python爬虫——selenium+chrome使用代理
先看下本文中的知识点:
- python selenium库安装
- chrome webdirver的下载安装
- selenium+chrome使用代理
- 进阶学习
搭建开发环境:
- selenium库
- chrome webdirver
- 谷歌浏览器 >=7.9
PS:安装了的同学可以跳过了接着下一步,没安装的同学跟着我的步骤走一遍
安装selenium库
pip install selenium
安装chrome webdirver
这里要注意要配置系统环境,把chrome webdirver解压后放到python路径的Scripts目录下,跟pip在一个目录下。
这里可以教大家一个查看python安装路径的命令
# windows系统,打开cmd
where python
# linux系统
whereis python
谷歌浏览器
注意谷歌浏览器的版本要>=7.9,因为之前下载的chrome webdirver是7.9版本的。浏览器就自己安装吧。
代码样例
好的,现在咋们的环境都配置好了,写几行代码试下,以请求百度为例
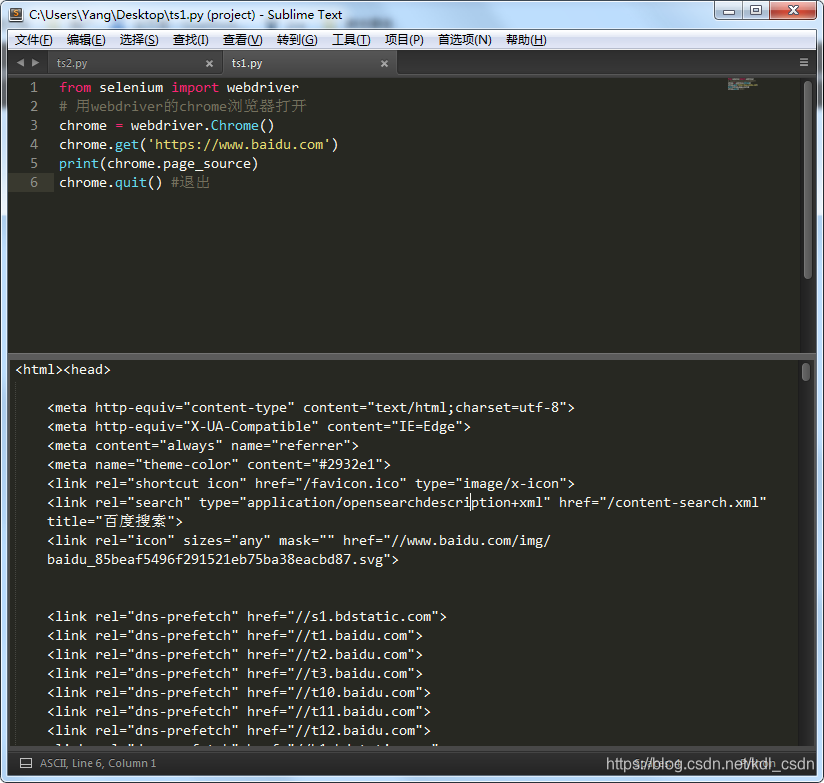
from selenium import webdriver
# 用webdriver的chrome浏览器打开
chrome = webdriver.Chrome()
chrome.get('https://www.baidu.com')
print(chrome.page_source)
chrome.quit() #退出
运行下,先会打开chrome浏览器,然后访问百度,在打印page信息,最后关闭浏览器
使用代理
使用代理IP去访问就得加一个参数了,代码如下
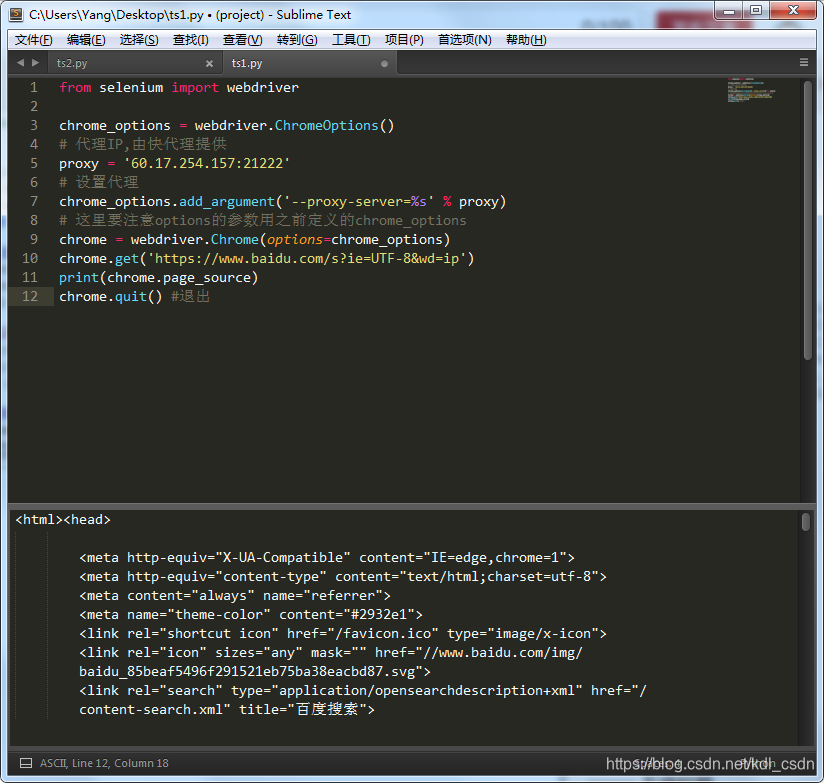
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
# 代理IP,由快代理提供
proxy = '60.17.254.157:21222'
# 设置代理
chrome_options.add_argument('--proxy-server=%s' % proxy)
# 注意options的参数用之前定义的chrome_options
chrome = webdriver.Chrome(options=chrome_options)
# 百度查IP
chrome.get('https://www.baidu.com/s?ie=UTF-8&wd=ip')
print(chrome.page_source)
chrome.quit() #退出
运行下,结果如图
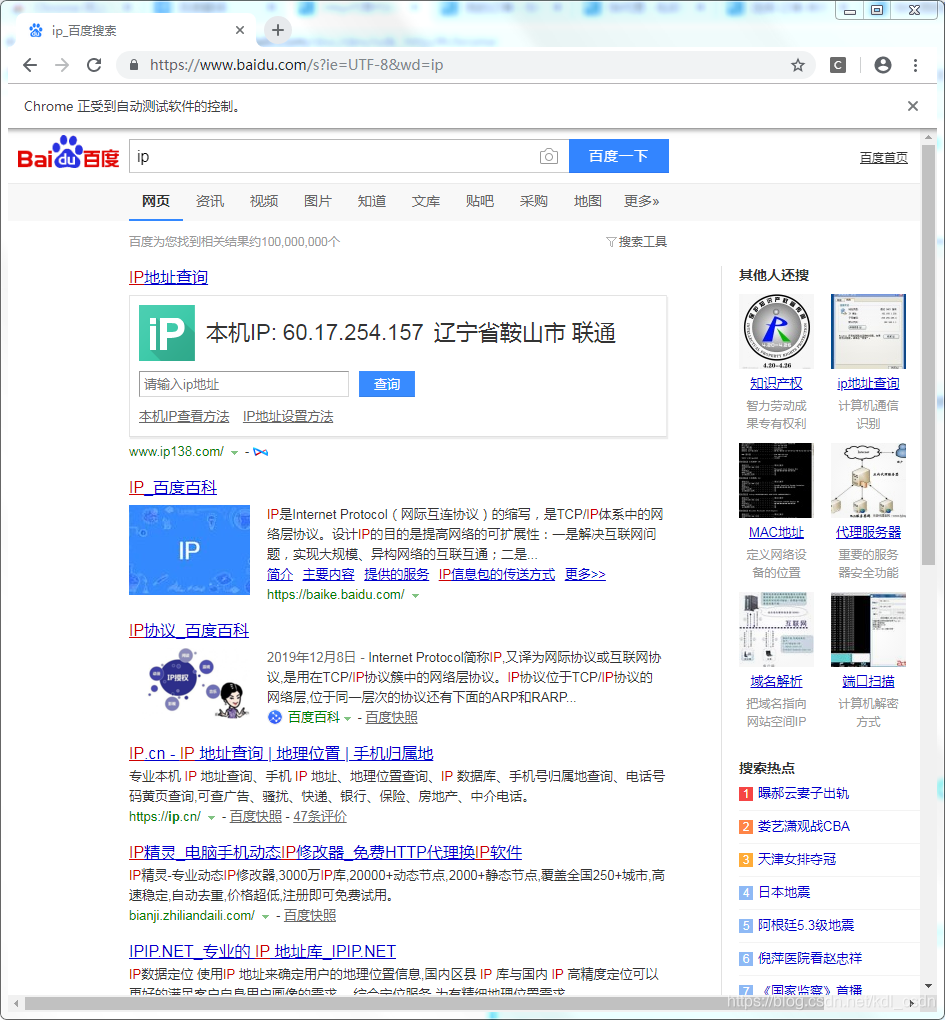
扩展
不想用谷歌浏览器啊,想用火狐怎么办。没问题啊,webdriver也支持火狐。看下webdriver的帮助文档
from selenium import webdriver
help(webdriver)
看下图,不止支持火狐firefox,谷歌chrome,ie,opera等等都支持的。
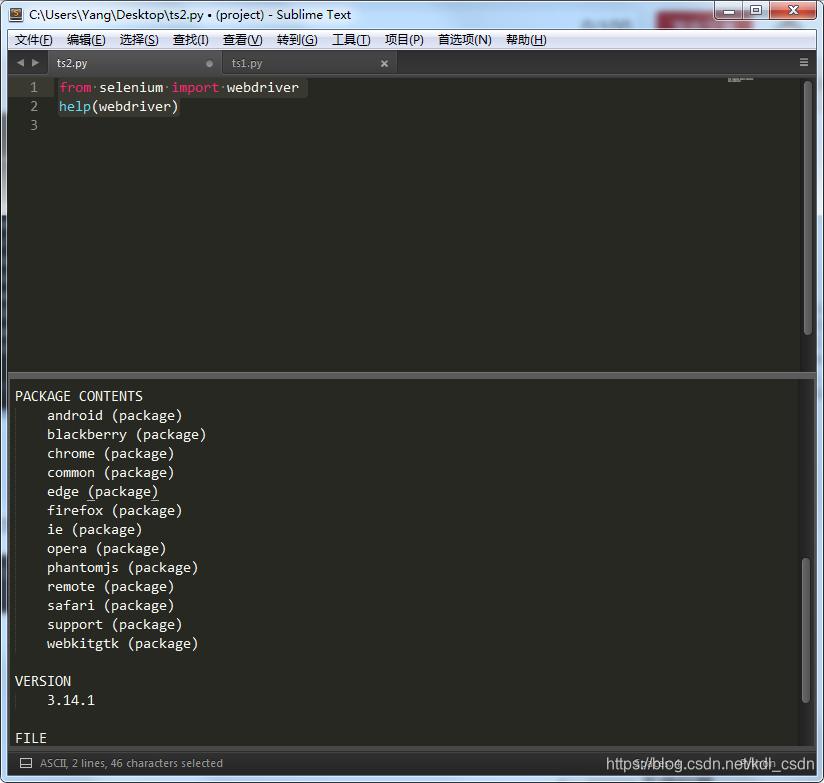
进阶学习
python爬虫——selenium+chrome使用代理的更多相关文章
- python爬虫——selenium+firefox使用代理
本文中的知识点: python selenium库安装 firefox geckodriver的下载与安装 selenium+firefox使用代理 进阶学习 搭建开发环境: selenium库 fi ...
- [Python爬虫] Selenium实现自动登录163邮箱和Locating Elements介绍
前三篇文章介绍了安装过程和通过Selenium实现访问Firefox浏览器并自动搜索"Eastmount"关键字及截图的功能.而这篇文章主要简单介绍如何实现自动登录163邮箱,同时 ...
- [Python爬虫] Selenium+Phantomjs动态获取CSDN下载资源信息和评论
前面几篇文章介绍了Selenium.PhantomJS的基础知识及安装过程,这篇文章是一篇应用.通过Selenium调用Phantomjs获取CSDN下载资源的信息,最重要的是动态获取资源的评论,它是 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- python爬虫---selenium库的用法
python爬虫---selenium库的用法 selenium是一个自动化测试工具,支持Firefox,Chrome等众多浏览器 在爬虫中的应用主要是用来解决JS渲染的问题. 1.使用前需要安装这个 ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍
这篇文章主要Selenium+Python自动测试或爬虫中的常见定位方法.鼠标操作.键盘操作介绍,希望该篇基础性文章对你有所帮助,如果有错误或不足之处,请海涵~同时CSDN总是屏蔽这篇文章,再加上最近 ...
- Python爬虫-selenium的使用(2)
使用selenium打开chrome浏览器百度进行搜索 12345678910111213141516171819202122232425 from selenium import webdriver ...
- [Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
前面我讲述过如何通过BeautifulSoup获取维基百科的消息盒,同样可以通过Spider获取网站内容,最近学习了Selenium+Phantomjs后,准备利用它们获取百度百科的旅游景点消息盒(I ...
- [python爬虫] Selenium常见元素定位方法和操作的学习介绍(转载)
转载地址:[python爬虫] Selenium常见元素定位方法和操作的学习介绍 一. 定位元素方法 官网地址:http://selenium-python.readthedocs.org/locat ...
随机推荐
- dotnet core 使用 CoreRT 将程序编译为 Native 程序
现在微软有一个开源项目 CoreRT 能通过将托管的 .NET Core 编译为单个无依赖的 Native 程序 这个项目现在还没发布,但是能尝试使用,可以带来很多的性能提升 使用 CoreRT 发布 ...
- ES6,ES7重点介绍
1. 字符串模板 <!--旧版拼接字符串--> var str = '我是时间:'+new Date(); <!--新版拼接字符串--> let str = `我是时间${ne ...
- ZR7.17
7.17 F 认真读题吧 A 算法一: \(c = ab,x = a + b + c\) 所以 \(x = a + b + ab\) \(=(b + 1)a + b\) 所以我们枚举\(b\) \(O ...
- 2019-1-25-win10-uwp-禁用-ScrollViewer-交互
title author date CreateTime categories win10 uwp 禁用 ScrollViewer 交互 lindexi 2019-01-25 21:45:37 +08 ...
- codeforces 1183H 动态规划
codeforces 1183H 动态规划 传送门:https://codeforces.com/contest/1183/problem/H 题意: 给你一串长度为n的字符串,你需要寻找出他的最长的 ...
- JAVA8学习——深入浅出Lambda表达式(学习过程)
JAVA8学习--深入浅出Lambda表达式(学习过程) lambda表达式: 我们为什么要用lambda表达式 在JAVA中,我们无法将函数作为参数传递给一个方法,也无法声明返回一个函数的方法. 在 ...
- SQLServer数据库之SqlServer查看表、存储过程、耗时查询、当前进程、开销较大的语句
--查看数据库中表的语句 SELECT s2.dbid , DB_NAME(s2.dbid) AS [数据库名] , --s1.sql_handle , ( , ( ( THEN ( LEN(CONV ...
- python入门之字符串的魔法
1.test="alex" v=test.capitalize() print(v) //输出结果首字母大写 2.test1="alex&qu ...
- 【重学Node.js 第1&2篇】本地搭建Node环境并起RESTful Api服务
本地搭建Node环境并起RESTful Api服务 课程介绍看这里:https://www.cnblogs.com/zhangran/p/11963616.html 项目github地址:https: ...
- zabbix安装完成后查看编译参数
最近学习zabbix分布式监控系统,突然想如何查看自己编译时的参数,最终找到自己想要的结果. 1.首先进入zabbix源码目录 2.用ls -l命令查看是否有一个叫config.log文件 3.这个文 ...