python3正则表达式指南
1.正则表达式基础
1.1 简单介绍
正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
下图展示了使用正则表达式进行匹配的流程:
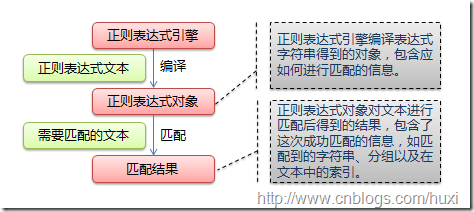
正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,看下图中的示例以及自己多使用几次就能明白。
下图列出了Python支持的正则表达式元字符和语法:

1.2. 数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。
1.3. 反斜杠的困扰
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
1.4. 匹配模式
正则表达式提供了一些可用的匹配模式,比如忽略大小写、多行匹配等,这部分内容将在Pattern类的工厂方法re.compile(pattern[, flags])中一起介绍。
2. re模块
2.1编译正则表达式
re 模块提供了 re.compile() 函数将一个字符串编译成 pattern object,用于匹配或搜索。函数原型如下:
re.compile(strPattern[, flag]):
这个方法是Pattern类的工厂方法,用于将字符串形式的正则表达式编译为Pattern对象。 第二个参数flag是匹配模式,取值可以使用按位或运算符'|'表示同时生效,比如re.I | re.M。另外,你也可以在regex字符串中指定模式,比如re.compile('pattern', re.I | re.M)与re.compile('(?im)pattern')是等价的。
可选值有:
re.IGNORECASE:忽略大小写,同 re.I。
re.MULTILINE:多行模式,改变^和$的行为,同 re.M。
re.DOTALL:点任意匹配模式,让'.'可以匹配包括'\n'在内的任意字符,同 re.S。
re.LOCALE:使预定字符类 \w \W \b \B \s \S 取决于当前区域设定, 同 re.L。
re.ASCII:使 \w \W \b \B \s \S 只匹配 ASCII 字符,而不是 Unicode 字符,同 re.A。
re.VERBOSE:详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。主要是为了让正则表达式更易读,同re.X。例如,以下两个正则表达式是等价的:
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""", re.X)
b = re.compile(r"\d+\.\d*")
re提供了众多模块方法用于完成正则表达式的功能。这些方法可以使用Pattern实例的相应方法替代,唯一的好处是少写一行re.compile()代码,但同时也无法复用编译后的Pattern对象。
2.2 match
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
string: 匹配时使用的文本。
re: 匹配时使用的Pattern对象。
pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
方法:
group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
span([group]):
返回(start(group), end(group))。
expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。\id与\g<id>是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符'0',只能使用\g<1>0。
示例如下:
import re
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!') print("m.string:", m.string)
print("m.re:", m.re)
print("m.pos:", m.pos)
print("m.endpos:", m.endpos)
print("m.lastindex:", m.lastindex)
print("m.lastgroup:", m.lastgroup) print("m.group(1,2):", m.group(1, 2))
print("m.groups():", m.groups())
print("m.groupdict():", m.groupdict())
print("m.start(2):", m.start(2))
print("m.end(2):", m.end(2))
print("m.span(2):", m.span(2))
print(r"m.expand(r'\2 \1\3'):", m.expand(r'\2 \1\3')) ### output ###
# m.string: hello world!
# m.re: re.compile('(\\w+) (\\w+)(?P<sign>.*)')
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!'}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
2.3. Pattern
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。
Pattern不能直接实例化,必须使用re.compile()进行构造。
Pattern提供了几个可读属性用于获取表达式的相关信息:
- pattern: 编译时用的表达式字符串。
- flags: 编译时用的匹配模式。数字形式。
- groups: 表达式中分组的数量。
- groupindex: 以表达式中有别名的组的别名为键、以该组对应的编号为值的字典,没有别名的组不包含在内
import re
p = re.compile(r'(\w+) (\w+)(?P<sign>.*)', re.DOTALL) print("p.pattern:", p.pattern)
print("p.flags:", p.flags)
print("p.groups:", p.groups)
print("p.groupindex:", p.groupindex) ### output ###
# p.pattern: (\w+) (\w+)(?P<sign>.*)
# p.flags: 48
# p.groups: 3
# p.groupindex: {'sign': 3}
实例方法[ | re模块方法]:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags]):
这个方法将从string的pos下标处起尝试匹配pattern;如果pattern结束时仍可匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。
pos和endpos的默认值分别为0和len(string);re.match()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
注意:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'。
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags]):
这个方法用于查找字符串中可以匹配成功的子串。从string的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。
pos和endpos的默认值分别为0和len(string));re.search()无法指定这两个参数,参数flags用于编译pattern时指定匹配模式。
# encoding: UTF-8
import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'world') # 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = pattern.search('hello world!') if match:
# 使用Match获得分组信息
print(match.group()) ### 输出 ###
# world
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit]):
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
import re p = re.compile(r'\d+')
print(p.split('one1two2three3four4')) ### output ###
# ['one', 'two', 'three', 'four', '']
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags]):
搜索string,以列表形式返回全部能匹配的子串。
import re p = re.compile(r'\d+')
print(p.findall('one1two2three3four4')) ### output ###
# ['1', '2', '3', '4']
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags]):
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
import re p = re.compile(r'\d+')
for m in p.finditer('one1two2three3four4'):
print(m.group()) ### output ###
# 1 2 3 4
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count]):
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g<id>、\g<name>引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
import re p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!' print(p.sub(r'\2 \1', s)) def func(m):
return m.group(1).title() + ' ' + m.group(2).title() print(p.sub(func, s)) ### output ###
# say i, world hello!
# I Say, Hello World!
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count]):
返回 (sub(repl, string[, count]), 替换次数)。
import re p = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!' print(p.subn(r'\2 \1', s)) def func(m):
return m.group(1).title() + ' ' + m.group(2).title() print(p.subn(func, s)) ### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2)
python3正则表达式指南的更多相关文章
- Python正则表达式指南(转)
目录 Python正则表达式指南(转) 0.防走丢 1. 正则表达式基础 1.1. 简单介绍 1.2. 数量词的贪婪模式与非贪婪模式 1.3. 反斜杠的困扰 1.4. 匹配模式 2. re模块 2.1 ...
- 详解 Python3 正则表达式(五)
上一篇:详解 Python3 正则表达式(四) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些注明和修改 ^_^ 非捕获组和命名 ...
- 详解 Python3 正则表达式(四)
上一篇:详解 Python3 正则表达式(三) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些注明和修改 ^_^ 更多强大的功能 ...
- 详解 Python3 正则表达式(三)
上一篇:详解 Python3 正则表达式(二) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些批注和修改 ^_^ 模块级别的函数 ...
- [Python] re正则表达式指南以及常用操作
一.语法 1. 使用正则表达式进行匹配的流程 2. Python支持的正则表达式元字符和语法 参考: AstralWind的Python正则表达式指南 官方文档:7.2. re — Regular e ...
- 详解 Python3 正则表达式(二)
上一篇:详解 Python3 正则表达式(一) 本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些批注和修改 ^_^ 使用正则表达式 ...
- 详解 Python3 正则表达式(一)
本文翻译自:https://docs.python.org/3.4/howto/regex.html 博主对此做了一些批注和修改 ^_^ 正则表达式介绍 正则表达式(Regular expressio ...
- python025 Python3 正则表达式
Python3 正则表达式 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. ...
- Python3程序设计指南:01 过程型程序设计快速入门
大家好,从本文开始将逐渐更新Python教程指南系列,为什么叫指南呢?因为本系列是参考<Python3程序设计指南>,也是作者的学习笔记,希望与读者共同学习. .py文件中的每个估计都是顺 ...
随机推荐
- react组件中的方法?
SetState 设置状态 ReplaceState 替换状态 setProps设置属性 replacerProps替换属性 forceUpdate 强制更新 findDOMNode获取DOM节点 i ...
- jetson nano VNC
寻找比较好的远程桌面方式,最新系统里有写. ======================================================================= README ...
- zmq的send
int zmq_send (void *socket, zmq_msg_t *msg, int flags); 2.2.1 nt zmq_send (void *socket, void * ...
- windows 计算器
calc sin 弧度与角度
- HashMap 介绍
基本介绍 1. 用于存储Key-Value键值对的集合(每一个键值对也叫做一个Entry)(无顺序). 2. 根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值. 3. 键key为n ...
- django入门 -- 简单流程
django入门 -- 简单流程 简介 通过简单示例,使用django完成基本流程的开发,学习django的主要的知识点,在后续课程中会逐个知识点进行深入讲解 以“图书-英雄”管理为示例 主要知识点介 ...
- thinkphp 查询缓存
对于及时性要求不高的数据查询,我们可以使用查询缓存功能来提高性能,而且无需自己使用缓存方法进行缓存和获取. 大理石平台价格 查询缓存功能支持所有的数据库,并且支持所有的缓存方式和有效期. 在使用查询缓 ...
- NX二次开发-UFUN将建模绝对空间中的点映射到工程图坐标UF_VIEW_map_model_to_drawing
#include <uf.h> #include <uf_ui.h> #include <uf_draw.h> #include <uf_view.h> ...
- java中get请求的中文乱码问题
表单采用Get方式提交,解决乱码的方法为: 方式一:手动解码 param = new String(param.getBytes("iso8859-1"), ...
- tomcat部署项目报错NoSuchMethodException#addServlet,addFilter
java.lang.NoSuchMethodException: org.apache.catalina.deploy.WebXml addServlet java.lang.NoSuchMethod ...