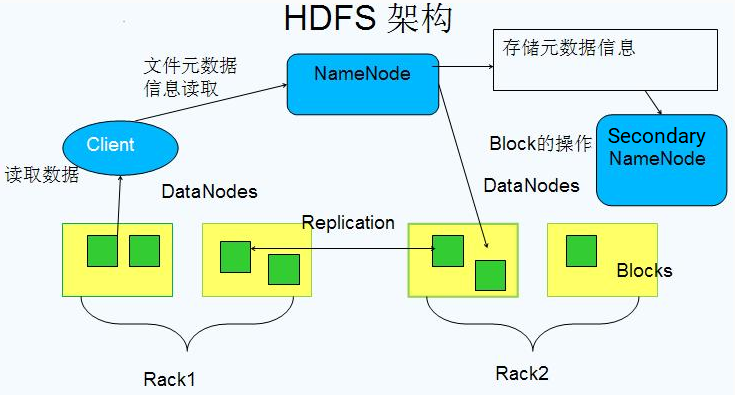
- HDFS架构
- https://www.w3cschool.cn/hadoop/xvmi1hd6.html
- HDFS:Hadoop Distributed File System,分布式文件系统
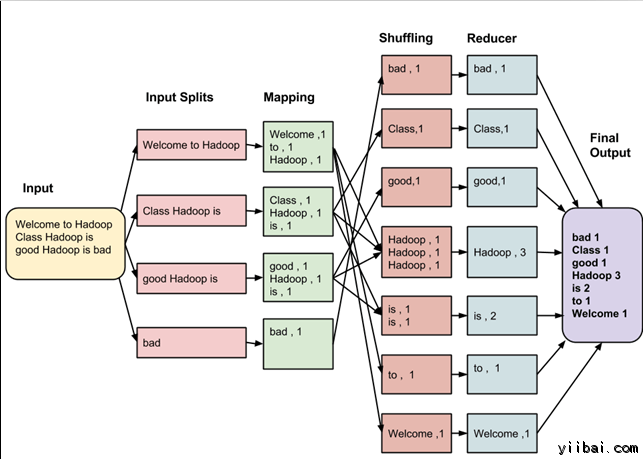
- MapReduce计算
- https://www.yiibai.com/hadoop/intro-mapreduce.html
- 介绍:一种分布式的计算方式指定一个Map(映#x5C04;)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组
- 输入:
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad
- 步骤:
输入拆分:input splits
输入到MapReduce工作被划分成固定大小的块叫做 input splits ,输入折分是由单个映射消费输入块。(对于大多数作业,最好是分割成大小等于一个HDFS块的大小(这是64 MB,默认情况下)。
映射 - Mapping
这是在 map-reduce 程序执行的第一个阶段。在这个阶段中的每个分割的数据被传递给映射函数来产生输出值。在我们的例子中,映射阶段的任务是计算输入分割出现每个单词的数量(更多详细信息有关输入分割在下面给出)并编制以某一形式列表<单词,出现频率>
重排 - Shuffling
这个阶段消耗映射阶段的输出。它的任务是合并映射阶段输出的相关记录。在我们的例子,同样的词汇以及它们各自出现频率。
Reducing
在这一阶段,从重排阶段输出值汇总。这个阶段结合来自重排阶段值,并返回一个输出值。总之,这一阶段汇总了完整的数据集。
在我们的例子中,这个阶段汇总来自重排阶段的值,计算每个单词出现次数的总和。
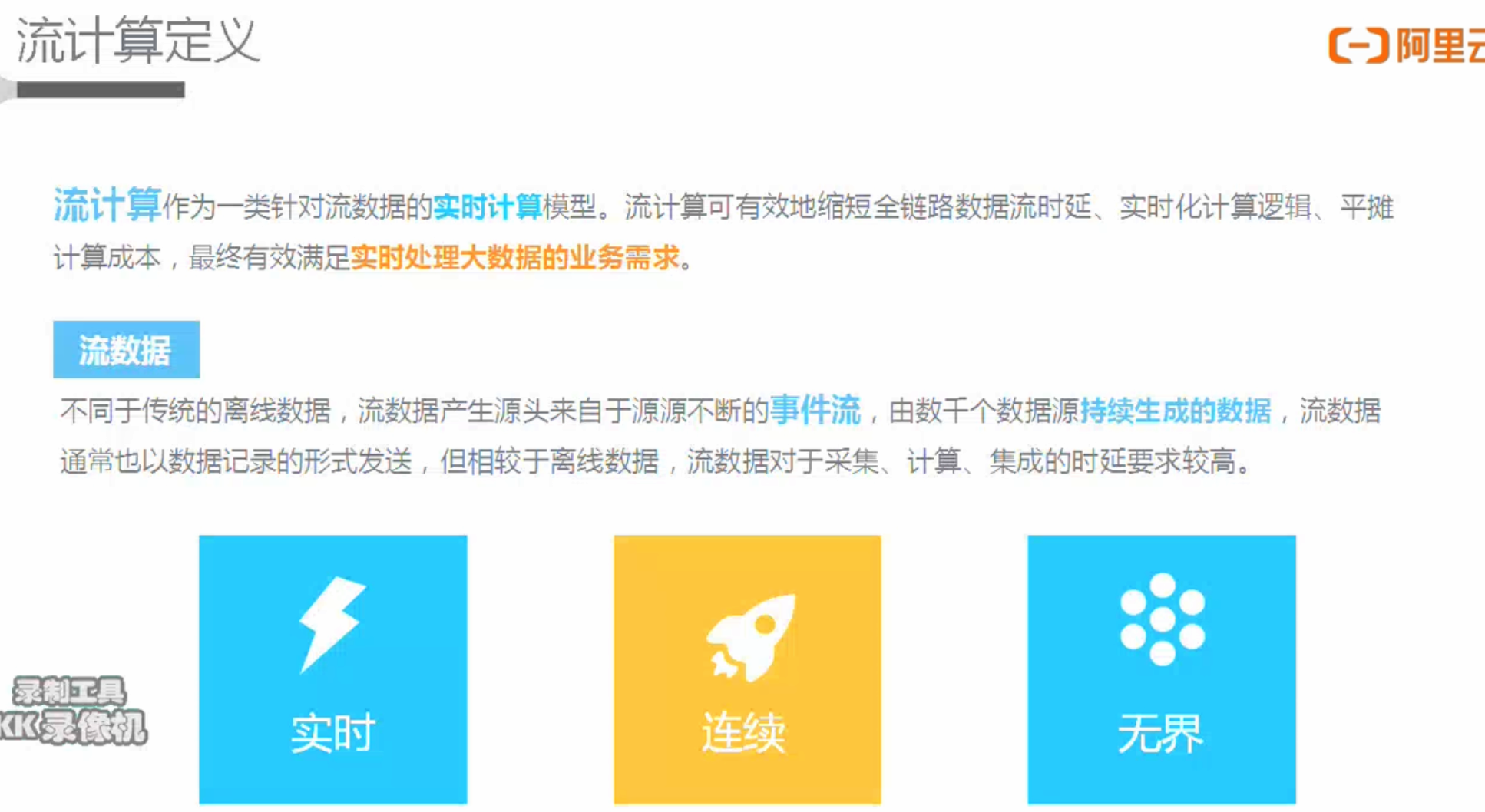
流计算(Streaming或实时计算)
| 批处理Batch | 流处理Streaming | |
| 数据 | 有界数据集(已经落盘的) | 无界数据集(源源不断进来的) |
| 有序数据集(因为已经落盘,可以order by排序等) | 无序数据集(可能后发生的先到) | |
| 运行 | 定时调度 | 启动一次 |
| 数据处理完任务结束 | 任务一直运行 | |
| 时效 | 小时/天 | 秒级/毫秒级 |
| 例子 |
Hadoop的mapreduce spark |
Flink |
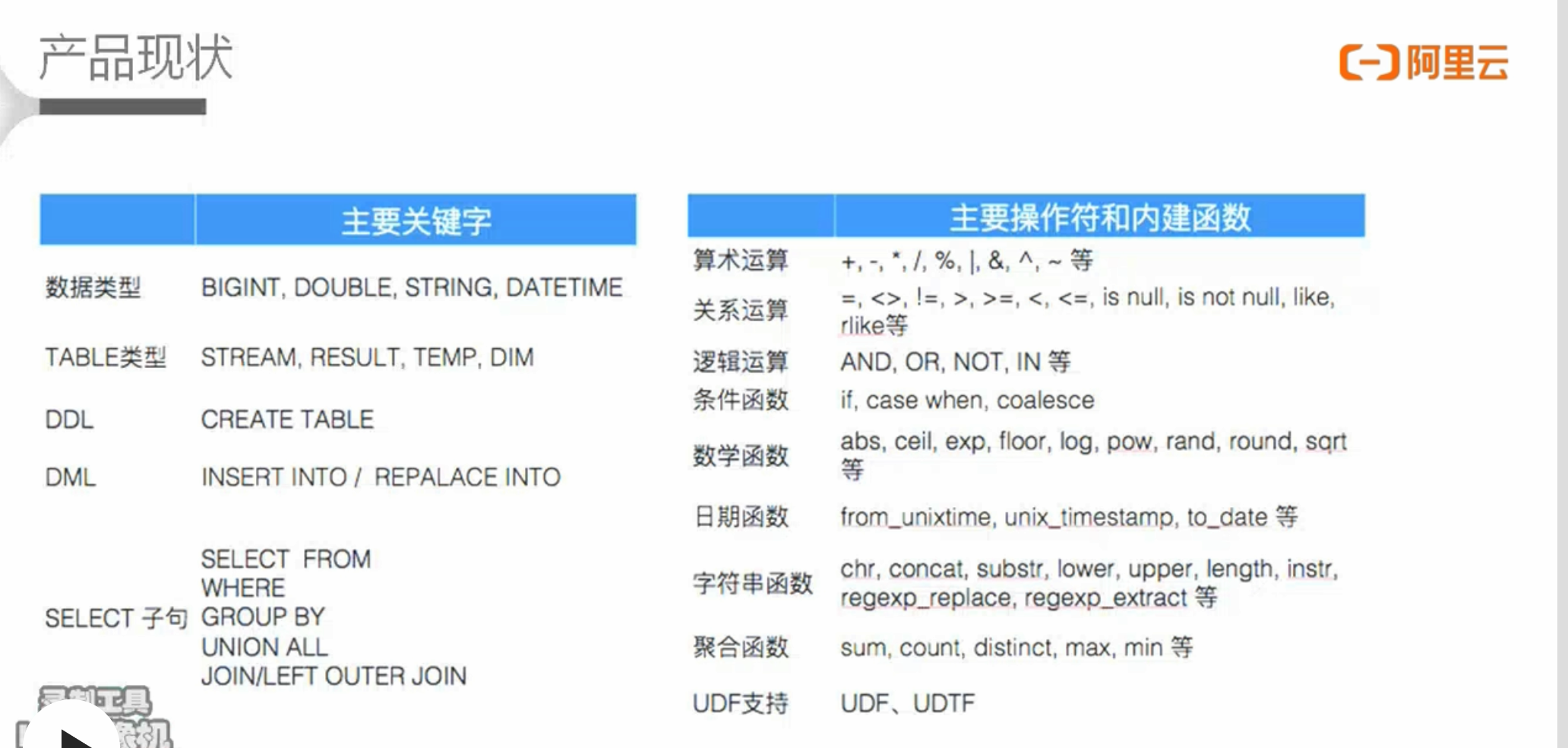
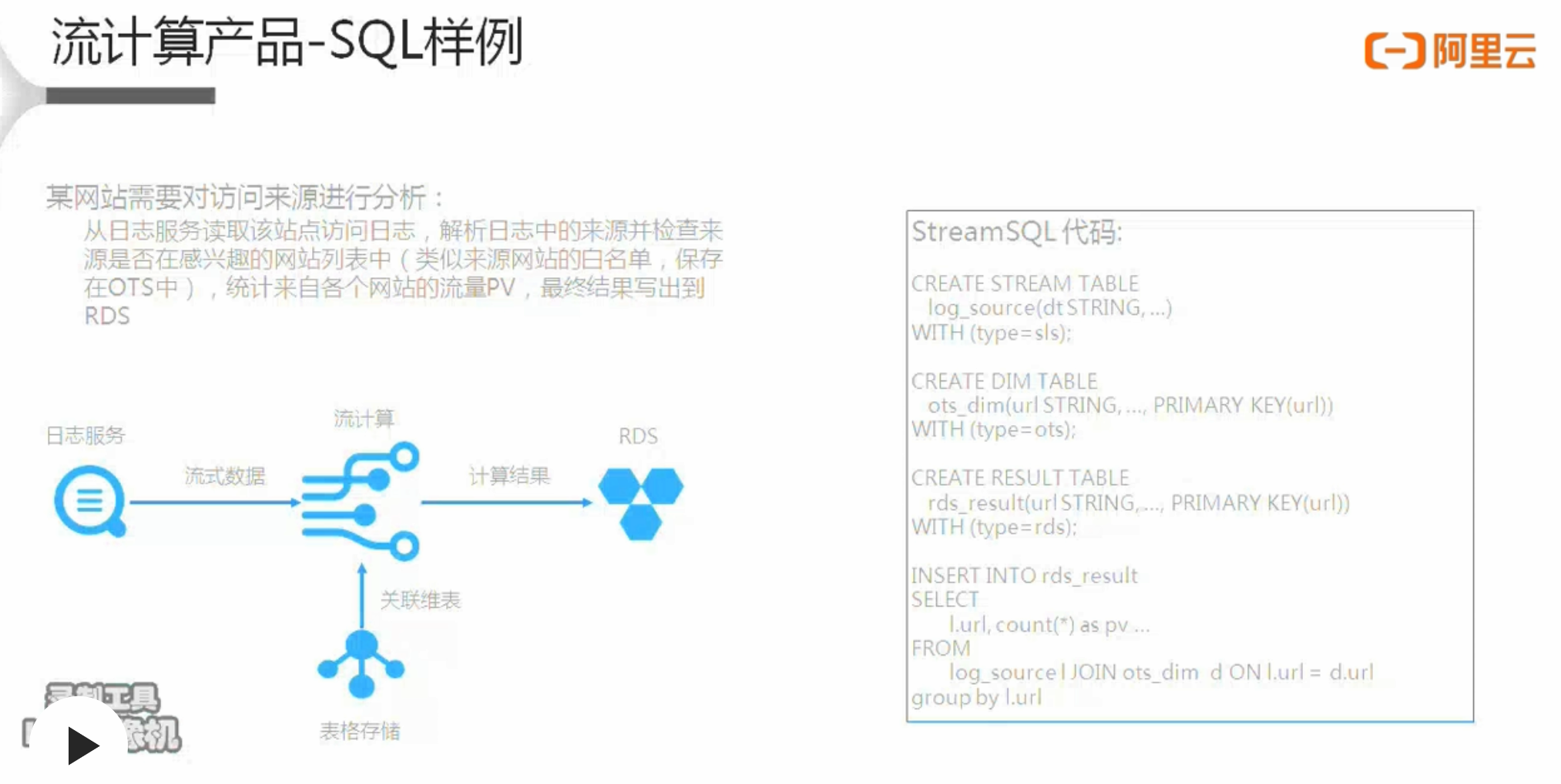
流计算SQL样例1
例:
某网站需要对访问来源进行分析:
从日志服务读取该站点访问日志,解析日志中的来源并检查来源是否在感兴趣的网站列表中(类似来源网站的白名单,保存在OTS中),统计来自各个网站的流量PV,最终结果写出到 RDS
流计算SQL样例2
热词统计分析实际上就是一个简单的Word Count任务,而流式实时热词统计分析将Word Count处理逻辑整体转换为流式实时处理,可以做到实时对热词进行统计分析,并可以实时展现。
需要创建源表、创建结果表、计算逻辑。

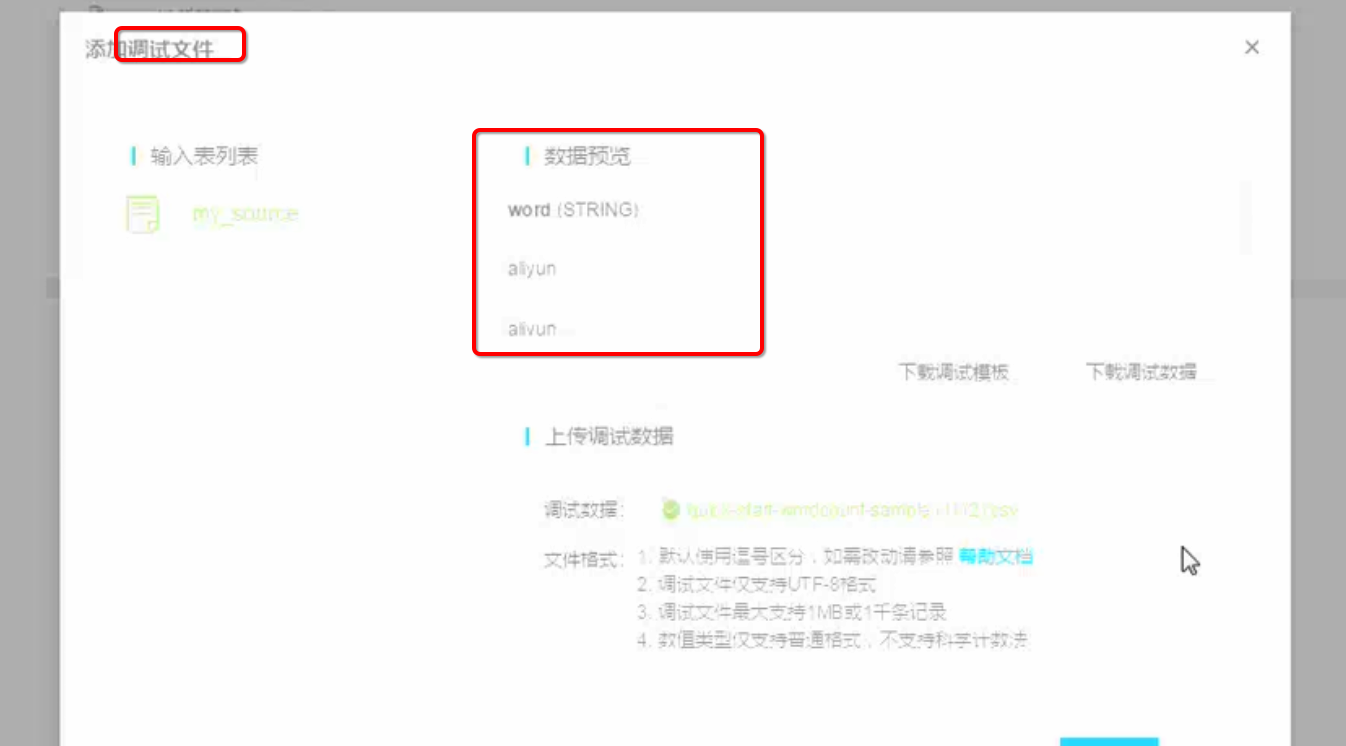
调试数据:3行aiyun,1行alibaba
会把整个运算过程都打印出来,下游做存储的时候,会进行去重,存储的就是aliyun 3, alibaba 1

流计算SQL样例3
要求:按天聚合当天的交易笔数,交易金额


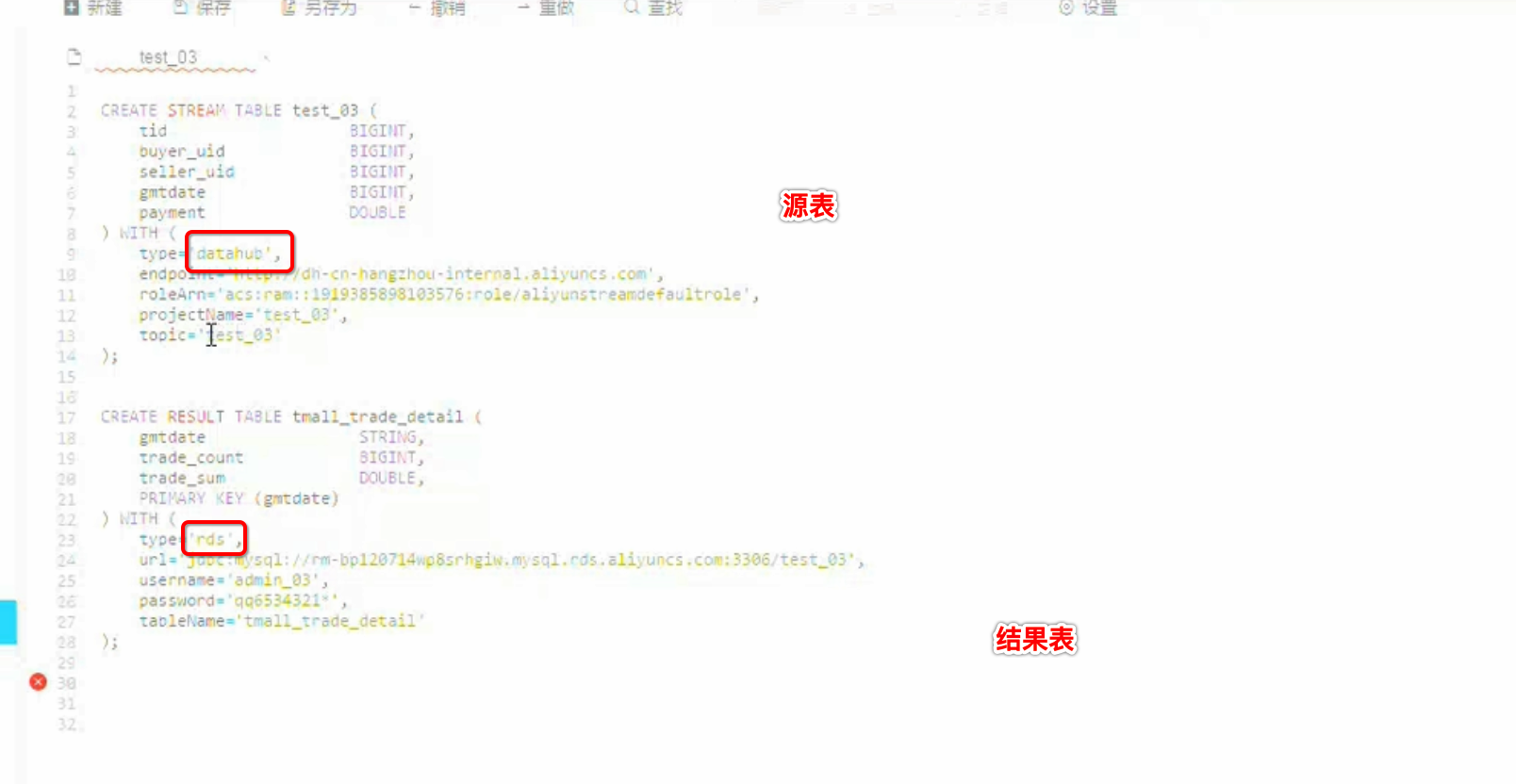
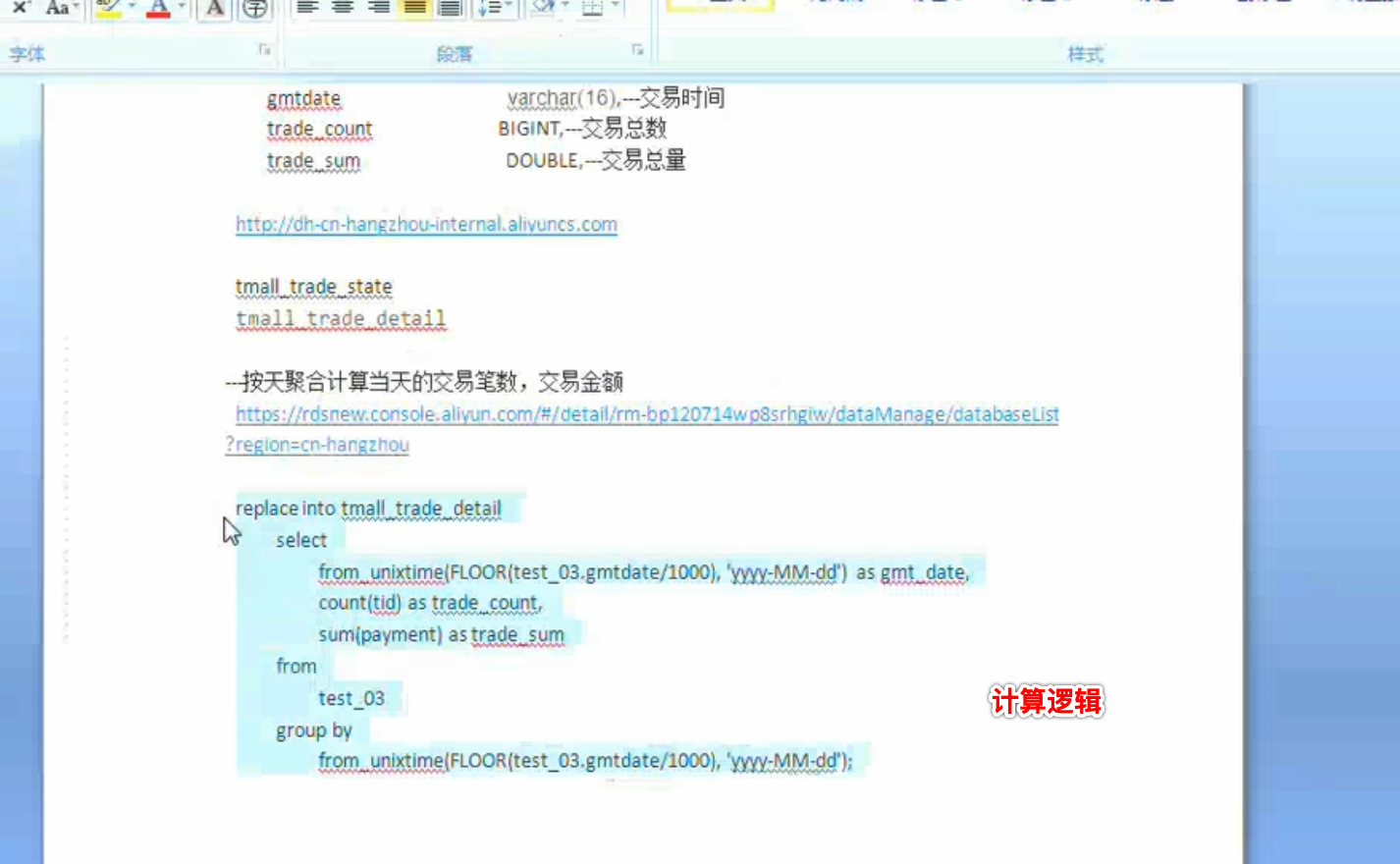
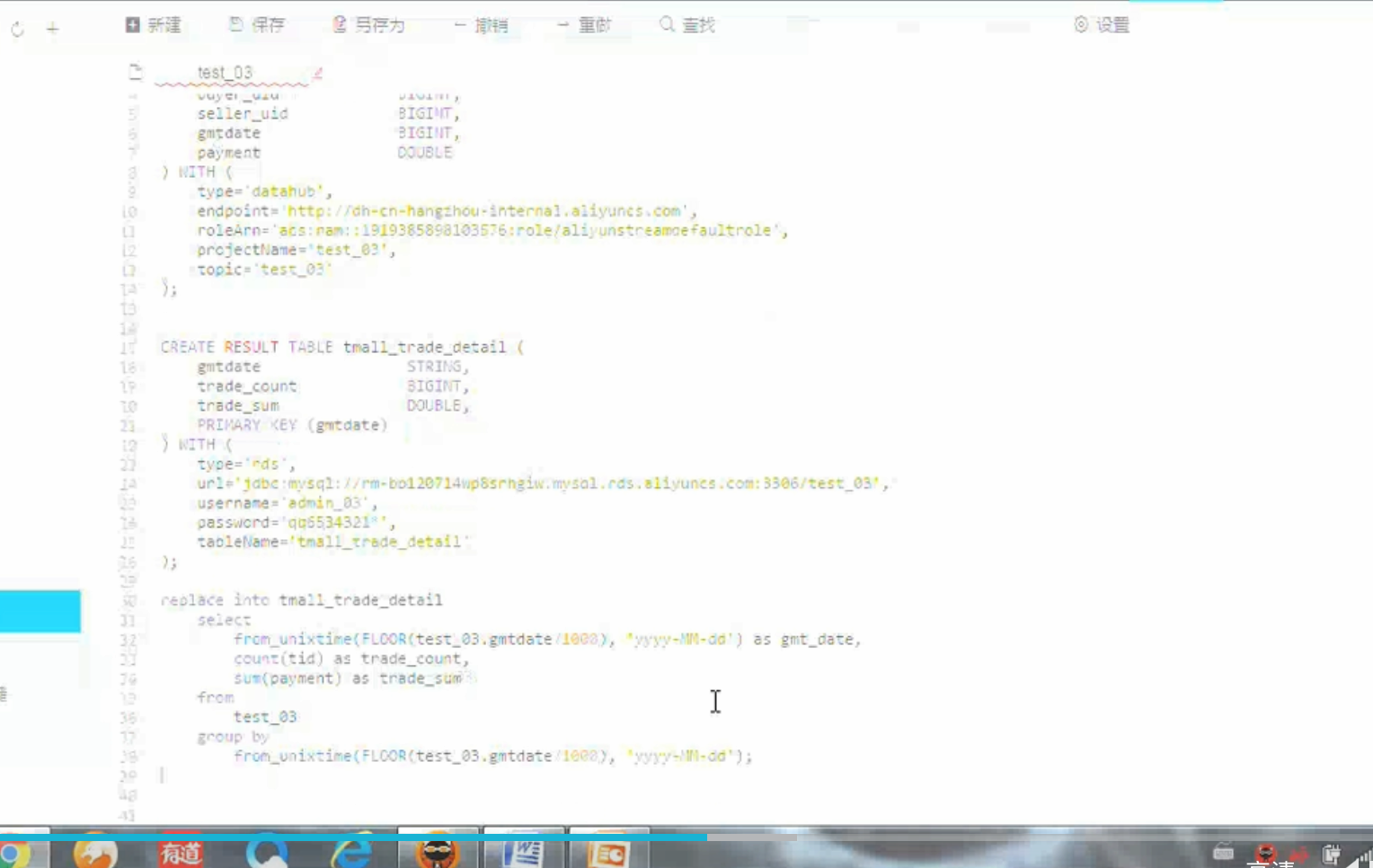
调试数据:

最佳实践


批处理(Batch或离线计算)和流计算(Streaming或实时计算)的更多相关文章
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 实时计算Flink on Kubernetes产品模式介绍
Flink产品介绍 目前实时计算的产品已经有两种模式,即共享模式和独享模式.这两种模式都是全托管方式,这种托管方式下用户不需要关心整个集群的运维.其次,共享模式和独享模式使用的都是Blink引擎.这两 ...
- vivo 实时计算平台建设实践
作者:vivo 互联网实时计算团队- Chen Tao 本文根据"2022 vivo开发者大会"现场演讲内容整理而成. vivo 实时计算平台是 vivo 实时团队基于 Apach ...
- 实时计算轻松上手,阿里云DataWorks Stream Studio正式发布
Stream Studio是DataWorks旗下重磅推出的全新子产品.已于2019年4月18日正式对外开放使用.Stream Studi是一站式流计算开发平台,基于阿里巴巴实时计算引擎Flink构建 ...
- Storm实时计算:流操作入门编程实践
转自:http://shiyanjun.cn/archives/977.html Storm实时计算:流操作入门编程实践 Storm是一个分布式是实时计算系统,它设计了一种对流和计算的抽象,概念比 ...
- ffmpeg protocol concat 进行ts流合并视频的时间戳计算及其音画同步方式一点浅析
ffmpeg protocol concat 进行ts流合并视频的时间戳计算及音画同步方式一点浅析 目录 ffmpeg protocol concat 进行ts流合并视频的时间戳计算及音画同步方式一点 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
随机推荐
- Java开发大型互联网-架构师必须掌握的分布式技术
Java开发大型互联网-架构师必须掌握的分布式技术 摘要:在当今互联网行业,随着用户量和业务的不断增长,大型互联网系统的设计和开发已经成为了一项头等重要的任务.作为架构师,要能够应对这样的挑战,就必须 ...
- NOIP模拟测试A2
好像是去年 8 月 1 日的模拟赛,主题采自南昌起义. 背景 A. 南 一道可爱的期望 DP. 一般来说,期望 DP 都是逆推,从最终状态往前推,这题也不例外. 这道题难度主要在于,第 \(k\) 次 ...
- 【pandas小技巧】--按类型选择列
本篇介绍的是pandas选择列数据的一个小技巧.之前已经介绍了很多选择列数据的方式,比如loc,iloc函数,按列名称选择,按条件选择等等. 这次介绍的是按照列的数据类型来选择列,按类型选择列可以帮助 ...
- 【go笔记】TCP编程
前言 TCP服务端的处理流程 监听端口 接收客户端请求建立连接 创建goroutine处理链接 示例代码:TCP服务端 package main import ( "net" &q ...
- selenium + python自动化环境搭建
Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firef ...
- vue 脚手架文件结构及加载过程浅谈
1. 初始化脚手架 1.1 全局安装 @vue/cli npm install -g @vue/cli 1.2 切换到创建项目的目录,执行 vue create projectname 1.3 选 ...
- ipa客户端安装
ipa客户端安装 安装操作官网 非交互式安装IPa客户端 kinit admin ipa host-find ipa host-add ipa host-add --help ipa host-add ...
- GIS中的ROI文件可否由.xml格式转为.roi格式?
本文介绍在ENVI软件中,将用户自行绘制的.xml格式的感兴趣区(ROI)文件转换为.roi格式的方法. 对于ENVI软件,其在早期版本中,默认将用户所绘制的感兴趣区文件保存为.roi格式:而 ...
- Modbus转Profinet网关改写变频器运行状态在1200PLC程序控制实例
兴达易控Modbus转Profinet网关将丹佛斯变频器接入西门子 1200PLC 配置案例 案例简介: 本案例是兴达易控Modbus转Profinet网关连接丹佛斯变频器在西门子 1200PLC程序 ...
- MySQL实战实战系列 07 行锁功过:怎么减少行锁对性能的影响?
在上一篇文章中,我跟你介绍了 MySQL 的全局锁和表级锁,今天我们就来讲讲 MySQL 的行锁. MySQL 的行锁是在引擎层由各个引擎自己实现的.但并不是所有的引擎都支持行锁,比如 MyISAM ...