一秒可生成500万ID的分布式自增ID算法—雪花算法 (Snowflake,Delphi 版)
概述
分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的。
有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。
而TWitter的snowflake解决了这种需求,最初TWitter把存储系统从MySQL迁移到Cassandra,因为Cassandra没有顺序ID生成机制,所以开发了这样一套全局唯一ID生成服务。
结构
snowflake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
第一位为未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年),然后是5位datacenterId和5位workerId(10位的长度最多支持部署1024个节点) ,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生4096个ID序号)一共加起来刚好64位,为一个Long型。(转换成字符串后长度最多19)。
Snowflake生成的ID整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和workerId作区分),并且效率较高。经测试snowflake每秒能够产生409.6万个ID。
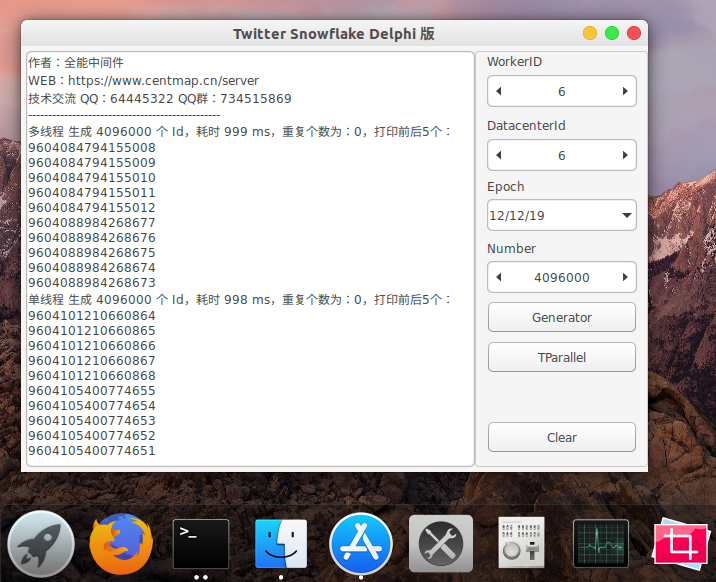
在 Ubuntu 18.04 下运行的截图:
源码
{ *
* Twitter_Snowflake https://github.com/twitter-archive/snowflake
* SnowFlake的结构如下(每部分用-分开):
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
* 加起来刚好64位,为一个Long型。
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生409.6万ID左右。
*
* 本算法参考官方 Twitter Snowflake 修改而来,同时借鉴了网上Java语言的版本。
* 作者:全能中间件 64445322 https://www.centmap.cn/server
* 使用方法:var OrderId := IdGenerator.NextId(),IdGenerator 不用创建也不用释放,而且该方法是线程安全的。
* }
// 参考美团点评分布式ID生成系统
// https://tech.meituan.com/2017/04/21/mt-leaf.html
// https://github.com/Meituan-Dianping/Leaf/blob/master/leaf-core/src/main/java/com/sankuai/inf/leaf/snowflake/SnowflakeIDGenImpl.java
unit Snowflake;
interface
uses
System.SysUtils, System.SyncObjs;
type
TSnowflakeIdWorker = class(TObject)
private const
// 最大可用69年
MaxYears = ;
// 机器id所占的位数
WorkerIdBits = ;
// 数据标识id所占的位数
DatacenterIdBits = ;
// 序列在id中占的位数
SequenceBits = ;
// 机器ID向左移12位
WorkerIdShift = SequenceBits;
// 数据标识id向左移17位(12+5)
DatacenterIdShift = SequenceBits + WorkerIdBits;
// 时间截向左移22位(5+5+12)
TimestampLeftShift = SequenceBits + WorkerIdBits + DatacenterIdBits;
{$WARNINGS OFF}
// 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095)
SequenceMask = - xor (- shl SequenceBits);
// 支持的最大机器id
MaxWorkerId = - xor (- shl WorkerIdBits);
// 支持的最大数据标识id,结果是 31
MaxDatacenterId = - xor (- shl DatacenterIdBits);
{$WARNINGS ON}
private type
TWorkerID = .. MaxWorkerId;
TDatacenterId = .. MaxDatacenterId;
strict private
FWorkerID: TWorkerID;
FDatacenterId: TDatacenterId;
FEpoch: Int64;
FSequence: Int64;
FLastTimeStamp: Int64;
FStartTimeStamp: Int64;
FUnixTimestamp: Int64;
FIsHighResolution: Boolean;
/// <summary>
/// 阻塞到下一个毫秒,直到获得新的时间戳
/// </summary>
/// <param name="ATimestamp ">上次生成ID的时间截</param>
/// <returns>当前时间戳 </returns>
function WaitUntilNextTime(ATimestamp: Int64): Int64;
/// <summary>
/// 返回以毫秒为单位的当前时间
/// </summary>
/// <remarks>
/// 时间的表达格式为当前计算机时间和1970年1月1号0时0分0秒所差的毫秒数
/// </remarks>
function CurrentMilliseconds: Int64; inline;
function CurrentTimeStamp: Int64; inline;
function ElapsedMilliseconds: Int64; inline;
private
class var FLock: TSpinLock;
class var FInstance: TSnowflakeIdWorker;
class function GetInstance: TSnowflakeIdWorker; static;
class constructor Create;
class destructor Destroy;
protected
function GetEpoch: TDateTime;
procedure SetEpoch(const Value: TDateTime);
public
constructor Create; overload;
/// <summary>
/// 获得下一个ID (该方法是线程安全的)
/// </summary>
function NextId: Int64;inline;
/// <summary>
/// 工作机器ID(0~31)
/// </summary>
property WorkerID: TWorkerID read FWorkerID write FWorkerID;
/// <summary>
/// 数据中心ID(0~31)
/// </summary>
property DatacenterId: TDatacenterId read FDatacenterId write FDatacenterId;
/// <summary>
/// 开始时间
/// </summary>
property Epoch: TDateTime read GetEpoch write SetEpoch;
class property Instance: TSnowflakeIdWorker read GetInstance;
end;
function IdGenerator: TSnowflakeIdWorker;
const
ERROR_CLOCK_MOVED_BACKWARDS = 'Clock moved backwards. Refusing to generate id for %d milliseconds';
ERROR_EPOCH_INVALID = 'Epoch can not be greater than current';
implementation
uses
System.Math, System.TimeSpan
{$IF defined(MSWINDOWS)}
, Winapi.Windows
{$ELSEIF defined(MACOS)}
, Macapi.Mach
{$ELSEIF defined(POSIX)}
, Posix.Time
{$ENDIF}
, System.DateUtils;
function IdGenerator: TSnowflakeIdWorker;
begin
Result := TSnowflakeIdWorker.GetInstance;
end;
{ TSnowflakeIdWorker }
constructor TSnowflakeIdWorker.Create;
{$IF defined(MSWINDOWS)}
var
Frequency: Int64;
{$ENDIF}
begin
inherited;
{$IF defined(MSWINDOWS)}
FIsHighResolution := QueryPerformanceFrequency(Frequency);
{$ELSEIF defined(POSIX)}
FIsHighResolution := True;
{$ENDIF}
FSequence := ;
FWorkerID := ;
FDatacenterId := ;
FLastTimeStamp := -;
FEpoch := DateTimeToUnix(EncodeDate(, , ), True) * MSecsPerSec;
FUnixTimestamp := DateTimeToUnix(Now, True) * MSecsPerSec;
FStartTimeStamp := CurrentTimeStamp;
end;
class destructor TSnowflakeIdWorker.Destroy;
begin
FreeAndNil(FInstance);
end;
class constructor TSnowflakeIdWorker.Create;
begin
FInstance := nil;
FLock := TSpinLock.Create(False);
end;
class function TSnowflakeIdWorker.GetInstance: TSnowflakeIdWorker;
begin
FLock.Enter;
try
if FInstance = nil then
FInstance := TSnowflakeIdWorker.Create;
Result := FInstance;
finally
FLock.Exit;
end;
end;
function TSnowflakeIdWorker.CurrentTimeStamp: Int64;
{$IF defined(POSIX) and not defined(MACOS)}
var
res: timespec;
{$ENDIF}
begin
{$IF defined(MSWINDOWS)}
if FIsHighResolution then
QueryPerformanceCounter(Result)
else
Result := GetTickCount * Int64(TTimeSpan.TicksPerMillisecond);
{$ELSEIF defined(MACOS)}
Result := Int64(AbsoluteToNanoseconds(mach_absolute_time) div );
{$ELSEIF defined(POSIX)}
clock_gettime(CLOCK_MONOTONIC, @res);
Result := (Int64() * res.tv_sec + res.tv_nsec) div ;
{$ENDIF}
end;
function TSnowflakeIdWorker.ElapsedMilliseconds: Int64;
begin
Result := (CurrentTimeStamp - FStartTimeStamp) div TTimeSpan.TicksPerMillisecond;
end;
function TSnowflakeIdWorker.GetEpoch: TDateTime;
begin
Result := UnixToDateTime(FEpoch div MSecsPerSec, True);
end;
function TSnowflakeIdWorker.NextId: Int64;
var
Offset: Integer;
Timestamp: Int64;
begin
FLock.Enter;
try
Timestamp := CurrentMilliseconds();
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (Timestamp < FLastTimeStamp) then
begin
Offset := FLastTimeStamp - Timestamp;
if Offset <= then
begin
// 时间偏差大小小于5ms,则等待两倍时间
System.SysUtils.Sleep(Offset shr );
Timestamp := CurrentMilliseconds();
// 还是小于,抛异常并上报
if Timestamp < FLastTimeStamp then
raise Exception.CreateFmt(ERROR_CLOCK_MOVED_BACKWARDS, [FLastTimeStamp - Timestamp]);
end;
end;
// 如果是同一时间生成的,则进行毫秒内序列
if (FLastTimeStamp = Timestamp) then
begin
FSequence := (FSequence + ) and SequenceMask;
// 毫秒内序列溢出
if (FSequence = ) then
// 阻塞到下一个毫秒,获得新的时间戳
Timestamp := WaitUntilNextTime(FLastTimeStamp);
end
// 时间戳改变,毫秒内序列重置
else
FSequence := ;
// 上次生成ID的时间截
FLastTimeStamp := Timestamp;
// 移位并通过或运算拼到一起组成64位的ID
Result := ((Timestamp - FEpoch) shl TimestampLeftShift)
or (DatacenterId shl DatacenterIdShift)
or (WorkerID shl WorkerIdShift)
or FSequence;
finally
FLock.Exit;
end;
end;
function TSnowflakeIdWorker.WaitUntilNextTime(ATimestamp: Int64): Int64;
var
Timestamp: Int64;
begin
Timestamp := CurrentMilliseconds();
while Timestamp <= ATimestamp do
Timestamp := CurrentMilliseconds();
Result := Timestamp;
end;
procedure TSnowflakeIdWorker.SetEpoch(const Value: TDateTime);
begin
if Value > Now then
raise Exception.Create(ERROR_EPOCH_INVALID);
if YearsBetween(Now, Value) <= MaxYears then
FEpoch := DateTimeToUnix(Value, True) * MSecsPerSec;
end;
function TSnowflakeIdWorker.CurrentMilliseconds: Int64;
begin
Result := FUnixTimestamp + ElapsedMilliseconds;
end;
end.
一秒可生成500万ID的分布式自增ID算法—雪花算法 (Snowflake,Delphi 版)的更多相关文章
- 分布式唯一ID生成算法-雪花算法
在我们的工作中,数据库某些表的字段会用到唯一的,趋势递增的订单编号,我们将介绍两种方法,一种是传统的采用随机数生成的方式,另外一种是采用当前比较流行的“分布式唯一ID生成算法-雪花算法”来实现. 一. ...
- Twitter分布式自增ID算法snowflake原理解析
以JAVA为例 Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个 ...
- Twitter分布式自增ID算法snowflake原理解析(Long类型)
Twitter分布式自增ID算法snowflake,生成的是Long类型的id,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特(0和1). 那么一个Long类型的6 ...
- 详解Twitter开源分布式自增ID算法snowflake(附演算验证过程)
详解Twitter开源分布式自增ID算法snowflake,附演算验证过程 2017年01月22日 14:44:40 url: http://blog.csdn.net/li396864285/art ...
- 分布式自增ID算法-Snowflake详解
1.Snowflake简介 互联网快速发展的今天,分布式应用系统已经见怪不怪,在分布式系统中,我们需要各种各样的ID,既然是ID那么必然是要保证全局唯一,除此之外,不同当业务还需要不同的特性,比如像并 ...
- Spring - jdbcTemplate - 调试代码: PreparedStatementCreator 生成的语句, update 之后没有 自增id, 已解决
1. 概述 解决 jdbcTemplate 下, update 结果不带 自增id 的问题 2. 场景 看书 Spring in Action 5th 3.1.4 listing 3.10 saveT ...
- Twitter的分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
- Twitter的分布式自增ID算法snowflake(雪花算法) - C#版
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的.有些时候我们希望能使用一种简 ...
- 分布式自增ID算法snowflake (Java版)
概述 分布式系统中,有一些需要使用全局唯一ID的场景,这种时候为了防止ID冲突可以使用36位的UUID,但是UUID有一些缺点,首先他相对比较长,另外UUID一般是无序的. 有些时候我们希望能使用一种 ...
随机推荐
- ent 基本使用六 Mixin
ent 的Mixin 可以让我们服用已有的schema Mixin 接口说明 type Mixin interface { Fields() []ent.Field } 一个demo 代码 // -- ...
- Falcor 学习一基本使用
falcor 是netflix 公司为了解决自己api数据查询所开发的查询框架,很不错(尽管netflix 也在用graphql )以下是falcor 的 一个简单使用,基于express 框架,使用 ...
- How to Construct the Input Bet String
The purpose of this section is to describe the format of the string which will submitted to the Pyth ...
- Python 检查代码占用内存 工具和模块
只介绍简单的使用, 更多使用方法请查看官方文档 tracemalloc 官方文档 tracemalloc文档地址 使用 import tracemalloc tracemalloc.start() # ...
- 新blog
www.nancheng58.xyz 欢迎来访 骗访客量 我之前的blog是在csdn上的 https://blog.csdn.net/sinat_34550050 这里算是个在csdn的镜像吧 不过 ...
- 「SDOI2014」旅行(信息学奥赛一本通 1564)(洛谷 3313)
题目描述 S国有N个城市,编号从1到N.城市间用N-1条双向道路连接,满足从一个城市出发可以到达其它所有城市.每个城市信仰不同的宗教,如飞天面条神教.隐形独角兽教.绝地教都是常见的信仰. 为了方便,我 ...
- pytest以函数形式形成测试用例
#coding=utf- from __future__ import print_function #开始执行该文件时,该函数执行 def setup_module(module): print(' ...
- “未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序
一.背景: 开发一个工具的小项目,因为数据少,我就不想安装sqlserver数据库,就用Access数据库. 二.问题: 在客户安装程序的时候,接口访问Access数据库的时候,报错“未在本地计算机上 ...
- 关于python的四舍五入
参考https://blog.csdn.net/qq_39234705/article/details/82817703 四舍五入有很多相关资料,主要用两种方法round()和'%.2f' 两种方法取 ...
- sql server 使用链接服务器远程查询
--PKselect * from sys.key_constraints where object_id = OBJECT_ID('TB')--FKselect * from sys.foreign ...