Spark之开窗函数
一.简介
开窗函数row_number()是按照某个字段分组,然后取另外一个字段排序的前几个值的函数,相当于分组topN。如果SQL语句里面使用了开窗函数,那么这个SQL语句必须使用HiveContext执行。
二.代码实践【使用HiveContext】
package big.data.analyse.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* Created by zhen on 2019/7/6.
*/
object RowNumber {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口,支持Hive
*/
val spark = SparkSession.builder().appName("RowNumber")
.master("local[2]").enableHiveSupport().getOrCreate()
/**
* 创建测试数据
*/
val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26")
val rdd = spark.sparkContext.parallelize(array).map{ row =>
val Array(id, name, age) = row.split(",")
Row(id, name, age.toInt)
}
val structType = new StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
/**
* 转化为df
*/
val df = spark.createDataFrame(rdd, structType)
df.show()
df.createOrReplaceTempView("technology")
/**
* 应用开窗函数row_number
* 注意:开窗函数只能在hiveContext下使用
*/
val result_1 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1")
result_1.show()
val result_2 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2")
result_2.show()
val result_3 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3")
result_3.show()
val result_4 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top > 3")
result_4.show()
}
}
三.结果【使用HiveContext】
1.初始数据
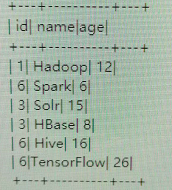
2.top<=1时
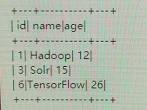
3.top<=2时

4.top<=3时
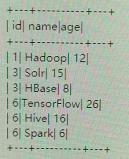
5.top>3时【分组中最大为3】
四.代码实现【不使用HiveContext】
package big.data.analyse.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* Created by zhen on 2019/7/6.
*/
object RowNumber {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口,不支持Hive
*/
val spark = SparkSession.builder().appName("RowNumber")
.master("local[2]").getOrCreate()
/**
* 创建测试数据
*/
val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26")
val rdd = spark.sparkContext.parallelize(array).map{ row =>
val Array(id, name, age) = row.split(",")
Row(id, name, age.toInt)
}
val structType = new StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
/**
* 转化为df
*/
val df = spark.createDataFrame(rdd, structType)
df.show()
df.createOrReplaceTempView("technology")
/**
* 应用开窗函数row_number
* 注意:开窗函数只能在hiveContext下使用
*/
val result_1 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1")
result_1.show()
val result_2 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2")
result_2.show()
val result_3 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3")
result_3.show()
val result_4 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top > 3")
result_4.show()
}
}
五.结果【不使用HiveContext】
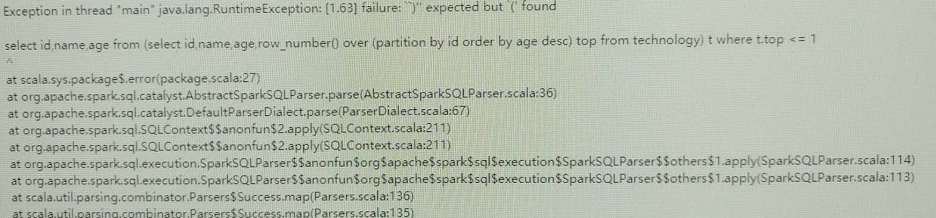
Spark之开窗函数的更多相关文章
- 【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一.前述 SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数. 开窗函数一般分组取topn时常用. 二.UDF和UDAF函数 1.UDF函数 java代码: Spar ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- spark开窗函数
源文件内容示例: http://bigdata.beiwang.cn/laoli http://bigdata.beiwang.cn/laoli http://bigdata.beiwang.cn/h ...
- 【Spark-SQL学习之三】 UDF、UDAF、开窗函数
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- SparkSQL开窗函数 row_number()
开始编写我们的统计逻辑,使用row_number()函数 先说明一下,row_number()开窗函数的作用 其实就是给每个分组的数据,按照其排序顺序,打上一个分组内行号 比如说,有一个分组20151 ...
- 开窗函数 First_Value 和 Last_Value
在Sql server 2012里面,开窗函数丰富了许多,其中带出了2个新的函数 First_Value 和 Last Value .现在来介绍一下这2个函数的应用场景. 首先分析一下First_Va ...
- Oracle开窗函数 over()(转)
copy文链接:http://blog.csdn.net/yjjm1990/article/details/7524167#,http://www.2cto.com/database/201402/2 ...
- oracle的分析函数over 及开窗函数
转:http://www.2cto.com/database/201310/249722.html oracle的分析函数over 及开窗函数 一:分析函数over Oracle从8.1.6开 ...
- 开窗函数 --over()
一个学习性任务:每个人有不同次数的成绩,统计出每个人的最高成绩. 这个问题应该还是相对简单,其实就用聚合函数就好了. select id,name,max(score) from Student gr ...
随机推荐
- HTML a标签链接 设置点击下载文件
通常情况下,为文件添加链接后,用户可以通过点击链接,直接将文件下载到本地,如下载 excel 表格等 <a href="/user/test/xxxx.excel">点 ...
- kotlin基础 字符串模板
${变量名} var tmp="字符串模板” print("今天学习${tmp}这个知识点")
- 【转载】 tf.ConfigProto和tf.GPUOptions用法总结
原文地址: https://blog.csdn.net/C_chuxin/article/details/84990176 -------------------------------------- ...
- VS2017 winform 打包 安装(使用 Microsoft Visual Studio 2017 Installer Project)
Microsoft Visual Studio 2017 Installer Projects SkyRiN发表于Coding+订阅 253 助力数字生态,云产品优惠大促 腾讯云促销,1核1G 99元 ...
- exe4j 打包jar包程序,inno setup complier打包所有
关于库: jar包中对于引用第三方库的话,需要再exe4j中引用. rxtx http://rxtx.qbang.org/wiki/index.php/Download
- 搜索排序的评价指标NDCG
refer: https://www.cnblogs.com/by-dream/p/9403984.html Out1 = SELECT QueryId, DocId, Rating, ROW_NUM ...
- 机器学习之挖掘melb_data.csv数据
mel_data.csv是关于melb地区房屋的数据 mel_data.csv import pandas as pd melbourne_file_path = "E:\data\Melb ...
- [转] spring-boot集成swagger2
经测,spring-boot版本使用1.5.2+时需使用springfox-swagger2版本2.5+(spring-boot 1.2 + springfox-swagger2 2.2 在未扫描ja ...
- IIS提速的几个优化
一.内存池右键高级设置 1.设置队列5000 2.设置固定回收时间 3.设置空闲时间Suspend 二.网站右键高级设置 1.启用预加载
- POJ 1251 Jungle Roads - C语言 - Kruskal算法
Description The Head Elder of the tropical island of Lagrishan has a problem. A burst of foreign aid ...