Spark之开窗函数
一.简介
开窗函数row_number()是按照某个字段分组,然后取另外一个字段排序的前几个值的函数,相当于分组topN。如果SQL语句里面使用了开窗函数,那么这个SQL语句必须使用HiveContext执行。
二.代码实践【使用HiveContext】
package big.data.analyse.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* Created by zhen on 2019/7/6.
*/
object RowNumber {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口,支持Hive
*/
val spark = SparkSession.builder().appName("RowNumber")
.master("local[2]").enableHiveSupport().getOrCreate()
/**
* 创建测试数据
*/
val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26")
val rdd = spark.sparkContext.parallelize(array).map{ row =>
val Array(id, name, age) = row.split(",")
Row(id, name, age.toInt)
}
val structType = new StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
/**
* 转化为df
*/
val df = spark.createDataFrame(rdd, structType)
df.show()
df.createOrReplaceTempView("technology")
/**
* 应用开窗函数row_number
* 注意:开窗函数只能在hiveContext下使用
*/
val result_1 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1")
result_1.show()
val result_2 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2")
result_2.show()
val result_3 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3")
result_3.show()
val result_4 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top > 3")
result_4.show()
}
}
三.结果【使用HiveContext】
1.初始数据
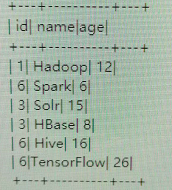
2.top<=1时
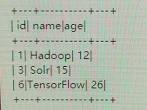
3.top<=2时

4.top<=3时
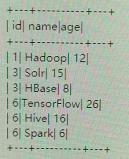
5.top>3时【分组中最大为3】
四.代码实现【不使用HiveContext】
package big.data.analyse.sparksql
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
/**
* Created by zhen on 2019/7/6.
*/
object RowNumber {
/**
* 设置日志级别
*/
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]) {
/**
* 创建spark入口,不支持Hive
*/
val spark = SparkSession.builder().appName("RowNumber")
.master("local[2]").getOrCreate()
/**
* 创建测试数据
*/
val array = Array("1,Hadoop,12","5,Spark,6","3,Solr,15","3,HBase,8","6,Hive,16","6,TensorFlow,26")
val rdd = spark.sparkContext.parallelize(array).map{ row =>
val Array(id, name, age) = row.split(",")
Row(id, name, age.toInt)
}
val structType = new StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
/**
* 转化为df
*/
val df = spark.createDataFrame(rdd, structType)
df.show()
df.createOrReplaceTempView("technology")
/**
* 应用开窗函数row_number
* 注意:开窗函数只能在hiveContext下使用
*/
val result_1 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 1")
result_1.show()
val result_2 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 2")
result_2.show()
val result_3 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top <= 3")
result_3.show()
val result_4 = spark.sql("select id,name,age from (select id,name,age," +
"row_number() over (partition by id order by age desc) top from technology) t where t.top > 3")
result_4.show()
}
}
五.结果【不使用HiveContext】
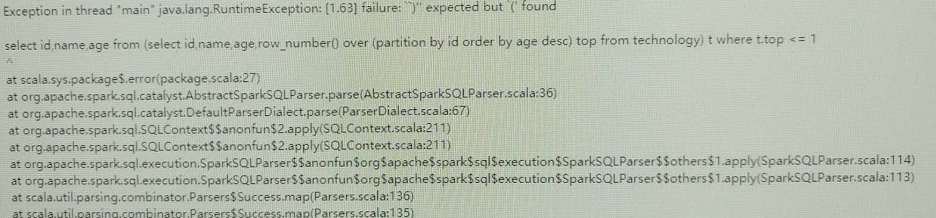
Spark之开窗函数的更多相关文章
- 【Spark篇】---SparkSQL中自定义UDF和UDAF,开窗函数的应用
一.前述 SparkSQL中的UDF相当于是1进1出,UDAF相当于是多进一出,类似于聚合函数. 开窗函数一般分组取topn时常用. 二.UDF和UDAF函数 1.UDF函数 java代码: Spar ...
- Spark(十三)SparkSQL的自定义函数UDF与开窗函数
一 自定义函数UDF 在Spark中,也支持Hive中的自定义函数.自定义函数大致可以分为三种: UDF(User-Defined-Function),即最基本的自定义函数,类似to_char,to_ ...
- spark开窗函数
源文件内容示例: http://bigdata.beiwang.cn/laoli http://bigdata.beiwang.cn/laoli http://bigdata.beiwang.cn/h ...
- 【Spark-SQL学习之三】 UDF、UDAF、开窗函数
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- SparkSQL开窗函数 row_number()
开始编写我们的统计逻辑,使用row_number()函数 先说明一下,row_number()开窗函数的作用 其实就是给每个分组的数据,按照其排序顺序,打上一个分组内行号 比如说,有一个分组20151 ...
- 开窗函数 First_Value 和 Last_Value
在Sql server 2012里面,开窗函数丰富了许多,其中带出了2个新的函数 First_Value 和 Last Value .现在来介绍一下这2个函数的应用场景. 首先分析一下First_Va ...
- Oracle开窗函数 over()(转)
copy文链接:http://blog.csdn.net/yjjm1990/article/details/7524167#,http://www.2cto.com/database/201402/2 ...
- oracle的分析函数over 及开窗函数
转:http://www.2cto.com/database/201310/249722.html oracle的分析函数over 及开窗函数 一:分析函数over Oracle从8.1.6开 ...
- 开窗函数 --over()
一个学习性任务:每个人有不同次数的成绩,统计出每个人的最高成绩. 这个问题应该还是相对简单,其实就用聚合函数就好了. select id,name,max(score) from Student gr ...
随机推荐
- sql 时间段交叉查询是否有交集
--双11活动结束时间大于当前服务器时间代表有效期的活动 --实现1 select * from ProdCar A where A.EndDate> GETDATE() and A.EndDa ...
- Python三角函数公式计算三角形的夹角
题目内容: 对于三角形,三边长分别为a, b, c,给定a和b之间的夹角C,则有:.编写程序,使得输入三角形的边a, b, c,可求得夹角C(角度值). 输入格式: 三条边a.b.c的长度值,每个值占 ...
- PAT-2019年冬季考试-甲级 7-3 Summit (25分) (邻接矩阵存储,直接暴力)
7-3 Summit (25分) A summit (峰会) is a meeting of heads of state or government. Arranging the rest ar ...
- jquery checkbox全选和取消
$("#allcheck").click(function(){ var allcheck=$('#allcheck').is(':checked'); $.each($(&quo ...
- java https post请求并忽略证书,参数放在body中
1 新建java类,作用是绕过证书用 package cn.smartercampus.core.util; import java.security.cert.CertificateExceptio ...
- Vue组件注册与数据传递
父子组件创建流程 1.构建父子组件 1.1 全局注册 (1)构建注册子组件 //构建子组件child var child = Vue.extend({ template: '<div>这是 ...
- Redis实现实时热点查询
Redis内存淘汰 定义: 指的是用户存储的一些键被可以被Redis主动地从实例中删除,从而产生读miss的情况 机制存在原因: Redis最常见的两种应用场景为缓存和持久存储 首先要明确的一个问题是 ...
- 【剑指offer】对称的二叉树
题目描述 请实现一个函数,用来判断一颗二叉树是不是对称的.注意,如果一个二叉树同此二叉树的镜像是同样的,定义其为对称的. 分析:从上到下直接遍历,利用栈或者队列暂存结点,注意结点的存和取都是成对的 c ...
- 复杂的sql参考(3)
SELECT apply.assets_code, apply.loan_apply_code, cust.cust_name, cust.id_no, cust.mobile, platform.p ...
- day19——包、logging日志
day19 包 文件夹下具有______init______.py文件就是一个包 方法 import 包.包.包 from 包.包.包 import 模块 需要在______init______.py ...