《SQL与数据库基础》08. 多表查询
本文以 MySQL 为例
多表查询
多表关系
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,基本上分为三种:
- 一对多(多对一)
- 多对多
- 一对一
一对多
案例:部门与员工的关系。
关系:一个部门对应多个员工,一个员工对应一个部门
实现:在多的一方建立外键,指向一的一方的主键
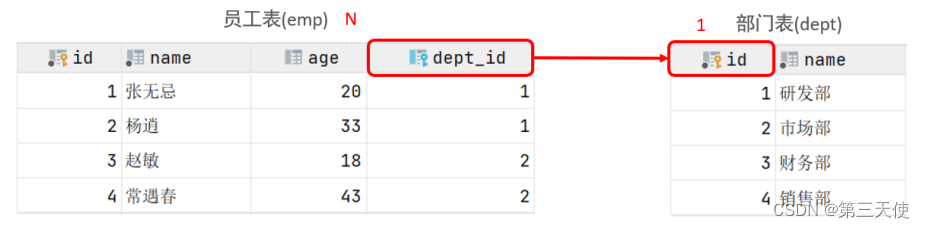
以上案例对应的SQL脚本:
CREATE TABLE dept(
id INT AUTO_INCREMENT COMMENT 'ID' PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT '部门名称'
)COMMENT '部门表';
INSERT INTO dept (id, name) VALUES (1, '研发部'), (2, '市场部'), (3, '财务部'), (4, '销售部'), (5, '总经办'), (6, '人事部');
CREATE TABLE emp(
id INT AUTO_INCREMENT COMMENT 'ID' PRIMARY KEY,
name VARCHAR(50) NOT NULL COMMENT '姓名',
age INT COMMENT '年龄',
job VARCHAR(20) COMMENT '职位',
salary INT COMMENT '薪资',
entrydate DATE COMMENT '入职时间',
managerid INT COMMENT '直属领导ID',
dept_id INT COMMENT '部门ID'
)COMMENT '员工表';
ALTER TABLE emp ADD CONSTRAINT fk_emp_dept_id FOREIGN KEY (dept_id) REFERENCES dept(id);
INSERT INTO emp (id, name, age, job, salary, entrydate, managerid, dept_id)
VALUES(1, '金庸', 66, '总裁',20000, '2000-01-01', null,5),
(2, '张无忌', 20, '项目经理',12500, '2005-12-05', 1,1),
(3, '杨逍', 33, '开发', 8400,'2000-11-03', 2,1),
(4, '韦一笑', 48, '开发',11000, '2002-02-05', 2,1),
(5, '常遇春', 43, '开发',10500, '2004-09-07', 3,1),
(6, '小昭', 19, '程序员鼓励师',6600, '2004-10-12', 2,1),
(7, '灭绝', 60, '财务总监',8500, '2002-09-12', 1,3),
(8, '周芷若', 19, '会计',48000, '2006-06-02', 7,3),
(9, '丁敏君', 23, '出纳',5250, '2009-05-13', 7,3),
(10, '赵敏', 20, '市场部总监',12500, '2004-10-12', 1,2),
(11, '鹿杖客', 56, '职员',3750, '2006-10-03', 10,2),
(12, '鹤笔翁', 19, '职员',3750, '2007-05-09', 10,2),
(13, '方东白', 19, '职员',5500, '2009-02-12', 10,2),
(14, '张三丰', 88, '销售总监',14000, '2004-10-12', 1,4),
(15, '俞莲舟', 38, '销售',4600, '2004-10-12', 14,4),
(16, '宋远桥', 40, '销售',4600, '2004-10-12', 14,4),
(17, '陈友谅', 42, null,2000, '2011-10-12', 1,null);
多对多
案例:学生与课程的关系
关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
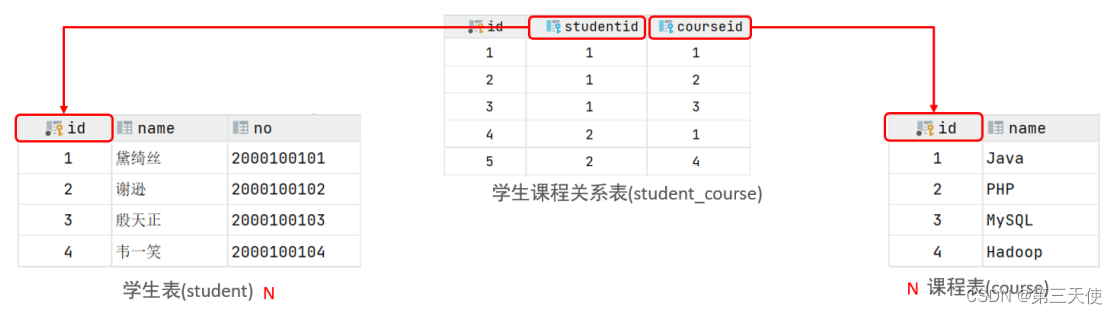
以上案例对应的SQL脚本:
CREATE TABLE student(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(10) COMMENT '姓名',
stuno VARCHAR(10) COMMENT '学号'
) COMMENT '学生表';
INSERT INTO student VALUES(null, '黛绮丝', '2000100101'), (null, '谢逊', '2000100102'), (null, '殷天正', '2000100103'), (null, '韦一笑', '2000100104');
CREATE TABLE course(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(10) COMMENT '课程名称'
) COMMENT '课程表';
INSERT INTO course VALUES (null, 'Java'), (null, 'PHP'), (null , 'MySQL') ,(null, 'Hadoop');
CREATE TABLE student_course(
id INT AUTO_INCREMENT COMMENT '主键' PRIMARY KEY,
studentid INT NOT NULL COMMENT '学生ID',
courseid INT NOT NULL COMMENT '课程ID',
CONSTRAINT fk_courseid FOREIGN KEY (courseid) REFERENCES course (id),
CONSTRAINT fk_studentid FOREIGN KEY (studentid) REFERENCES student (id)
) COMMENT '学生课程中间表';
INSERT INTO student_course VALUES (null, 1, 1), (null, 1, 2), (null, 1, 3), (null, 2, 2), (null, 2, 3), (null, 3, 4);
一对一
案例:用户与用户详情的关系
关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中,以提升操作效率
实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
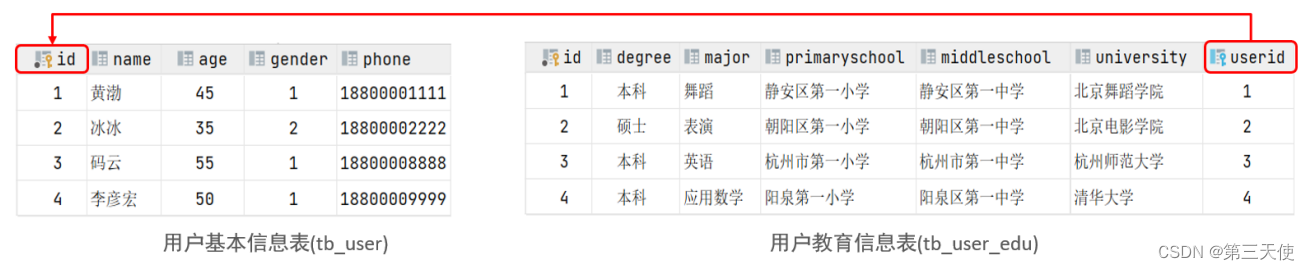
以上案例对应的SQL脚本:
CREATE TABLE tb_user(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键ID',
name VARCHAR(10) COMMENT '姓名',
age INT COMMENT '年龄',
gender CHAR(1) COMMENT '1: 男 , 2: 女',
phone CHAR(11) COMMENT '手机号'
) COMMENT '用户基本信息表';
CREATE TABLE tb_user_edu(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '主键ID',
degree VARCHAR(20) COMMENT '学历',
major VARCHAR(50) COMMENT '专业',
primaryschool VARCHAR(50) COMMENT '小学',
middleschool VARCHAR(50) COMMENT '中学',
university VARCHAR(50) COMMENT '大学',
userid INT UNIQUE COMMENT '用户ID',
CONSTRAINT fk_userid FOREIGN KEY (userid) REFERENCES tb_user(id)
) COMMENT '用户教育信息表';
INSERT INTO tb_user(id, name, age, gender, phone)
VALUES(null, '黄渤', 45, '1', '18800001111'),
(null, '冰冰', 35, '2', '18800002222'),
(null, '码云', 55, '1', '18800008888'),
(null, '李彦宏', 50, '1', '18800009999');
INSERT INTO tb_user_edu(id, degree, major, primaryschool, middleschool, university, userid)
VALUES(null, '本科', '舞蹈', '静安区第一小学', '静安区第一中学', '北京舞蹈学院', 1),
(null, '硕士', '表演', '朝阳区第一小学', '朝阳区第一中学', '北京电影学院', 2),
(null, '本科', '英语', '杭州市第一小学', '杭州市第一中学', '杭州师范大学', 3),
(null, '本科', '应用数学', '阳泉第一小学', '阳泉区第一中学', '清华大学', 4);
多表查询概述
多表查询就是指从多张表中查询数据。
以一对多中创建的员工表与部门表为例:
原来查询单表数据,执行的SQL形式为:SELECT * FROM emp;
执行多表查询,只需要使用逗号分隔多张表即可,如: SELECT * FROM emp, dept;,但这样会出现笛卡尔积情况
笛卡尔积:
笛卡尔乘积是指在数学中,两个集合 A集合 和 B集合 的所有组合情况。
在SQL语句中,可以给多表查询加上连接查询的条件来去除无效的笛卡尔积:
SELECT * FROM emp, dept WHERE emp.dept_id = dept.id;
分类
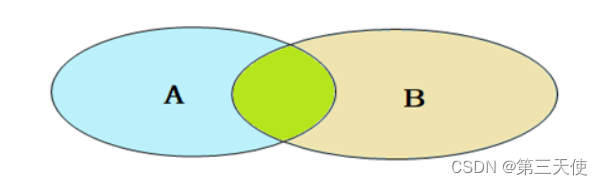
- 连接查询
- 内连接:相当于查询A、B交集部分数据
- 外连接:
- 左外连接:查询左表所有数据,以及两张表交集部分数据
- 右外连接:查询右表所有数据,以及两张表交集部分数据
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
- 子查询
内连接
内连接查询的是两张表交集部分的数据。
隐式内连接查询:
SELECT 字段列表 FROM 表1, 表2 WHERE 条件;
显式内连接查询:
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件;
注:
可以给表取别名,语法类似于给字段取别名。
一旦为表起了别名,就不能再使用表名来指定对应的字段了,此时只能够使用表别名来指定字段。
以一对多中创建的员工表与部门表为例:
/*
表结构: emp, dept
连接条件: emp.dept_id = dept.id
*/
/*
查询每一个员工的姓名,及关联的部门的名称
隐式内连接实现
*/
SELECT emp.name, dept.name FROM emp, dept WHERE emp.dept_id = dept.id;
# 为每一张表起别名,简化SQL编写
SELECT e.name, d.name FROM emp e, dept d WHERE e.dept_id = d.id;
/*
查询每一个员工的姓名,及关联的部门的名称
显式内连接实现
*/
SELECT e.name, d.name FROM emp e INNER JOIN dept d ON e.dept_id = d.id;
# 为每一张表起别名,简化SQL编写
SELECT e.name, d.name FROM emp e JOIN dept d ON e.dept_id = d.id;
/*
由于id为17的员工没有dept_id字段值,所以在内连接查询时,根据连接查询的条件并没有查询到。
*/
外连接
左外连接查询:
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
相当于查询表1(左表)的所有数据,也包含表1和表2交集部分的数据。
右外连接查询:
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
相当于查询表2(右表)的所有数据,也包含表1和表2交集部分的数据。
以一对多中创建的员工表与部门表为例:
/*
表结构: emp, dept
连接条件: emp.dept_id = dept.id
*/
# 查询emp表的所有数据,和对应的部门信息(左外连接)
SELECT e.*, d.name FROM emp e LEFT OUTER JOIN dept d ON e.dept_id = d.id;
# 查询dept表的所有数据,和对应的员工信息(右外连接与左外连接)
SELECT d.*, e.* FROM emp e RIGHT OUTER JOIN dept d ON e.dept_id = d.id;
SELECT d.*, e.* FROM dept d LEFT JOIN emp e ON e.dept_id = d.id;
左外连接和右外连接是可以相互替换的,只需要调整在连接查询时SQL中表结构的先后顺序就可以了。在日常开发使用时,更偏向于左外连接。
自连接
自连接查询:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件;
自连接查询可以是内连接查询,也可以是外连接查询。
以一对多中创建的员工表为例:
/*
表结构: emp
*/
# 查询员工及其所属领导的名字
SELECT a.name, b.name FROM emp a, emp b WHERE a.managerid = b.id;
# 查询所有员工及其领导的名字,如果员工没有领导,也需要查询出来
SELECT a.name '员工', b.name '领导' FROM emp a LEFT JOIN emp b ON a.managerid = b.id;
在自连接查询中,必须要为表起别名,要不然我们不清楚所指定的条件、返回的字段,到底 是哪一张表的字段。
联合查询
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
将两次查询结果直接合并:
SELECT 字段列表 FROM 表A
UNION ALL
SELECT 字段列表 FROM 表B;
将两次查询结果去重后再合并:
SELECT 字段列表 FROM 表A
UNION
SELECT 字段列表 FROM 表B;
以一对多中创建的员工表为例:
# 将薪资低于5000的员工,和年龄大于50岁的员工全部查询出来。
SELECT * FROM emp WHERE salary < 5000
UNION ALL
SELECT * FROM emp WHERE age > 50;
子查询
SQL语句中嵌套SELECT语句,称为嵌套查询,又称子查询。
语法:
SELECT * FROM 表1 WHERE 字段1 操作符 (SELECT 字段 FROM 表2);
子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一个。
分类
根据子查询结果不同,分为:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为一列)
- 行子查询(子查询结果为一行)
- 表子查询(子查询结果为多行多列)
根据子查询位置,分为:
- WHERE之后
- FROM之后
- SELECT之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等),这种子查询称为标量子查询。
常用操作符:=、<>、>、>=、<、<=
以一对多中创建的员工表为例:
# 查询“销售部”的所有员工信息
SELECT * FROM emp WHERE dept_id = (SELECT id FROM dept WHERE name = '销售部');
# 查询在“方东白”入职之后的员工信息
SELECT * FROM emp WHERE entrydate > (SELECT entrydate FROM emp WHERE name = '方东白');
列子查询
子查询返回的结果是一列(可以是多行),这种子查询称为列子查询。
常用操作符:IN、NOT IN、 ANY、SOME、 ALL
===================================================================
操作符 | 描述
-------------------------------------------------------------------
IN | 在指定的集合范围之内,多选一
NOT IN | 不在指定的集合范围之内
ANY | 子查询返回列表中,有任意一个满足即可
SOME | 与ANY等同,使用SOME的地方都可以使用ANY
ALL | 子查询返回列表的所有值都必须满足
===================================================================
以一对多中创建的员工表为例:
# 查询“销售部”和“市场部”的所有员工信息
SELECT * FROM emp WHERE dept_id IN (SELECT id FROM dept WHERE name = '销售部' OR name = '市场部');
# 查询比 财务部 所有人工资都高的员工信息
SELECT * FROM emp WHERE salary > ALL (SELECT salary FROM emp WHERE dept_id = (SELECT id FROM dept WHERE name = '财务部'));
行子查询
子查询返回的结果是一行(可以是多列),这种子查询称为行子查询。
常用的操作符:=、<>、IN、NOT IN
以一对多中创建的员工表为例:
# 查询与 张无忌 的薪资及直属领导相同的员工信息
SELECT * FROM emp WHERE (salary, managerid) = (SELECT salary, managerid FROM emp WHERE name = '张无忌');
表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询。
常用的操作符:IN
以一对多中创建的员工表与部门表为例:
/*
查询与 鹿杖客,宋远桥 的职位和薪资相同的员工信息
*/
# 1、查询 鹿杖客,宋远桥 的职位和薪资
SELECT job, salary FROM emp WHERE name = '鹿杖客' OR name = '宋远桥';
# 2、 查询与 鹿杖客,宋远桥 的职位和薪资相同的员工信息
SELECT * FROM emp WHERE (job, salary) IN (SELECT job, salary FROM emp WHERE name = '鹿杖客' OR name = '宋远桥');
/*
查询入职日期是 "2006-01-01" 之后的员工信息,及其部门信息
*/
# 1、入职日期是 "2006-01-01" 之后的员工信息
SELECT * FROM emp WHERE entrydate > '2006-01-01';
# 2、查询这部分员工,对应的部门信息
SELECT e.*, d.* FROM (SELECT * FROM emp WHERE entrydate > '2006-01-01') e LEFT JOIN dept d ON e.dept_id = d.id;
案例
以一对多中创建的员工表与部门表,以及下面的薪资表为例:
# 数据环境准备
CREATE TABLE salgrade(
grade INT,
losal INT,
hisal INT
) COMMENT '薪资等级表';
INSERT INTO salgrade VALUES (1, 0, 3000);
INSERT INTO salgrade VALUES (2, 3001, 5000);
INSERT INTO salgrade VALUES (3, 5001, 8000);
INSERT INTO salgrade VALUES (4, 8001, 10000);
INSERT INTO salgrade VALUES (5, 10001, 15000);
INSERT INTO salgrade VALUES (6, 15001, 20000);
INSERT INTO salgrade VALUES (7, 20001, 25000);
INSERT INTO salgrade VALUES (8, 25001, 30000);
/*
查询员工的姓名、年龄、职位、部门信息(隐式内连接)
表: emp,dept
连接条件: emp.dept_id = dept.id
*/
SELECT e.name, e.age, e.job, d.name FROM emp e, dept d WHERE e.dept_id = d.id;
/*
查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接)
表: emp,dept
连接条件: emp.dept_id = dept.id
*/
SELECT e.name, e.age, e.job, d.name FROM emp e INNER JOIN dept d ON e.dept_id = d.id WHERE e.age < 30;
/*
查询拥有员工的部门ID、部门名称
表: emp,dept
连接条件: emp.dept_id = dept.id
*/
SELECT DISTINCT d.id, d.name FROM emp e, dept d WHERE e.dept_id = d.id;
/*
查询所有年龄大于40岁的员工,及其归属的部门名称;如果员工没有分配部门,也需要展示出来(外连接)
表: emp,dept
连接条件: emp.dept_id = dept.id
*/
SELECT e.*, d.name FROM emp e LEFT JOIN dept d ON e.dept_id = d.id WHERE e.age > 40;
/*
查询所有员工的工资等级
表: emp,salgrade
连接条件: emp.salary >= salgrade.losal and emp.salary <= salgrade.hisal
*/
SELECT e.*, s.grade, s.losal, s.hisal FROM emp e, salgrade s WHERE e.salary BETWEEN s.losal AND s.hisal;
/*
查询 "研发部" 所有员工的信息及工资等级
表: emp,salgrade,dept
连接条件: emp.salary between salgrade.losal and salgrade.hisal, emp.dept_id = dept.id
查询条件: dept.name = '研发部'
*/
SELECT e.*, s.grade FROM emp e, dept d, salgrade s WHERE e.dept_id = d.id AND (e.salary BETWEEN s.losal AND s.hisal) AND d.name = '研发部';
/*
查询 "研发部" 员工的平均工资
表: emp,dept
连接条件: emp.dept_id = dept.id
*/
SELECT AVG(e.salary) FROM emp e, dept d WHERE e.dept_id = d.id AND d.name = '研发部';
/*
查询工资比 "灭绝" 高的员工信息。
*/
# 1、 查询 "灭绝" 的薪资
SELECT salary FROM emp WHERE name = '灭绝';
# 2、查询比她工资高的员工数据
SELECT * FROM emp WHERE salary > (SELECT salary FROM emp WHERE name = '灭绝');
/*
查询比平均薪资高的员工信息
*/
# 1、查询员工的平均薪资
SELECT AVG(salary) FROM emp;
# 2、查询比平均薪资高的员工信息
SELECT * FROM emp WHERE salary > (SELECT AVG(salary) FROM emp);
/*
查询低于本部门平均工资的员工信息
*/
# 1、查询指定部门平均薪资
SELECT AVG(e1.salary) FROM emp e1 WHERE e1.dept_id = 1;
SELECT AVG(e1.salary) FROM emp e1 WHERE e1.dept_id = 2;
......
# 2、 查询低于本部门平均工资的员工信息
SELECT * FROM emp e2 WHERE e2.salary < (SELECT AVG(e1.salary) FROM emp e1 WHERE e1.dept_id = e2.dept_id);
/*
查询所有的部门信息, 并统计部门的员工人数
*/
SELECT d.id, d.name, (SELECT COUNT(*) FROM emp e WHERE e.dept_id = d.id) '人数' FROM dept d;
以多对多中学生与课程的关系为例:
/*
查询所有学生的选课情况,展示出学生名称,学号,课程名称
表: student,course,student_course
连接条件: student.id = student_course.studentid,course.id = student_course.courseid
*/
SELECT s.name, s.stuno, c.name FROM student s, student_course sc, course c WHERE s.id = sc.studentid AND sc.courseid = c.id;
《SQL与数据库基础》08. 多表查询的更多相关文章
- Sql Server数据库基础
--------------------------------------第一章 Sql Server数据库基础------------------------------------------ ...
- C#面试题(转载) SQL Server 数据库基础笔记分享(下) SQL Server 数据库基础笔记分享(上) Asp.Net MVC4中的全局过滤器 C#语法——泛型的多种应用
C#面试题(转载) 原文地址:100道C#面试题(.net开发人员必备) https://blog.csdn.net/u013519551/article/details/51220841 1. . ...
- python实现简易数据库之二——单表查询和top N实现
上一篇中,介绍了我们的存储和索引建立过程,这篇将介绍SQL查询.单表查询和TOPN实现. 一.SQL解析 正规的sql解析是用语法分析器,但是我找了好久,只知道可以用YACC.BISON等,sqlit ...
- mysql 基础入门 单表查询
单表查询 select 表头,表头 as 别名 ,表头(+-*/的运算) from table_a 1.条件查询 where + 条件 <> , != 不等于 = 等于,也可以表示字符串值 ...
- SQL总结(二)连表查询
---恢复内容开始--- SQL总结(二)连表查询 连接查询包括合并.内连接.外连接和交叉连接,如果涉及多表查询,了解这些连接的特点很重要. 只有真正了解它们之间的区别,才能正确使用. 1.Union ...
- 非关心数据库无法进行连表查询 所以我们需要在进行一对多查询时候 无法满足 因此需要在"1"的一方添加"多"的一方的的id 以便用于进行连表查询 ; 核心思想通过id进行维护与建文件
非关心数据库无法进行连表查询 所以我们需要在进行一对多查询时候 无法满足 因此需要在"1"的一方添加"多"的一方的的id 以便用于进行连表查询 ; 核心思想通 ...
- 学数据库还不会Select,SQL Select详解,单表查询完全解析?
查询操作是SQL语言中很重要的操作,我们今天就来详细的学习一下. 一.数据查询的语句格式 SELECT [ALL|DISTINCT] <目标列表达式>[,<目标列表达式> .. ...
- 【SQL基础】多表查询:子查询、连接查询(JOIN)、组合查询(UNION集合运算)
〇.概述 1.内容 JOIN表连接(内连接INNER JOIN/JOIN)(外连接LEFT/RIGHT (OUTER) JOIN) 集合运算-UNION联合 2.建表语句 drop table if ...
- SQL Server 数据库基础笔记分享(下)
前言 本文是个人学习SQL Server 数据库时的以往笔记的整理,内容主要是对数据库的基本增删改查的SQL语句操作和约束,视图,存储过程,触发器的基本了解. 注:内容比较基础,适合入门者对SQL S ...
- SQL Server 数据库基础笔记分享(上)
前言 本文是个人学习SQL Server 数据库时的以往笔记的整理,内容主要是对数据库的基本增删改查的SQL语句操作和约束,视图,存储过程,触发器的基本了解. 注:内容比较基础,适合入门者对SQL S ...
随机推荐
- select_related和prefetch_related函数
在数据库存在外键的其情况下,使用select_related()和prefetch_related()很大程度上减少对数据库的请求次数以提高性能 在表中查找数据的时候,使用外键表related_nam ...
- django之drf(部分讲解)
序列化类常用字段和字段参数 drf在Django字段类型的基础上派生了自己的字段类型以及字段参数 序列化器的字段类型用于处理原始值和内部数据类型直接的转换 还可以用于验证输入.以及父对象检索和设置值 ...
- 图数据库 NebulaGraph 的内存管理实践之 Memory Tracker
数据库的内存管理是数据库内核设计中的重要模块,内存的可度量.可管控是数据库稳定性的重要保障.同样的,内存管理对图数据库 NebulaGraph 也至关重要. 图数据库的多度关联查询特性,往往使图数据库 ...
- 【C#代码整洁之道】读后习题
1)劣质的代码会带来什么后果? GPT回答: 可维护性降低:代码过于复杂.难以理解.难以修改,导致维护成本增加,代码质量更加恶化. 可靠性降低:错误容易发生,很难找到并修复,因为代码模糊.逻辑混乱,并 ...
- GroundingDINO(一种开集目标检测算法)服务化,根据文本生成检测框
背景 最近发现一个叫GroundingDINO的开集目标检测算法,所谓开集目标检测就是能检测的目标类别不局限于训练的类别,这个算法可以通过输入文本的prompt然后输出对应的目标框.可以用来做预标注或 ...
- 由C# yield return引发的思考
前言 当我们编写 C# 代码时,经常需要处理大量的数据集合.在传统的方式中,我们往往需要先将整个数据集合加载到内存中,然后再进行操作.但是如果数据集合非常大,这种方式就会导致内存占用过高,甚至可能导致 ...
- Linux目录结构及常用命令
目录 Linux目录结构... 1 Linux目录结构... 1 1. Linux常用命令... 4 1.1 Linux命令初体验... 4 1.2 文件目录操作命令... 8 1.3 拷贝移动命令. ...
- 「有问必答」Go如何优雅的对时间进行格式化?
昨天 交流群 关于「Go如何优雅的对时间进行格式化?」展开了讨论: 咋搞捏? 如何在不循环的情况下,把列表数据结构体的时间修改为咱们习惯的格式,而不是UTC模式 我们要实现的效果如下: created ...
- GPT3的技术突破:实现更准确、更真实的语言生成
目录 1. 引言 2. 技术原理及概念 3. 实现步骤与流程 4. 应用示例与代码实现讲解 5. 优化与改进 6. 结论与展望 7. 附录:常见问题与解答 GPT-3 技术突破:实现更准确.更真实的语 ...
- 10分钟讲清int 和 Integer 的区别
其实在Java编程中,int和Integer都是非常常用的数据类型,但它们之间存在一些关键的区别,特别是在面向对象编程中.所以接下来,就让我们一起来探讨下关于int和Integer的区别这个问题吧. ...