聊透 GPU 通信技术——GPU Direct、NVLink、RDMA 审核中
最近人工智能大火,AI 应用所涉及的技术能力包括语音、图像、视频、NLP 等多方面,而这些都需要强大的计算资源支持。AI 技术对算力的需求是非常庞大的,虽然 GPU 的计算能力在持续提升,但是对于 AI 来说,单卡的计算能力就算再强,也是有极限的,这就需要多 GPU 组合。而 GPU 多卡的组合,主要分为单个服务器多张 GPU 卡和多个服务器,每个服务器多张卡这两种情况,无论是单机多卡还是多机多卡,GPU 之间需要有超强的通信支持。接下来,我们就来聊聊 GPU 通信技术。
单机多卡GPU通信
GPU Direct
GPU Direct 是 NVIDIA 开发的一项技术,可实现 GPU 与其他设备(例如网络接口卡 (NIC) 和存储设备)之间的直接通信和数据传输,而不涉及 CPU。
传统上,当数据需要在 GPU 和另一个设备之间传输时,数据必须通过 CPU,从而导致潜在的瓶颈并增加延迟。使用 GPUDirect,网络适配器和存储驱动器可以直接读写 GPU 内存,减少不必要的内存消耗,减少 CPU 开销并降低延迟,从而显著提高性能。GPU Direct 技术包括 GPUDirect Storage、GPUDirect RDMA、GPUDirect P2P 和 GPUDirect 视频。
GPUDirect Storage
GPUDirect Storage 允许存储设备和 GPU 之间进行直接数据传输,绕过 CPU,减少数据传输的延迟和 CPU 开销。
通过 GPUDirect Storage,GPU 可以直接从存储设备(如固态硬盘(SSD)或非易失性内存扩展(NVMe)驱动器)访问数据,而无需将数据先复制到 CPU 的内存中。这种直接访问能够实现更快的数据传输速度,并更高效地利用 GPU 资源。
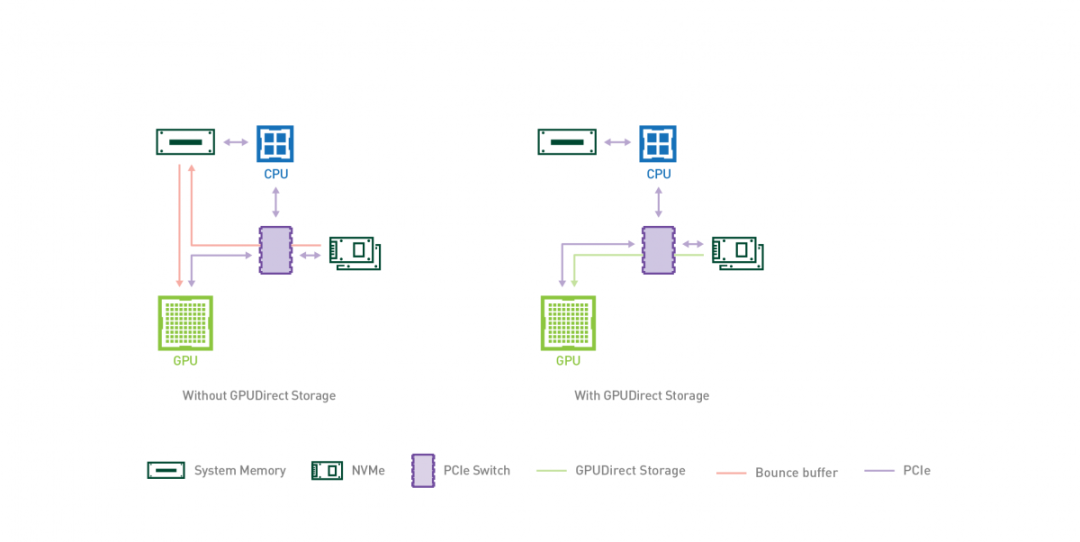
GPUDirect Storage 的主要特点和优势包括:
- 减少 CPU 参与:通过绕过 CPU,实现 GPU 和存储设备之间的直接通信,GPUDirect Storage 减少了 CPU 开销,并释放 CPU 资源用于其他任务,从而改善系统的整体性能。
- 低延迟数据访问:GPUDirect Storage 消除了数据通过 CPU 的传输路径,从而最小化了数据传输的延迟。这对于实时分析、机器学习和高性能计算等对延迟敏感的应用非常有益。
- 提高存储性能:通过允许 GPU 直接访问存储设备,GPUDirect Storage 实现了高速数据传输,可以显著提高存储性能,加速数据密集型工作负载的处理速度。
- 增强的可扩展性:GPUDirect Storage 支持多 GPU 配置,允许多个 GPU 同时访问存储设备。这种可扩展性对于需要大规模并行处理和数据分析的应用至关重要。
- 兼容性和生态系统支持:GPUDirect Storage 设计用于与各种存储协议兼容,包括 NVMe、NVMe over Fabrics和网络附加存储(NAS)。它得到了主要存储供应商的支持,并集成到流行的软件框架(如NVIDIA CUDA)中,以简化与现有的 GPU 加速应用程序的集成。
GPUDirect P2P
某些工作负载需要位于同一服务器中的两个或多个 GPU 之间进行数据交换,在没有 GPUDirect P2P 技术的情况下,来自 GPU 的数据将首先通过 CPU 和 PCIe 总线复制到主机固定的共享内存。然后,数据将通过 CPU 和 PCIe 总线从主机固定的共享内存复制到目标 GPU,数据在到达目的地之前需要被复制两次。

有了 GPUDirect P2P 通信技术后,将数据从源 GPU 复制到同一节点中的另一个 GPU 不再需要将数据临时暂存到主机内存中。如果两个 GPU 连接到同一 PCIe 总线,GPUDirect P2P 允许访问其相应的内存,而无需 CPU 参与。前者将执行相同任务所需的复制操作数量减半。
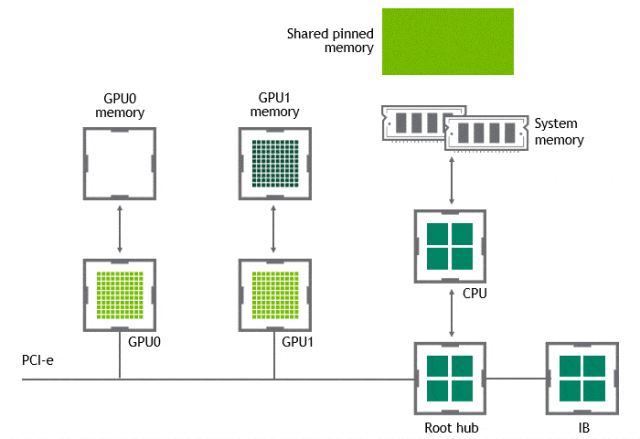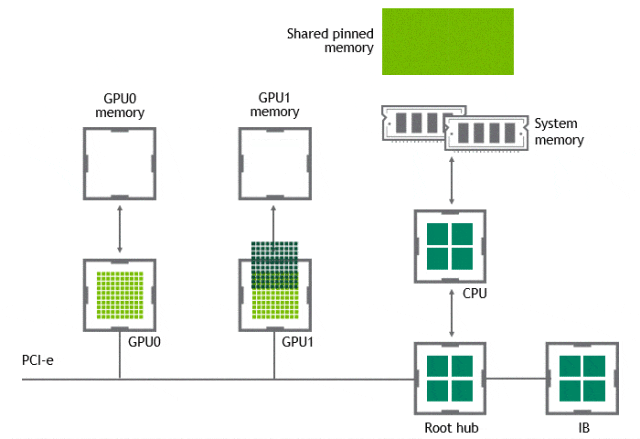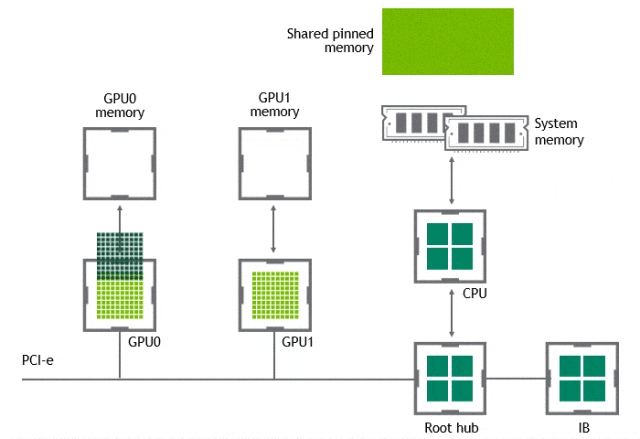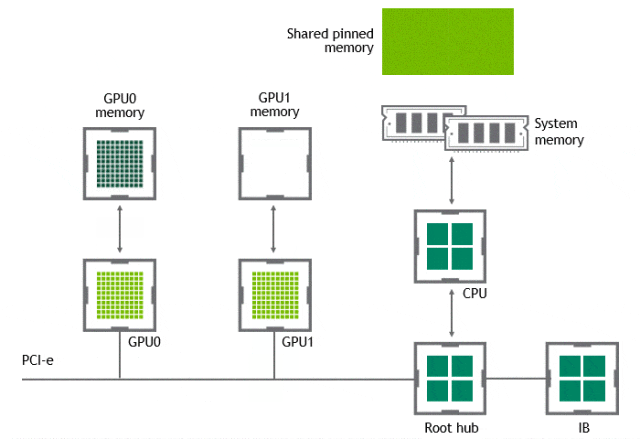
NVLink
在 GPUDirect P2P 技术中,多个 GPU 通过 PCIe 直接与 CPU 相连,而 PCIe3.0*16 的双向带宽不足 32GB/s,当训练数据不断增长时,PCIe 的带宽满足不了需求,会逐渐成为系统瓶颈。为提升多 GPU 之间的通信性能,充分发挥 GPU 的计算性能,NVIDIA 于 2016 年发布了全新架构的 NVLink。NVLink 是一种高速、高带宽的互连技术,用于连接多个 GPU 之间或连接 GPU 与其他设备(如CPU、内存等)之间的通信。NVLink 提供了直接的点对点连接,具有比传统的 PCIe 总线更高的传输速度和更低的延迟。
- 高带宽和低延迟:NVLink 提供了高达 300 GB/s 的双向带宽,将近 PCle 3.0 带宽的 10 倍。点对点连接超低延迟,可实现快速、高效的数据传输和通信。
- GPU 间通信:NVLink 允许多个 GPU 之间直接进行点对点的通信,无需通过主机内存或 CPU 进行数据传输。
- 内存共享:NVLink 还支持 GPU 之间的内存共享,使得多个 GPU 可以直接访问彼此的内存空间。
- 弹性连接:NVLink 支持多种连接配置,包括 2、4、6 或 8 个通道,可以根据需要进行灵活的配置和扩展。这使得 NVLink 适用于不同规模和需求的系统配置。
NVSwitch
NVLink 技术无法使单服务器中 8 个 GPU 达到全连接,为解决该问题,NVIDIA 在 2018 年发布了 NVSwitch,实现了 NVLink 的全连接。NVIDIA NVSwitch 是首款节点交换架构,可支持单个服务器节点中 16 个全互联的 GPU,并可使全部 8 个 GPU 对分别达到 300GB/s 的速度同时进行通信。
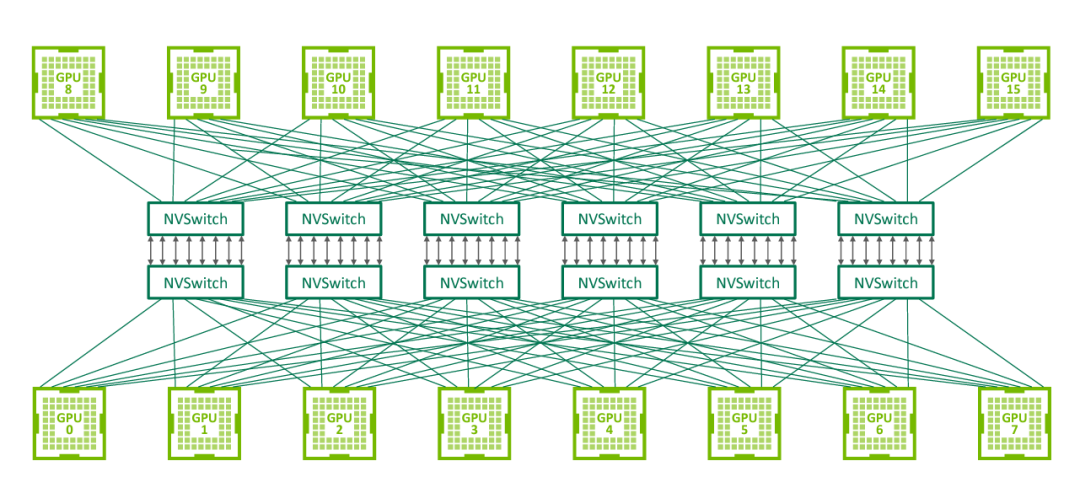
△ NVSwitch 全连接拓扑
多机多卡GPU通信
RDMA
AI 计算对算力需求巨大,多机多卡的计算是一个常态,多机间的通信是影响分布式训练的一个重要指标。在传统的 TCP/IP 网络通信中,数据发送方需要将数据进行多次内存拷贝,并经过一系列的网络协议的数据包处理工作;数据接收方在应用程序中处理数据前,也需要经过多次内存拷贝和一系列的网络协议的数据包处理工作。经过这一系列的内存拷贝、数据包处理以及网络传输延时等,服务器间的通信时延往往在毫秒级别,不能够满足多机多卡场景对于网络通信的需求。
RDMA(Remote Direct Memory Access)是一种绕过远程主机而访问其内存中数据的技术,解决网络传输中数据处理延迟而产生的一种远端内存直接访问技术。
目前 RDMA 有三种不同的技术实现方式:
- InfiniBand(IB):IB 是一种高性能互连技术,它提供了原生的 RDMA 支持。IB 网络使用专用的 IB 适配器和交换机,通过 RDMA 操作实现节点之间的高速直接内存访问和数据传输。
- RoCE(RDMA over Converged Ethernet):RoCE是在以太网上实现 RDMA 的技术。它使用标准的以太网作为底层传输介质,并通过使用 RoCE 适配器和适当的协议栈来实现 RDMA 功能。
- iWARP:iWARP 是基于 TCP/IP 协议栈的 RDMA 实现。它使用普通的以太网适配器和标准的网络交换机,并通过在 TCP/IP 协议栈中实现 RDMA 功能来提供高性能的远程内存访问和数据传输。
GPUDirect RDMA
GPUDirect RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介。
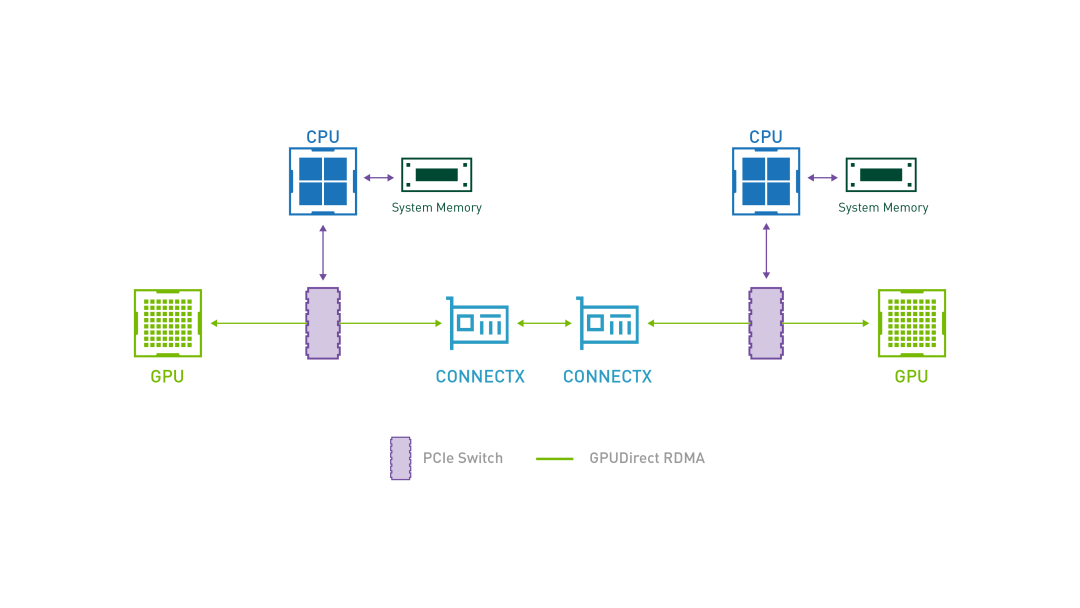
GPUDirect RDMA 通过绕过主机内存和 CPU,直接在 GPU 和 RDMA 网络设备之间进行数据传输,显著降低传输延迟,加快数据交换速度,并可以减轻 CPU 负载,释放 CPU 的计算能力。另外,GPUDirect RDMA 技术允许 GPU 直接访问 RDMA 网络设备中的数据,避免了数据在主机内存中的复制,提高了数据传输的带宽利用率
IPOIB
IPOIB(IP over InfiniBand)是一种在 InfiniBand 网络上运行 IP 协议的技术。它将标准的 IP 协议栈与 IB 互连技术相结合,使得在 IB 网络上的节点能够使用 IP 协议进行通信和数据传输。
IPOIB 提供了基于 RDMA 之上的 IP 网络模拟层,允许应用无修改的运行在 IB 网络上。但是,IPoIB 仍然经过内核层(IP Stack),会产生大量系统调用,并且涉及 CPU 中断,因此 IPoIB 性能比 RDMA 通信方式性能要低,大多数应用都会采用 RDMA 方式获取高带宽低延时的收益,少数的关键应用会采用 IPoIB 方式通信。
在大规模计算中,单机多卡场景下使用 GPUDiect、NVLink 技术,分布式场景下使用 GPUDirect RDMA 技术,可以大大缩短通信时间,提升整体性能。
如果你对 GPU 相关技术感兴趣,你可以用它尝试搭建 AI 绘画平台或者做一些推理的工作。AI 绘画搭建的教程我先放在这里啦:《从 0 到 1,带你玩转 AI 绘画》
聊透 GPU 通信技术——GPU Direct、NVLink、RDMA 审核中的更多相关文章
- GPU keylogger && GPU Based rootkit(Jellyfish rootkit)
catalog . OpenCL . Linux DMA(Direct Memory Access) . GPU rootkit PoC by Team Jellyfish . GPU keylogg ...
- [Attila GPU] ATTILA GPU Streamer Unit (D3D Input Assambler) 结构分析
http://www.opengpu.org/forum.php?mod=viewthread&tid=40&highlight=Attila 查看: 7488|回复: 26 [ ...
- (原)tensorflow中使用指定的GPU及GPU显存
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/6591923.html 参考网址: http://stackoverflow.com/questions ...
- 『TensorFlow』分布式训练_其二_单机多GPU并行&GPU模式设定
建议比对『MXNet』第七弹_多GPU并行程序设计 一.tensorflow GPU设置 GPU指定占用 gpu_options = tf.GPUOptions(per_process_gpu_mem ...
- GPUtil是一个Python模块,使用nvidia-smi从NVIDA GPU获取GPU状态
GPUtil是一个Python模块,使用nvidia-smi从NVIDA GPU获取GPU状态 一个Python模块,用于在Python中使用nvidia-smi以编程方式从NVIDA GPU获取GP ...
- Netty 如何高效接收网络数据?一文聊透 ByteBuffer 动态自适应扩缩容机制
本系列Netty源码解析文章基于 4.1.56.Final版本,公众号:bin的技术小屋 前文回顾 在前边的系列文章中,我们从内核如何收发网络数据开始以一个C10K的问题作为主线详细从内核角度阐述了网 ...
- 一文聊透 Netty IO 事件的编排利器 pipeline | 详解所有 IO 事件的触发时机以及传播路径
欢迎关注公众号:bin的技术小屋,本文图片加载不出来的话可查看公众号原文 本系列Netty源码解析文章基于 4.1.56.Final版本 1. 前文回顾 在前边的系列文章中,笔者为大家详细剖析了 Re ...
- Android studio GPU Monitor :GPU Profiling needs to be enabled in the device's developer options
Android studio GPU Monitor 在真机上不能使用,提示:GPU Profiling needs to be enabled in the device's developer o ...
- tensorflow中使用指定的GPU及GPU显存 CUDA_VISIBLE_DEVICES
参考: https://blog.csdn.net/jyli2_11/article/details/73331126 https://blog.csdn.net/cfarmerreally/arti ...
- Unity Profiler GPU Usage(GPU使用情况)
一般情况下性能瓶颈都在CPU上,这儿也列举下几个常见的GPU耗时函数吧. 1 Render.Mesh 绘制网格面(没批处理的面) 2 Batch.DrawStatic 静态批处理 3 Batch.Dr ...
随机推荐
- 计蒜客蓝桥杯省赛模拟G
题目 一天蒜头君得到 n 个字符串 si,每个字符串的长度都不超过 1010. 蒜头君在想,在这 n 个字符串中,以 si 为后缀的字符串有多少个呢? 输入格式 第一行输入一个整数 n. 接下来 n ...
- AcWing 3729. 改变数组元素
给定一个空数组 V 和一个整数数组 a1,a2,-,an. 现在要对数组 V进行 n次操作. 第 i次操作的具体流程如下: 从数组 V尾部插入整数 0. 2.将位于数组 V末尾的 ai 个元素都 ...
- 安装Visio 2013与原本的office冲突的最终解决方案
一. 下载office visio 2013 这个直接去网上下载一个安装包解压即可 或者直接云盘下载 https://pan.baidu.com/s/1jWGFoHAjegBBvyrL1rq4DQ 提 ...
- 如何让ChatGPT生成Midjourney提示词
导读:最近AI绘画非常的火,今天我们看ChatGPT如何生成Midjourney提示词,让AI教AI做事. 本文字数:900,阅读时长大约:3分钟 正如 Midjourney 的官方网站报道的那样 ...
- 《HTML入门笔记2》
HTML常用标签 分别有:a 标签.img 标签.table 标签.form 标签.input 标签等. a 标签(特别常用) a 标签即超级链接,又叫超链接.一个网站通常由多个页面构成,进入网站时首 ...
- 发布自己的项目到Maven中央仓库中
注册账号和生成GPG生成密钥教程 主要看注册账号和生成GPG密匙部分就行了,出现问题可以先在这两个地方找 gpg加密发布jar包到maven中央仓库详细过程以及踩的坑_佛系猿秦大昊的博客-CSDN博客 ...
- THM武器化
Weaponization thm:https://tryhackme.com/room/weaponization 武器化 了解和探索常见的红队武器化技术.您将学习使用业内常见的方法构建自定义有效载 ...
- C# 版本特性一览
前言 使用 C# 作为开发语言已经 15 个年头了,受惠于 C# 的不断更新,伴随着大量的新特性与大量语法糖,让我更加容易写出简洁.高效的代码.日常中大量特性早已信手拈来,当然从未尝试过的特性更是难以 ...
- Vue3从入门到精通(一)
Vue3简介 Vue3是Vue.js的最新版本,于2020年9月18日正式发布.Vue3相比Vue2有很多改进和优化,包括但不限于: 更快的渲染速度:Vue3通过使用Proxy代理对象和优化虚拟DOM ...
- KeyChrone-K8使用体验
盛名之下,其实难副.我是这应该是我对K8的初上手体验.抛开Mac的使用者,我想其他人应该很难对这款键盘爱得起来.一直以来对手头的Filco的有线比较介意,想换个无线键盘.因为平时调程序比较多,所以F功 ...