解决httpclient设置代理ip之后请求无响应的问题
httpclient这个工具类对于大家来说应该都不陌生吧,最近在使用过程中出现了碰到一个棘手的问题,当请求的接口地址由http变成https之后,程序执行到
httpClient.execute(httpPost);的时候经常会卡死(程序无响应),这个问题的根本原因是第三方接口一直没有返回数据
程序需要收到反馈才能进行下一步操作,这也直接导致程序一直处于卡死状态。
百度了很多资料,基本都是说设置下超时时间就可以
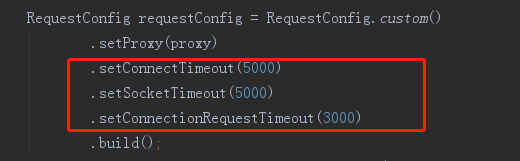
但是问题还是没有得到解决,,,,,
最后本人想到一个解决办法,将调度方法单独放在线程中去执行,

调用 interrupt()方法,将线程处于中断状态
调用interrupted(),清除当前线程的中断位
上述办法本人亲测,可以完美解决httpclient卡死的问题。
结论:interrupt方法是用于中断线程的,调用该方法的线程的状态将被置为"中断"状态。注意:线程中断仅仅是设置线程的中断状态位,不会停止线程。所以当一个线程处于中断状态时,如果再由wait、sleep以及jion三个方法引起的阻塞,那么JVM会将线程的中断标志重新设置为false,并抛出一个InterruptedException异常,然后开发人员可以中断状态位“的本质作用-----就是程序员根据try-catch功能块捕捉jvm抛出的InterruptedException异常来做各种处理,比如如何退出线程。总之interrupt的作用就是需要用户自己去监视线程的状态位并做处理。”
以下供大家参考:
Thread.currentThread().interrupt(); 这个用于清除中断状态,这样下次调用Thread.interrupted()方法时就会一直返回为true,因为中断标志已经被恢复了。 而调用isInterrupted()只是简单的查询中断状态,不会对状态进行修改。 interrupt()是用来设置中断状态的。返回true说明中断状态被设置了而不是被清除了。我们调用sleep、wait等此类可中断(throw InterruptedException)方法时,一旦方法抛出InterruptedException,当前调用该方法的线程的中断状态就会被jvm自动清除了,就是说我们调用该线程的isInterrupted 方法时是返回false。如果你想保持中断状态,可以再次调用interrupt方法设置中断状态。这样做的原因是,java的中断并不是真正的中断线程,而只设置标志位(中断位)来通知用户。如果你捕获到中断异常,说明当前线程已经被中断,不需要继续保持中断位。 interrupted是静态方法,返回的是当前线程的中断状态。例如,如果当前线程被中断(没有抛出中断异常,否则中断状态就会被清除),你调用interrupted方法,第一次会返回true。然后,当前线程的中断状态被方法内部清除了。第二次调用时就会返回false。如果你刚开始一直调用isInterrupted,则会一直返回true,除非中间线程的中断状态被其他操作清除了。
最后跟大家提一下,当线程中的代码执行结束之后,该线程就会关闭。
解决httpclient设置代理ip之后请求无响应的问题的更多相关文章
- 通过httpClient设置代理Ip
背景: 我们有个车管系统,需要定期的去查询车辆的违章,之前一直是调第三方接口去查,后面发现数据不准确(和深圳交警查的对不上),问题比较多.于是想干脆直接从深圳交警上查,那不就不会出问题了吗,但是问题又 ...
- HttpClient使用代理IP
在爬取网页的时候,有的网站会有反爬虫措施,导致服务器请求拒接,可以使用代理IP来访问,解决请求拒绝的问题 代理IP分 透明代理.匿名代理.混淆代理.高匿代理 1.透明代理(Transparent Pr ...
- (四)HttpClient 使用代理 IP
第一节: HttpClient 使用代理 IP 在爬取网页的时候,有的目标站点有反爬虫机制,对于频繁访问站点以及规则性访问站点的行为,会采集屏蔽IP措施. 这时候,代理IP就派上用场了. 关于代理IP ...
- scrapy框架设置代理ip,headers头和cookies
[设置代理ip] 根据最新的scrapy官方文档,scrapy爬虫框架的代理配置有以下两种方法: 一.使用中间件DownloaderMiddleware进行配置使用Scrapy默认方法scrapy s ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(一)——设置代理IP
自己写了一个爬虫爬取豆瓣小说,后来为了应对请求不到数据,增加了请求的头部信息headers,为了应对豆瓣服务器的反爬虫机制:防止请求频率过快而造成“403 forbidden”,乃至封禁本机ip的情况 ...
- 爬虫-设置代理ip
1.为什么要设置代理ip 在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术导致爬取失败.高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网 ...
- Python爬虫常用小技巧之设置代理IP
设置代理IP的原因 我们在使用Python爬虫爬取一个网站时,通常会频繁访问该网站.假如一个网站它会检测某一段时间某个IP的访问次数,如果访问次数过多,它会禁止你的访问.所以你可以设置一些代理服务器来 ...
- python3 selenium模块Chrome设置代理ip的实现
python3 selenium模块Chrome设置代理ip的实现 selenium模块Chrome设置代理ip的实现代码: from selenium import webdriver chrome ...
- Android ListView的item背景色设置以及item点击无响应等相关问题
Android ListView的item背景色设置以及item点击无响应等相关问题 在Android开发中,listview控件是非常常用的控件,在大多数情况下,大家都会改掉listview的ite ...
随机推荐
- CODE FESTIVAL 2017 qual A B fLIP(补题)
平时没见过这样的题目,看到后很懵逼.没想到. 思路:按下按钮的顺序并不影响结果,一个按钮要么按一次,要么不按,按多了也没用,比如:按3次和按1次没啥区别. 假设这是个M * N的矩阵,我们已经按下了k ...
- java一维数组的声明与初始化
一维数组:可以理解为一列多行.类型相同的数据,其中每个数据被称为数组元素: 一维数组的声明方式: type varName[]; 或 type[] varName;(推荐) Eg:int age[]; ...
- java 文件拷贝
需求:源和目标! 那么我们需要源文件和目标文件! 构建管道的时候就需要两个:输出流和输入流管道! Eg: package july7file; //java7开始的自动关闭资源 import java ...
- VMware虚拟机安装Windows2003操作教程
1.下载好以下三个文件: 2.选择VMware安装包,跟随指令安装好后,打开: 3.选择"创建新的虚拟机"后,选择"安装光盘映像文件(iso)",点击浏览载入. ...
- H3C 聚合链路负载分担原理
- 应用八:Vue之在nginx下的部署实践
最近有时间研究了下前端项目如何在nginx服务器下进行部署,折腾了两天总算有所收获,汗~~ 所以就想着写篇文章来总结一下,主要包括以下三个方面: 1.打包好的vue项目如何进行部署. 2.如何反向代理 ...
- 【37.48%】【hdu 2587】How far away ?(3篇文章,3种做法,LCA之树上倍增)
Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submission(s) ...
- 如何用python“优雅的”调用有道翻译?
前言 其实在以前就盯上有道翻译了的,但是由于时间问题一直没有研究(我的骚操作还在后面,记得关注),本文主要讲解如何用python调用有道翻译,讲解这个爬虫与有道翻译的js“斗争”的过程! 当然,本文仅 ...
- poj2826 An Easy Problem?!(计算几何)
传送门 •题意 两根木块组成一个槽,给定两个木块的两个端点 雨水竖直下落,问槽里能装多少雨水, •思路 找不能收集到雨水的情况 我们令线段较高的点为s点,较低的点为e点 ①两条木块没有交点 ②平行或重 ...
- How to output the target message in dotnet build command line
How can I output my target message when I using dotnet build in command line. I use command line to ...